AWQ:面向端侧 LLM 压缩与加速的激活感知权重量化(Activation-aware Weight Quantization)
摘要¶
大型语言模型(LLM)已经改变了众多 AI 应用。端侧(on-device)LLM 变得愈发重要:在边缘设备本地运行 LLM 可以降低云端计算成本并保护用户隐私。然而,天文量级的模型规模与受限的硬件资源给部署带来显著挑战。我们提出激活感知权重量化(Activation-aware Weight Quantization, AWQ),一种面向硬件友好的 LLM 低比特仅权重量化方法。AWQ 的核心发现是:LLM 中并非所有权重同等重要——仅保护约 1% 的“显著(salient)”权重即可大幅降低量化误差。为识别显著权重通道,应参考激活(activation)分布而非权重本身。为避免硬件上低效的混合精度量化,我们从数学上推导出:放大显著通道能够降低量化误差。AWQ 采用一个等价变换对显著权重通道进行缩放以实现“保护”,缩放因子通过离线收集激活统计得到。AWQ 不依赖反向传播或重建,因此不会对校准集过拟合,能泛化到不同领域与模态。AWQ 在多种语言建模与领域基准(代码与数学)上优于现有工作。得益于更强泛化能力,AWQ 在指令微调语言模型上也能获得优异的量化效果,并且首次在多模态语言模型上实现良好量化表现。与 AWQ 同时,我们实现了 TinyChat:一个面向 4-bit 端侧 LLM/VLM 的高效、灵活推理框架。借助 kernel 融合与平台感知的权重打包(weight packing),TinyChat 在桌面与移动 GPU 上相对 HuggingFace 的 FP16 实现可获得 3× 以上速度提升,并使得在移动 GPU 上部署 70B Llama‑2 模型成为可能。
图 1:我们提出 AWQ(通用的 LLM 权重量化方法),并开发 TinyChat 将 4-bit 量化 LLM 部署到多种端侧平台,在桌面与移动 GPU 上相较 FP16 获得 3–4× 性能提升;同时我们还制造了一台 TinyChat 计算机(NVIDIA Jetson Orin Nano,8GB 显存,15W)。演示视频:https://youtu.be/z91a8DrfgEw
1 引言¶
将大型语言模型(LLM)直接部署到边缘设备至关重要。端侧使用能够避免将数据发送到云端服务器所带来的延迟,并使 LLM 可以离线运行,这对虚拟助手、聊天机器人和自动驾驶等实时应用尤为有利。维护与扩展集中式云基础设施的运营成本也可以因此降低。端侧 LLM 还能将敏感信息保留在本地,从而提升数据安全性并降低数据泄露风险。
LLM 基于 Transformer 架构,在多种基准上取得了令人瞩目的性能。然而,模型规模巨大导致服务成本高昂。例如,GPT‑3 拥有 175B 参数,FP16 下约为 350GB,而最新的 B200 GPU 仅有 192GB 显存,更不用说边缘设备。
对 LLM 做低比特权重量化能够显著降低端侧推理的显存占用,但实现并不容易。量化感知训练(QAT)由于训练成本高而不够高效;后训练量化(PTQ)在低比特场景下往往出现较大精度下降。最接近的工作是 GPTQ,其利用二阶信息进行误差补偿,但在重建过程中可能对校准集过拟合,导致在分布外领域上学到的特征被扭曲(见图 8),这对于作为“通用模型”的 LLM 是一个问题。
本文提出 AWQ:一种硬件友好的、低比特、仅权重量化方法。其基于一个观察:权重并非等价重要。只有极小的一部分(0.1%–1%)权重通道是“显著”的;跳过这些显著权重的量化可以显著降低量化损失(表 1)。识别显著通道的关键洞见是:尽管我们做的是仅权重量化,仍应参考激活分布而非权重分布——与更大激活幅度对应的权重通道更显著,因为它们处理更重要的特征。为避免硬件低效的混合精度实现,我们分析了权重量化误差并推导:放大显著通道可以降低其相对量化误差(式(2))。据此我们设计了逐通道缩放方法,在全权重量化约束下自动搜索最优缩放以最小化量化误差。AWQ 不依赖反向传播或重建,因此能在多领域、多模态上更好保持泛化能力,而不对校准集过拟合。
为将 AWQ 的理论显存收益转化为实际速度提升,我们设计了 TinyChat:一个高效推理框架,用于 4-bit 端侧 LLM 推理。TinyChat 通过 on-the-fly 反量化加速线性层,并通过高效 4-bit 权重打包与 kernel 融合减少推理开销(如中间 DRAM 访问与 kernel 启动开销),从而更好兑现 4-bit 权重量化带来的加速潜力(尽管硬件通常按字节对齐)。
实验表明:AWQ 在不同模型家族(如 LLaMA 与 OPT)与不同模型规模上均优于已有方法。得益于更强泛化能力,AWQ 也能在指令微调模型(如 Vicuna)上取得良好效果,并首次在多模态语言模型(如 OpenFlamingo)上表现出色。TinyChat 进一步将约 4× 的权重显存降低转化为实际速度提升:在桌面、笔记本与移动 GPU 上,相较 HuggingFace 的 FP16 实现平均可获得 3.2–3.3× 加速。此外,TinyChat 使得在单台 64GB Jetson Orin 上部署 Llama‑2‑70B 变得轻松;在仅 8GB 显存的 RTX 4070 笔记本 GPU 上也能以约 30 token/s 的交互速度运行 13B 级 LLM。AWQ 已被产业界与开源社区广泛采用(HuggingFace Transformers、NVIDIA TensorRT‑LLM、Microsoft DirectML、Google Vertex AI、Intel Neural Compressor、Amazon Sagemaker、AMD、FastChat、vLLM、LMDeploy 等),并使得 Falcon‑180B 可在单张 H200 GPU 上部署。
2 相关工作¶
2.1 模型量化方法¶
量化通过降低深度学习模型的比特精度来减少模型大小并加速推理。量化技术通常分为两类:
(1)量化感知训练(QAT):依赖反向传播更新量化权重。QAT 往往难以扩展到 LLM。
(2)后训练量化(PTQ):通常无需训练。因此,人们通常采用 PTQ 量化 LLM。
2.2 LLM 量化¶
LLM 量化常见两种设置:
(1)W8A8:激活与权重都量化到 INT8;
(2)低比特仅权重量化:例如 W4A16,仅将权重量化为低比特整数。
本文关注第二类设置,因为它既能降低硬件门槛(需要更小显存),也能加速 token 生成(缓解 memory‑bound 工作负载)。除基础的 round‑to‑nearest(RTN)外,GPTQ 与本文最为接近。但 GPTQ 的重建过程会对校准集过拟合,可能无法保持 LLM 在其他模态与领域的通用能力;此外,它在一些模型上还需要“重排(reordering)”技巧才能工作(如 LLaMA‑7B 与 OPT‑66B)。除面向通用硬件的量化外,SpAtten 提出在 softmax 计算中逐步增加比特数的渐进方法。
2.3 低比特 LLM 的系统支持¶
低比特量化 LLM 已是降低推理成本的热门方向,系统层面的支持对于实际加速同样关键。GPTQ 提供针对 OPT 的 INT3 kernel;GPTQ‑for‑LLaMA 在 Triton 帮助下扩展到 INT4 “重排量化” kernel。FlexGen、llama.cpp(https://github.com/ggerganov/llama.cpp)与 exllama(https://github.com/turboderp/exllama)进行 group‑wise INT4 量化以降低 I/O 成本与 offloading。FasterTransformer 支持 FP16×INT4 GEMM 的 per‑tensor 权重量化,但不支持 group 量化。LUT‑GEMM 使用查找表在 CUDA core 上进行按位计算。与本文同期的 MLC‑LLM(MLC‑Team, 2023)借助 TVM 后端在多种端侧 CPU/GPU 平台上也取得了强结果。
3 AWQ:激活感知权重量化¶
量化将浮点数映射为低比特整数,是减少 LLM 模型大小与推理成本的有效手段。本节先提出一种无需训练/回归、通过保护更“重要”权重来提升仅权重量化精度的方法;随后给出一种数据驱动的搜索策略,以降低量化误差(见图 2)。
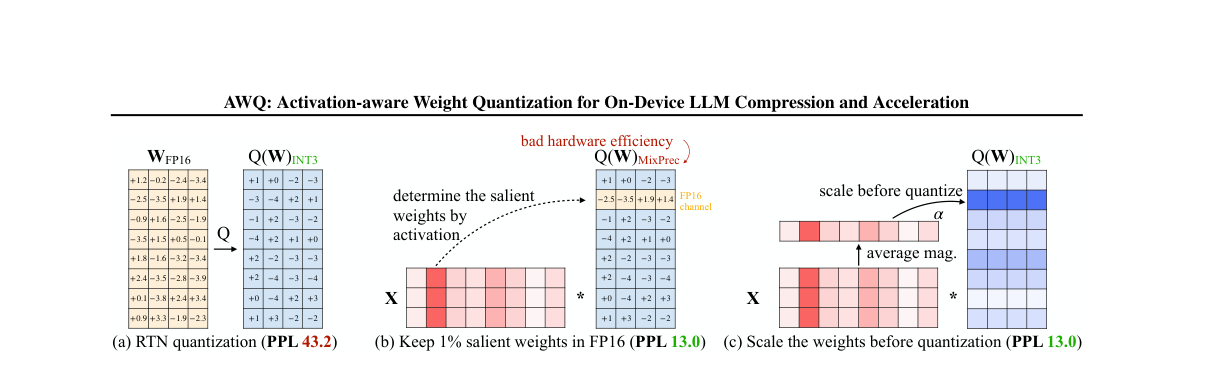
图 2:我们观察到可以基于激活分布找到 LLM 中约 1% 的显著权重(中)。将这些显著权重保持为 FP16 能显著提升量化性能(PPL 从 43.2 降到 13.0),但混合精度不利于硬件实现。AWQ(右)通过逐通道缩放在全权重量化下保护显著权重并降低量化误差。这里测量的是 OPT‑6.7B 在 INT3‑g128 下的困惑度(perplexity)。
3.1 通过保留 1% 显著权重改进 LLM 量化¶
我们观察到 LLM 的权重并非同等重要:存在极少量显著权重,它们对模型性能更关键。跳过这些显著权重的量化无需任何训练或回归,即可弥补量化损失带来的性能下降(见图 2(b))。为验证这一点,我们在表 1 中评估了:对 INT3 量化模型,保留一定比例的权重通道为 FP16(其余通道仍量化)对性能的影响。常见的权重重要性度量是权重幅值或 L2 范数。但我们发现,按权重范数选择通道(表 1“基于 W 的 FP16%”)几乎无法显著改善量化性能,与随机选择接近。相反,按激活幅值选择通道,即使仅保留 0.1%–1% 的通道为 FP16,也能显著提升性能。我们推测:幅值更大的输入特征通常更重要;保留与之对应的权重为 FP16 有助于保留这些特征,从而提升整体性能。
局限性。 尽管保留 0.1% 的权重为 FP16 在总比特数上几乎不增加模型大小,但混合精度数据类型会使系统实现困难。因此需要一种方法:在不实际保留 FP16 的情况下保护重要权重。
表 1:在 INT3‑g128 下,保留极小比例(0.1%–1%)权重通道为 FP16 可显著提升量化模型性能;仅当按激活分布选取通道时有效
| 模型 | FP16 PPL↓ | RTN PPL↓ | 基于激活选通道:0.1% | 1% | 3% | 基于权重选通道:0.1% | 1% | 3% | 随机:0.1% | 1% | 3% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OPT‑1.3B | 14.62 | 119.00 | 25.03 | 16.91 | 16.68 | 108.71 | 98.55 | 98.08 | 119.76 | 109.38 | 61.49 |
| OPT‑6.7B | 10.86 | 23.54 | 11.58 | 11.39 | 11.36 | 23.41 | 22.37 | 22.45 | 23.54 | 24.23 | 24.22 |
| OPT‑13B | 10.13 | 46.04 | 10.51 | 10.43 | 10.42 | 46.07 | 48.96 | 54.49 | 44.87 | 42.00 | 39.71 |
3.2 通过激活感知缩放保护显著权重¶
我们提出一种逐通道缩放方法来降低显著权重的量化误差,且不会遭遇混合精度带来的硬件低效。
量化误差分析¶
考虑一组/块权重 ,线性运算为 ,量化后的对应为 。量化函数定义为:
其中 为量化比特数, 为由绝对最大值确定的量化尺度(scale)。考虑某个权重元素 ,若将其乘以 并对输入 进行反向缩放,则得到 :
其中 为施加 后的新量化尺度。经验上:(1) 的期望误差(记为 )近似不变,可视作在 上均匀分布,平均误差约 0.25;(2)放大单个元素通常不会改变该组的最大值,因此 ;(3) 与 以 FP16 表示,可忽略其量化误差。于是式(1)(2)的量化误差可写为:
当 且 时,误差相对比例约为 ,因此显著权重的相对误差更小。
为验证该想法,我们将 OPT‑6.7B 中 1% 的显著通道乘以 ,并统计每个 group 的 变化(表 2)。缩放显著通道非常有效:困惑度从 (即 RTN)时的 23.54 提升到 时的 11.92。随着 增大, 发生改变的比例增大,显著通道的误差下降也更明显;但 过大时会增加非显著通道的误差(当 增大时,非显著通道的误差会被放大),从而损害整体精度。因此保护显著通道时也必须兼顾非显著通道。
表 2:将 1% 显著通道乘以 的统计量(OPT‑6.7B)
| 指标 | s=1 | s=1.25 | s=1.5 | s=2 | s=4 |
|---|---|---|---|---|---|
| 的比例 | 0% | 2.8% | 4.4% | 8.2% | 21.2% |
| 平均 | 1 | 1.005 | 1.013 | 1.038 | 1.213 |
| 平均 | 1 | 0.804 | 0.676 | 0.519 | 0.303 |
| WikiText‑2 PPL↓ | 23.54 | 12.87 | 12.48 | 11.92 | 12.36 |
自动搜索缩放因子¶
为同时考虑显著与非显著权重,我们对每个(输入)通道搜索一个缩放因子 ,使得量化后输出与原输出的差异最小:
其中 为权重量化函数(如 INT3/INT4,group size 128), 为 FP16 权重, 为从小规模校准集缓存的输入特征(我们从预训练数据中采样以避免对某一任务过拟合)。 为逐通道缩放; 通常可融合到前一算子中。由于 不可微,无法用标准反向传播直接优化;基于近似梯度的方法也可能出现不稳定收敛。我们进一步分析影响缩放选择的因素,从而定义更稳定的搜索空间。由于通道显著性由激活尺度决定(“activation-awareness”),我们使用如下形式:
其中 为激活的逐通道平均幅值, 为单个超参数,用于平衡显著与非显著通道保护强度。我们在区间 上做快速网格搜索(网格大小 20)选择最优 :0 表示不缩放,1 表示搜索空间中最激进的缩放。我们还结合权重裁剪(clipping)以最小化量化 MSE。表 3 给出了在 OPT、INT3‑g128 下的消融:AWQ 持续优于 RTN,并在硬件友好性更强的同时,达到与“1% FP16 混合精度”相近的精度。
表 3:AWQ 通过缩放保护显著权重并降低量化误差(OPT,INT3‑g128)
| 模型(Wiki PPL↓) | 1.3B | 2.7B | 6.7B | 13B | 30B |
|---|---|---|---|---|---|
| FP16 | 14.62 | 12.47 | 10.86 | 10.13 | 9.56 |
| RTN | 119.47 | 298.00 | 23.54 | 46.04 | 18.80 |
| 1% FP16(混合精度) | 16.91 | 13.69 | 11.39 | 10.43 | 9.85 |
| 仅缩放 | 18.63 | 14.94 | 11.92 | 10.80 | 10.32 |
| AWQ | 16.32 | 13.58 | 11.39 | 10.56 | 9.77 |
优势。 AWQ 不依赖回归或反向传播,这是许多 QAT 方法所必需的;对校准集依赖极小(仅测量逐通道平均幅值),从而降低过拟合风险(图 8)。因此 AWQ 量化所需数据更少,并能更好保留校准分布之外的知识(见第 5.3 节)。
4 TinyChat:将 AWQ 映射到端侧平台¶
AWQ 能显著缩小 LLM 规模,但将 W4A16 的理论显存收益转化为实际速度提升并非易事。诸如 SmoothQuant 的 W8A8 量化在存储与计算上使用相同精度,反量化可自然集成到 kernel 的 epilogue;而 W4A16 使用不同数据类型进行访存与计算,因此必须将反量化嵌入主计算循环以获得最佳性能,带来实现挑战。
为此,我们提出 TinyChat:一个轻量系统,用于 AWQ 模型推理。其前端基于 PyTorch,后端利用设备特定指令集(如 CUDA/PTX、Neon、AVX)。
4.1 为什么 AWQ 有助于加速端侧 LLM¶
为理解端侧量化 LLM 的加速机会,我们以 LLaMA‑7B 在 RTX 4090 上进行剖析(batch size=1,FP16,FasterTransformer)。
上下文阶段 vs 生成阶段延迟。 如图 3(a),生成 20 个 token 需 310ms,而处理含 200 token 的 prompt 仅需 10ms。端侧交互应用中,生成阶段通常比上下文阶段慢得多。
生成阶段为内存带宽瓶颈。 为加速生成阶段,我们做 roofline 分析(图 3(b))。4090 的峰值算力约 165 TFLOPS、显存带宽约 1TB/s,因此算术强度(FLOPs/Byte)小于 165 的工作负载为内存带宽受限。FP16 下端侧 LLM 的生成阶段算术强度约为 1,明显受限于带宽。由于模型 FLOPs 固定,提高峰值性能的方式只能是减少总内存流量;AWQ 将权重显存访问减少约 4 倍。
权重访问主导内存流量。 如图 3(c),权重访问的内存开销比激活访问高出数个数量级,因此仅权重量化对端侧 LLM 更有效。将权重量化为 4 bit 整数可将算术强度提升到约 4 FLOPs/Byte,对应约 4 TFLOPS 的上界(图 3(b))。

图 3:RTX 4090 上 Llama‑2‑7B 的瓶颈分析。(a)端侧应用中生成阶段远慢于上下文阶段;(b)生成阶段算术强度低且受带宽限制,W4A16 可将算术强度提升 4×;(c)权重加载远比激活加载昂贵,因此仅权重量化对端侧 LLM 更有效。
4.2 使用 TinyChat 部署 AWQ¶
我们已展示 4-bit 权重量化可带来 4× 的理论上界;TinyChat 旨在实现这一加速。在 GPU 上,我们聚焦实现注意力、LayerNorm 与线性投影等核心算子。其灵活前端便于定制与快速支持新模型。TinyChat 结合 4-bit AWQ,在不同 LLM 家族上相对 HuggingFace FP16 实现获得 3× 以上速度提升。CPU 侧则将计算图整体下沉到 C++ 以减少开销。
On-the-fly 权重反量化。 由于硬件通常不提供 INT4×FP16 的乘法指令,量化层需要先将 INT4 权重反量化到 FP16 再做矩阵计算。TinyChat 将反量化与矩阵乘(MM/MV)融合,避免将反量化后的权重写回 DRAM,从而减少中间访存。
SIMD 感知权重打包。 尽管融合反量化减少了中间 DRAM 访问,但反量化本身仍昂贵:反量化一个 4-bit 权重通常需要一次 shift、一次 bitwise AND、一次 FMA 缩放,而该权重在计算中仅参与一次 FMA。对偏好向量化的 SIMD CPU 更为不利。我们提出按设备 SIMD 寄存器位宽进行平台特定打包。图 4 展示 ARM NEON(128-bit SIMD)策略:每个寄存器容纳 32 个 4-bit 权重,并按 w0, w16, w1, w17, …, w15, w31 排列,使得运行时可用少量 SIMD 指令(AND/shift)解包全部 32 个权重,相对传统打包可达 1.2× 加速。一般而言,对 ‑bit SIMD 寄存器,相邻权重索引差约为 。GPU 侧,我们发现更高效的打包方式是将每 8 个权重打包为 w{0,2,4,6,1,3,5,7}。
Kernel 融合。 TinyChat 广泛应用 kernel 融合优化端侧推理:LayerNorm 将乘除与开方等操作融合为单 kernel;注意力层将 QKV 投影融合为单 kernel,并在注意力 kernel 内进行位置编码计算、KV cache 预分配与更新等。对一些前向实现效率较低的模型(如 Falcon 与 StarCoder)尤为有效。值得注意的是,在 4090 上单个 FP16 kernel 的计算时长可低至 0.01ms,与 kernel 启动开销同量级;因此减少 kernel 调用次数能直接带来速度提升。

图 4:面向 ARM NEON(128-bit SIMD) 的 SIMD 感知权重打包:离线对权重重排并按位宽打包,使运行时仅用少量 SIMD 位运算(AND/shift)与 mask 即可解包到字节序列,从而加速反量化与计算。
5 实验¶
5.1 设置¶
量化设置。 本文聚焦仅权重的 group 量化。此前工作表明 group 量化有助于改善精度/模型大小权衡。除非另有说明,我们统一使用 group size=128,并关注 INT4/INT3 设置,因为它们能在多数情况下保持 LLM 性能。AWQ 的校准集从 The Pile 中采样,以避免对特定下游任务过拟合;我们使用网格大小 20 搜索式(5)中的最优 。
模型。 我们在 LLaMA 与 OPT 家族上评测,并在 Vicuna、OpenFlamingo‑9B 与 LLaVA‑13B 等指令微调与多模态模型上验证泛化能力。
评测。 参考既有文献,我们主要在语言建模任务上评测量化模型(WikiText‑2 困惑度),因为困惑度可稳定反映 LLM 性能。
基线。 主要基线为 RTN;在 group size=128 下它本身已很强。我们也对比 GPTQ 及其带“重排技巧”的更新版本 GPTQ‑R。其他依赖反向传播更新量化权重的方法(如 AdaRound、BRECQ)不易扩展到大模型,且通常不优于 GPTQ,因此不纳入比较。
5.2 评测结果¶
LLaMA / Llama‑2 模型结果¶
我们在表 4 中给出 LLaMA 与 Llama‑2 在不同规模(7B–70B)与不同 bit‑precision(INT3/INT4,g128)下的困惑度。AWQ 在各设定下均优于 RTN,并在多数情况下优于 GPTQ(无论是否重排)。
表 4:AWQ 在 LLaMA/Llama‑2 上优于 RTN 与 GPTQ(PPL↓)
| 设置 | 7B | 13B | 70B | 7B | 13B | 30B | 65B |
|---|---|---|---|---|---|---|---|
| Llama‑2 | LLaMA | ||||||
| FP16 | – | 5.47 | 4.88 | 3.32 | 5.68 | 5.09 | 4.10 |
| INT3‑g128 RTN | 6.66 | 5.52 | 3.98 | 7.01 | 5.88 | 4.88 | 4.24 |
| INT3‑g128 GPTQ | 6.43 | 5.48 | 3.88 | 8.81 | 5.66 | 4.88 | 4.17 |
| INT3‑g128 GPTQ‑R | 6.42 | 5.41 | 3.86 | 6.53 | 5.64 | 4.74 | 4.21 |
| INT3‑g128 AWQ | 6.24 | 5.32 | 3.74 | 6.35 | 5.52 | 4.61 | 3.95 |
| INT4‑g128 RTN | 5.73 | 4.98 | 3.46 | 5.96 | 5.25 | 4.23 | 3.67 |
| INT4‑g128 GPTQ | 5.69 | 4.98 | 3.42 | 6.22 | 5.23 | 4.24 | 3.66 |
| INT4‑g128 GPTQ‑R | 5.63 | 4.99 | 3.43 | 5.83 | 5.20 | 4.22 | 3.66 |
| INT4‑g128 AWQ | 5.60 | 4.97 | 3.41 | 5.78 | 5.19 | 4.21 | 3.62 |
Mistral / Mixtral 模型结果¶
我们也在表 5 中评测 Mistral 与 Mixtral(MoE)模型。结果表明 AWQ 在包含 GQA 与 MoE 等结构的不同架构上同样有效。
表 5:AWQ 在 Mistral/Mixtral 上的 WikiText‑2 PPL↓
| 模型 | FP16 | INT4‑g128 | INT3‑g128 |
|---|---|---|---|
| Mixtral‑8×7B‑Instruct‑v0.1 | 5.94 | 6.05 | 6.52 |
| Mistral‑7B‑Instruct‑v0.2 | 4.14 | 4.30 | 4.83 |
指令微调模型量化¶
指令微调能显著提升模型可用性。我们在 Vicuna 上用 GPT‑4 评测协议对比量化模型与 FP16(80 个问题,考虑输入顺序,合计 160 次试验)。如图 5,AWQ 在 7B 与 13B 上均能相对 RTN/GPTQ 改善 INT3‑g128 的表现,体现出对指令微调模型的泛化。
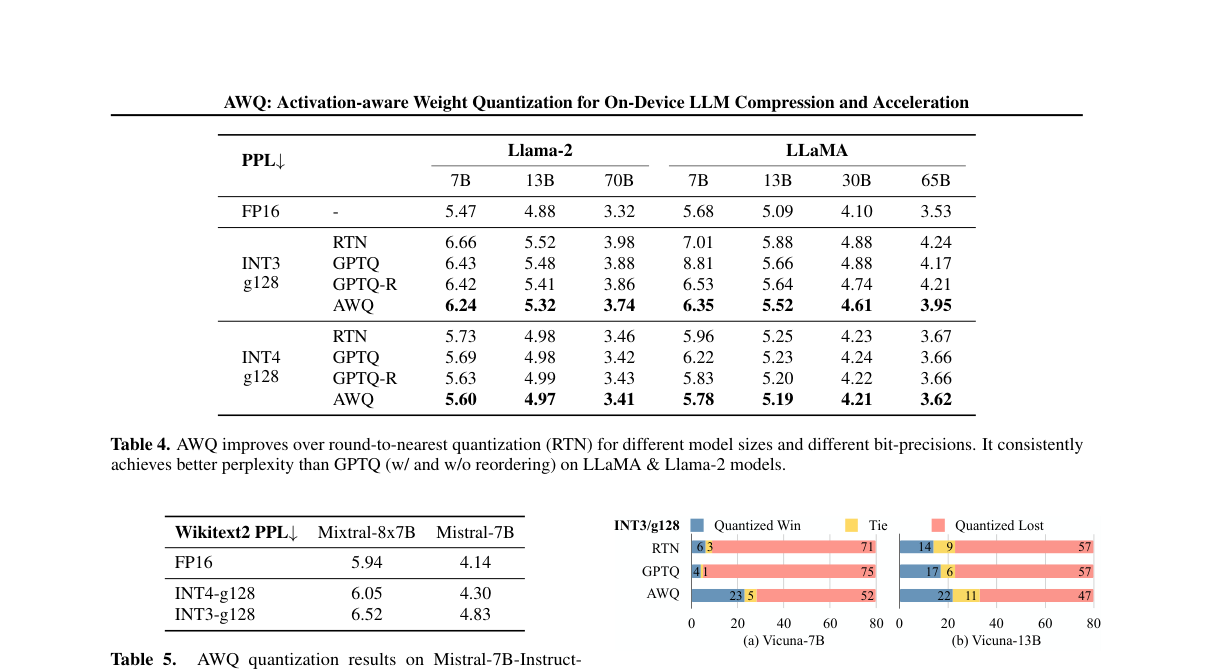
图 5:按 GPT‑4 评测协议比较 INT3‑g128 量化 Vicuna 与 FP16(更多“胜”表示更好)。AWQ 在 7B/13B 上均优于 RTN 与 GPTQ。
多模态模型量化¶
大型多模态/视觉语言模型(VLM)可基于图像/视频条件生成文本。由于 AWQ 不易对校准集过拟合,可直接用于 VLM 量化。我们在 OpenFlamingo‑9B(仅量化语言部分)上评测 COCO Captioning,在不同 few‑shot 设置下统计 5k 样本的平均性能(表 6)。AWQ 在 zero‑shot 与 various few‑shot 设置下均优于 RTN/GPTQ,将 32‑shot 下的退化从 4.57 降至 1.17(INT4‑g128),在 4× 模型压缩下几乎无损。我们还在 VILA 上评测 11 个视觉语言基准(表 7),展示“无损量化”。
表 6:OpenFlamingo‑9B 在 COCO Captioning 上的 CIDEr↑(不同 in‑context shots)
| 设置 | 0‑shot | 4‑shot | 8‑shot | 16‑shot | 32‑shot | Δ(32‑shot) |
|---|---|---|---|---|---|---|
| FP16 | – | 63.73 | 72.18 | 76.95 | 79.74 | 81.70 |
| INT4‑g128 RTN | 60.24 | 68.07 | 72.46 | 74.09 | 77.13 | −4.57 |
| INT4‑g128 GPTQ | 59.72 | 67.68 | 72.53 | 74.98 | 74.98 | −6.72 |
| INT4‑g128 AWQ | 62.57 | 71.02 | 74.75 | 78.23 | 80.53 | −1.17 |
| INT3‑g128 RTN | 46.07 | 55.13 | 60.46 | 63.21 | 64.79 | −16.91 |
| INT3‑g128 GPTQ | 29.84 | 50.77 | 56.55 | 60.54 | 64.77 | −16.93 |
| INT3‑g128 AWQ | 56.33 | 64.73 | 68.79 | 72.86 | 74.47 | −7.23 |
表 7:VILA‑7B/13B 在 11 个视觉语言基准上的 INT4‑g128 结果(Accuracy↑)
原论文为节省版面使用缩写;下表保持数值与列名一致。
模型 VQAv2 GQA VizWiz SQA‑I VQA‑T POPE MME MMB SEED llava‑bench MM‑Vet VILA‑7B 80.3 63.1 59.6 68.0 62.6 86.3 1489.4 69.8 61.7 75.2 35.1 VILA‑7B‑AWQ 80.1 63.0 57.8 68.0 61.9 85.3 1486.3 68.8 61.3 75.8 35.9 VILA‑13B 80.5 63.6 63.1 70.5 64.0 86.3 1553.6 73.8 62.8 78.3 42.6 VILA‑13B‑AWQ 80.4 63.6 63.0 71.2 63.5 87.0 1552.9 73.6 62.2 77.6 42.0
视觉推理与定性示例¶
图 6 给出 LLaVA‑13B 的视觉推理示例:AWQ 相对 RTN 能给出更合理的回答。图 7 展示 OpenFlamingo‑9B 在 COCO captioning(4‑shot, INT4‑g128)上的定性结果:AWQ 明显改善 caption 质量。原论文用颜色标注正确/错误文本,这里仅保留图示。

图 6:LLaVA‑13B 的视觉推理示例。AWQ(INT4‑g128)相对 RTN 给出更合理回答。

图 7:OpenFlamingo‑9B 在 COCO captioning(4‑shot, INT4‑g128)上的定性对比。AWQ 显著改善 caption 质量。
编程与数学任务¶
为评估复杂生成任务,我们在 MBPP 与 GSM8K 上测试 AWQ。表 8 显示:在 CodeLlama‑7B‑Instruct‑hf(MBPP)与 Llama‑2(GSM8K)上,AWQ 优于 RTN 与 GPTQ;在 INT4‑g128 下,AWQ 与原 FP16 性能几乎一致。
表 8:INT4‑g128 下的 MBPP / GSM8K 结果
| 任务 | 模型 | 指标 | FP16 | RTN | GPTQ | AWQ |
|---|---|---|---|---|---|---|
| MBPP | CodeLlama‑7B‑Instruct‑hf | pass@1 | 38.53 | 37.51 | 31.97 | 40.64 |
| MBPP | CodeLlama‑7B‑Instruct‑hf | pass@10 | 49.77 | 48.49 | 44.75 | 49.25 |
| GSM8K | Llama‑2‑7B | accuracy | 13.87 | 11.07 | 12.13 | 13.57 |
| GSM8K | Llama‑2‑13B | accuracy | 26.16 | 21.23 | 24.26 | 25.25 |
| GSM8K | Llama‑2‑70B | accuracy | 56.41 | 53.98 | 56.03 | 56.40 |
极低比特量化与 GPTQ 的正交性¶
我们进一步在 INT2 设置下量化 LLM 以适配更小显存(表 9)。RTN 在该设置下几乎完全失效,而 AWQ 结合 GPTQ 能进一步改善 INT2 性能,表明两者正交可叠加。
表 9:AWQ 与 GPTQ 可组合,在 INT2‑g64 下进一步缩小性能差距(OPT,WikiText‑2 PPL↓)
| 模型 | 1.3B | 2.7B | 6.7B | 13B | 30B |
|---|---|---|---|---|---|
| FP16 | 14.62 | 12.47 | 10.86 | 10.13 | 9.56 |
| RTN | 10476 | 193210 | 7622 | 17564 | 8170 |
| GPTQ | 46.67 | 28.15 | 16.65 | 16.74 | 11.75 |
| AWQ + GPTQ | 35.71 | 25.70 | 15.71 | 13.25 | 11.38 |
5.3 数据效率与泛化¶
更高的数据效率。 由于不依赖回归/反向传播,AWQ 仅需测量逐通道平均激活尺度,因而对校准数据更节省。图 8(a)表明:在 OPT‑6.7B、INT3‑g128 下,AWQ 用比 GPTQ 少 10× 的校准序列即可达到更好的困惑度(16 sequences vs 192 sequences,每条 2048 tokens)。
对校准分布更鲁棒。 我们比较不同校准分布对量化性能的影响(图 8(b))。从 The Pile 选取 PubMed Abstracts 与 Enron Emails 两个子集,分别作为校准集并在两者上评测。总体上校准与评测分布一致最好;但当校准与评测分布不同时,AWQ 仅使困惑度上升 0.5–0.6,而 GPTQ 上升 2.3–4.9,说明 AWQ 更鲁棒。

图 8:左:AWQ 用更小校准集即可达到更好量化效果;右:当校准集分布与评测分布不一致时,AWQ 的困惑度增幅显著小于 GPTQ。
5.4 速度提升评测¶
图 9 展示 TinyChat 的系统加速:其优化了量化线性层,也优化了不量化的层。我们按 exllama 的协议在 RTX 4090 与 Jetson Orin 上做 batch=1 基准(固定 prompt 长度 4 tokens,每次生成 200 tokens,取中位数延迟)。
结果如图 9(a):在 4090 上,TinyChat 相对 HuggingFace FP16 可在 Llama‑2、MPT、Falcon 上获得 2.7–3.9× 加速。以 Llama‑2‑7B 为例,我们通过 FP16 kernel 融合将速度从 52 提升到 62 tokens/s,并在此更强 FP16 基线上进一步获得 3.1× 的量化线性 kernel 加速。对于 Falcon‑7B,官方实现推理时 KV cache 支持不佳导致显著变慢,我们的 FP16 优化带来 1.6× 加速。在仅 8GB 显存的 RTX 4070 笔记本 GPU 上,我们仍能以 33 tokens/s 运行 Llama‑2‑13B,而 FP16 甚至无法容纳 7B。表 10 进一步给出 VILA 的加速结果:TinyChat 在 A100/4090/Orin 上对 VILA‑7B/13B 均带来约 3× 加速。

图 9:TinyChat 将 W4A16 的理论显存降低转化为可度量的速度提升:在 4090 与 Orin 上分别可达 3.9× 与 3.5×(相对 HuggingFace FP16)。并使 8GB 笔记本 GPU 上部署 Llama‑2‑13B 成为可能。
表 10:TinyChat 使 VILA 在多平台上实现无缝部署与显著吞吐提升(Throughput↑)
| 模型 | 精度 | A100 | 4090 | Orin |
|---|---|---|---|---|
| VILA‑7B | FP16 | 81.6 | 58.5 | 11.5 |
| VILA‑7B‑AWQ | W4A16 | 155.3 | 168.1 | 35.6 |
| VILA‑13B | FP16 | 48.5 | OOM | 6.1 |
| VILA‑13B‑AWQ | W4A16 | 102.1 | 99.0 | 17.5 |
与其他系统对比¶
我们在图 10 中将 TinyChat 与 AutoGPTQ、llama.cpp、exllama 对比:在 Jetson Orin 上运行 4-bit 量化 Llama 模型时,TinyChat 可提供 1.2–3.0× 加速;同时它支持更广泛的通用/代码类 LLM(如 StarCoder、StableCode、Mistral、Falcon),并对这些工作负载相对 AutoGPTQ 一致获得显著加速。TinyChat 也能在 Raspberry Pi 4B 等极度受限设备上运行,7B 模型约 0.7 tokens/s。

图 10:TinyChat 在 Jetson Orin 上相对现有系统的速度对比,并展示其在 Raspberry Pi 4 上的可用性。
6 结论¶
本文提出 AWQ:一种简单有效的低比特仅权重量化方法,用于 LLM 压缩。基于“权重重要性不均”的观察,AWQ 通过逐通道缩放降低显著权重的量化损失。AWQ 不对校准集过拟合,能在多领域与多模态上保持 LLM 的通用能力;其在语言建模上优于已有方法,并可用于指令微调与多模态模型。TinyChat 系统进一步将 AWQ 带来的理论显存节省转化为实际加速:在桌面与移动 GPU 上相对 HuggingFace FP16 实现获得 3.2–3.3× 的测得加速,从而推动端侧 LLM 部署的普及。