初学 CUDA 编程时,我们通常使用 nvcc 命令编译得到一个可执行文件,就像我们使用 gcc 或 g++ 编译 C/C++ 代码一样。gcc 或 g++ 在编译 C/C++ 代码时,会经历预处理、编译、汇编和链接等多个阶段,最终生成可执行文件。类似地,nvcc 是一个专门用于编译 CUDA 代码的编译器驱动程序,它在幕后调用了多个工具来处理 CUDA 代码的编译和链接过程。nvcc 的说明文档对编译链接流程做了介绍,并详细说明了各种选项的作用。
为了更好地理解 CUDA 编译链接流程,在阅读了官方文档后,我对编译链接流程进行了实践,比如观察编译中间文件的格式和内容,以此加深理解。本文将分享我对 CUDA 编译链接流程的理解,以及一些实践经验。本文可以看作是对官方文档的补充。
CUDA 编译链接流程概述¶
下面这幅图展示了 CUDA 编译链接的整体流程:
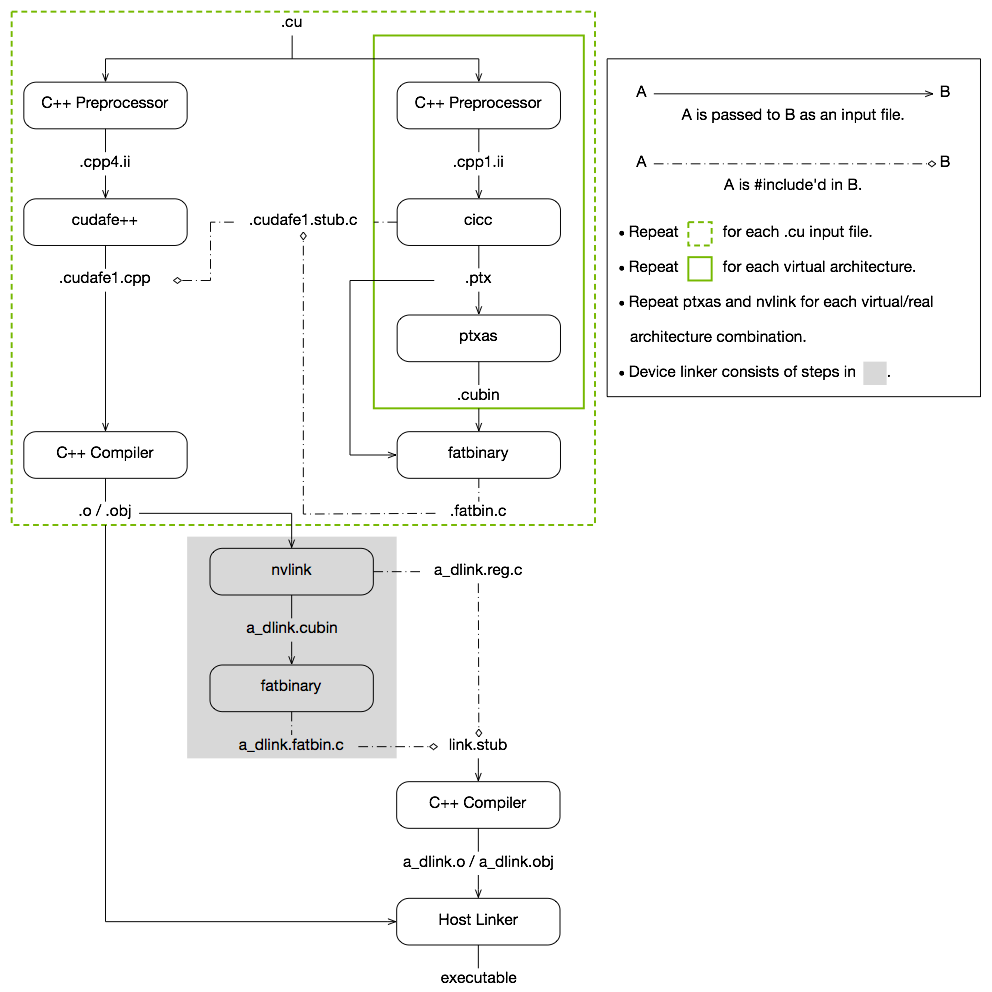
CUDA 编译链接流程主要包括以下几个阶段:
1. 分离主机代码和设备代码
CUDA 代码包含主机代码(运行在 CPU 上的代码)和设备代码(运行在 GPU 上的代码)两部分,nvcc 会将这两部分代码分离开来,分别进行处理。
2. 编译设备代码
对于设备代码,nvcc 调用专门的 CUDA 设备编译器(如 cicc)和汇编器(如 ptxas)将其编译为 PTX 代码或机器码。编译完成后,nvcc 会创建一些辅助的启动函数,这些函数内部负责调用 CUDA 运行时库中的函数来启动和管理设备代码的执行。经过这一步处理后,就不存在设备代码和主机代码的混合问题了。所有代码均符合 C/C++ 语法。
3. 编译主机代码
主机代码会经过预处理,然后调用 nvcc 的前端(如 cudafe++)进行处理,此阶段会将 CUDA 启动语法糖 kernel<<<...>>>(...) 转换为对辅助启动函数的调用,处理完成后,主机代码也全部符合 C/C++ 语法。接下来,执行调用系统的 C/C++ 编译器(如 gcc 或 g++)对主机代码进行编译。
4. 链接生成可执行文件
最后,nvcc 会调用系统的链接器(如 ld)将目标文件链接生成可执行文件。编译得到的可执行文件中,包含了编译后的设备代码,在执行时由第二步生成的辅助启动函数负责加载和启动设备代码。
以上就是 CUDA 编译链接的大致流程,整体来看就是将 CUDA 代码抽出来,然后使用专门的工具链对设备代码进行编译处理,同时对主机代码做必要的转换,使用 CUDA 的运行时库来启动设备代码。但其中有很多细节需要深入理解,下面我将结合具体的例子来详细介绍每个步骤的执行过程。
CUDA 编译链接流程详解¶
为了更好地理解上述流程,我使用 nvcc 来编译一个简单的 CUDA 程序,并使用 -v 选项观察编译过程中的详细信息。此外,使用 --keep 选项保留中间文件,便于分析每个阶段生成的文件内容。
本文使用的所有代码和中间文件均可以在 labs/compile 中找到。
我们来看一个简单的 CUDA 程序 add.cu:
__global__ void vector_add(const float *A, const float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
const int N = 1024;
float *A, *B, *C;
cudaMallocManaged(&A, N * sizeof(float));
cudaMallocManaged(&B, N * sizeof(float));
cudaMallocManaged(&C, N * sizeof(float));
vector_add<<<(N + 255) / 256, 256>>>(A, B, C, N);
cudaDeviceSynchronize();
return 0;
}__global__ void vector_add(const float *A, const float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
const int N = 1024;
float *A, *B, *C;
cudaMallocManaged(&A, N * sizeof(float));
cudaMallocManaged(&B, N * sizeof(float));
cudaMallocManaged(&C, N * sizeof(float));
vector_add<<<(N + 255) / 256, 256>>>(A, B, C, N);
cudaDeviceSynchronize();
return 0;
}编译命令如下:
nvcc -v --keep add.cu -o addnvcc -v --keep add.cu -o add命令的输出显示了各个编译阶段的详细信息:
$ _NVVM_BRANCH_=nvvm
$ _SPACE_=
$ _CUDART_=cudart
$ _HERE_=/usr/local/cuda-13.0/bin
$ _THERE_=/usr/local/cuda-13.0/bin
$ _TARGET_SIZE_=
$ _TARGET_DIR_=
$ _TARGET_DIR_=targets/x86_64-linux
$ TOP=/usr/local/cuda-13.0/bin/..
$ CICC_PATH=/usr/local/cuda-13.0/bin/../nvvm/bin
$ NVVMIR_LIBRARY_DIR=/usr/local/cuda-13.0/bin/../nvvm/libdevice
$ LD_LIBRARY_PATH=/usr/local/cuda-13.0/bin/../lib:/usr/local/cuda-13.0/lib:/usr/local/cuda-13.0/lib64:/usr/local/cuda-13.0/lib:/usr/local/cuda-13.0/lib64:
$ PATH=/usr/local/cuda-13.0/bin/../nvvm/bin:/usr/local/cuda-13.0/bin:/usr/local/cuda-13.0/bin:/home/wangyu/.vscode-server/data/User/globalStorage/github.copilot-chat/debugCommand:/home/wangyu/.vscode-server/data/User/globalStorage/github.copilot-chat/copilotCli:/home/wangyu/.scode-server/cli/servers/Stable-994fd12f8d3a5aa16f17d42c041e5809167e845a/server/bin/remote-cli:/home/wangyu/.nvm/versions/node/v24.11.1/bin:/usr/local/cuda-13.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
$ INCLUDES="-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include"
$ SYSTEM_INCLUDES="-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl"
$ LIBRARIES= "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib"
$ CUDAFE_FLAGS=
$ PTXAS_FLAGS=
$ rm add_dlink.reg.c
$ gcc -D__CUDA_ARCH_LIST__=750 -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp4.ii"
$ cudafe++ --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed --m64 --parse_templates --gen_c_file_name "add.cudafe1.cpp" --stub_file_name "add.cudafe1.stub.c" --gen_module_id_file --module_id_file_name "add.module_id" "add.cpp4.ii"
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed -arch compute_75 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.cudafe1.c" --stub_file_name "add.cudafe1.stub.c" --gen_device_file_name "add.cudafe1.gpu" "add.cpp1.ii" -o "add.ptx"
$ ptxas -arch=sm_75 -m64 "add.ptx" -o "add.sm_75.cubin"
$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=75,file=add.sm_75.cubin" "--image3=kind=ptx,sm=75,file=add.ptx" --embedded-fatbin="add.fatbin.c"
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -m64 "add.cudafe1.cpp" -o "add.o"
$ nvlink -m64 --arch=sm_75 --register-link-binaries="add_dlink.reg.c" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -cpu-arch=X86_64 "add.o" -lcudadevrt -o "add_dlink.sm_75.cubin" --host-ccbin "gcc"
$ fatbinary --create="add_dlink.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " -link "--image3=kind=elf,sm=75,file=add_dlink.sm_75.cubin" --embedded-fatbin="add_dlink.fatbin.c"
$ gcc -D__CUDA_ARCH_LIST__=750 -c -x c++ -DFATBINFILE="\"add_dlink.fatbin.c\"" -DREGISTERLINKBINARYFILE="\"add_dlink.reg.c\"" -I. -D__NV_EXTRA_INITIALIZATION= -D__NV_EXTRA_FINALIZATION= -D__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__ -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -m64 "/usr/local/cuda-13.0/bin/crt/link.stub" -o "add_dlink.o"
$ g++ -D__CUDA_ARCH_LIST__=750 -m64 -Wl,--start-group "add_dlink.o" "add.o" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group -o "add"$ _NVVM_BRANCH_=nvvm
$ _SPACE_=
$ _CUDART_=cudart
$ _HERE_=/usr/local/cuda-13.0/bin
$ _THERE_=/usr/local/cuda-13.0/bin
$ _TARGET_SIZE_=
$ _TARGET_DIR_=
$ _TARGET_DIR_=targets/x86_64-linux
$ TOP=/usr/local/cuda-13.0/bin/..
$ CICC_PATH=/usr/local/cuda-13.0/bin/../nvvm/bin
$ NVVMIR_LIBRARY_DIR=/usr/local/cuda-13.0/bin/../nvvm/libdevice
$ LD_LIBRARY_PATH=/usr/local/cuda-13.0/bin/../lib:/usr/local/cuda-13.0/lib:/usr/local/cuda-13.0/lib64:/usr/local/cuda-13.0/lib:/usr/local/cuda-13.0/lib64:
$ PATH=/usr/local/cuda-13.0/bin/../nvvm/bin:/usr/local/cuda-13.0/bin:/usr/local/cuda-13.0/bin:/home/wangyu/.vscode-server/data/User/globalStorage/github.copilot-chat/debugCommand:/home/wangyu/.vscode-server/data/User/globalStorage/github.copilot-chat/copilotCli:/home/wangyu/.scode-server/cli/servers/Stable-994fd12f8d3a5aa16f17d42c041e5809167e845a/server/bin/remote-cli:/home/wangyu/.nvm/versions/node/v24.11.1/bin:/usr/local/cuda-13.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
$ INCLUDES="-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include"
$ SYSTEM_INCLUDES="-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl"
$ LIBRARIES= "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib"
$ CUDAFE_FLAGS=
$ PTXAS_FLAGS=
$ rm add_dlink.reg.c
$ gcc -D__CUDA_ARCH_LIST__=750 -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp4.ii"
$ cudafe++ --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed --m64 --parse_templates --gen_c_file_name "add.cudafe1.cpp" --stub_file_name "add.cudafe1.stub.c" --gen_module_id_file --module_id_file_name "add.module_id" "add.cpp4.ii"
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed -arch compute_75 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.cudafe1.c" --stub_file_name "add.cudafe1.stub.c" --gen_device_file_name "add.cudafe1.gpu" "add.cpp1.ii" -o "add.ptx"
$ ptxas -arch=sm_75 -m64 "add.ptx" -o "add.sm_75.cubin"
$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=75,file=add.sm_75.cubin" "--image3=kind=ptx,sm=75,file=add.ptx" --embedded-fatbin="add.fatbin.c"
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -m64 "add.cudafe1.cpp" -o "add.o"
$ nvlink -m64 --arch=sm_75 --register-link-binaries="add_dlink.reg.c" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -cpu-arch=X86_64 "add.o" -lcudadevrt -o "add_dlink.sm_75.cubin" --host-ccbin "gcc"
$ fatbinary --create="add_dlink.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " -link "--image3=kind=elf,sm=75,file=add_dlink.sm_75.cubin" --embedded-fatbin="add_dlink.fatbin.c"
$ gcc -D__CUDA_ARCH_LIST__=750 -c -x c++ -DFATBINFILE="\"add_dlink.fatbin.c\"" -DREGISTERLINKBINARYFILE="\"add_dlink.reg.c\"" -I. -D__NV_EXTRA_INITIALIZATION= -D__NV_EXTRA_FINALIZATION= -D__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__ -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -m64 "/usr/local/cuda-13.0/bin/crt/link.stub" -o "add_dlink.o"
$ g++ -D__CUDA_ARCH_LIST__=750 -m64 -Wl,--start-group "add_dlink.o" "add.o" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group -o "add"可以看到,nvcc 实际上调用了多个工具来完成编译链接过程,包括 gcc、cudafe++、cicc、ptxas、fatbinary 和 nvlink 等。每个工具负责不同的任务,共同完成了 CUDA 代码的编译和链接。
编译完成后,在当前目录下生成了多个中间文件:
.
├── add
├── add.cpp1.ii
├── add.cpp4.ii
├── add.cu
├── add.cudafe1.c
├── add.cudafe1.cpp
├── add.cudafe1.gpu
├── add.cudafe1.stub.c
├── add_dlink.fatbin
├── add_dlink.fatbin.c
├── add_dlink.o
├── add_dlink.reg.c
├── add_dlink.sm_75.cubin
├── add.fatbin
├── add.fatbin.c
├── add.module_id
├── add.o
├── add.ptx
└── add.sm_75.cubin
1 directory, 19 files.
├── add
├── add.cpp1.ii
├── add.cpp4.ii
├── add.cu
├── add.cudafe1.c
├── add.cudafe1.cpp
├── add.cudafe1.gpu
├── add.cudafe1.stub.c
├── add_dlink.fatbin
├── add_dlink.fatbin.c
├── add_dlink.o
├── add_dlink.reg.c
├── add_dlink.sm_75.cubin
├── add.fatbin
├── add.fatbin.c
├── add.module_id
├── add.o
├── add.ptx
└── add.sm_75.cubin
1 directory, 19 files主机代码的预处理¶
第一步是调用 gcc 进行预处理:
$ gcc -D__CUDA_ARCH_LIST__=750 -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp4.ii"$ gcc -D__CUDA_ARCH_LIST__=750 -E -x c++ -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp4.ii"这个命令使用了 -E 选项,表示只进行预处理,不进行编译。生成的 add.cpp4.ii 文件包含了预处理后的代码。这一步容易理解,就是将源代码中的宏展开,处理 #include 指令等。
主机代码的 CUDA 语法转换¶
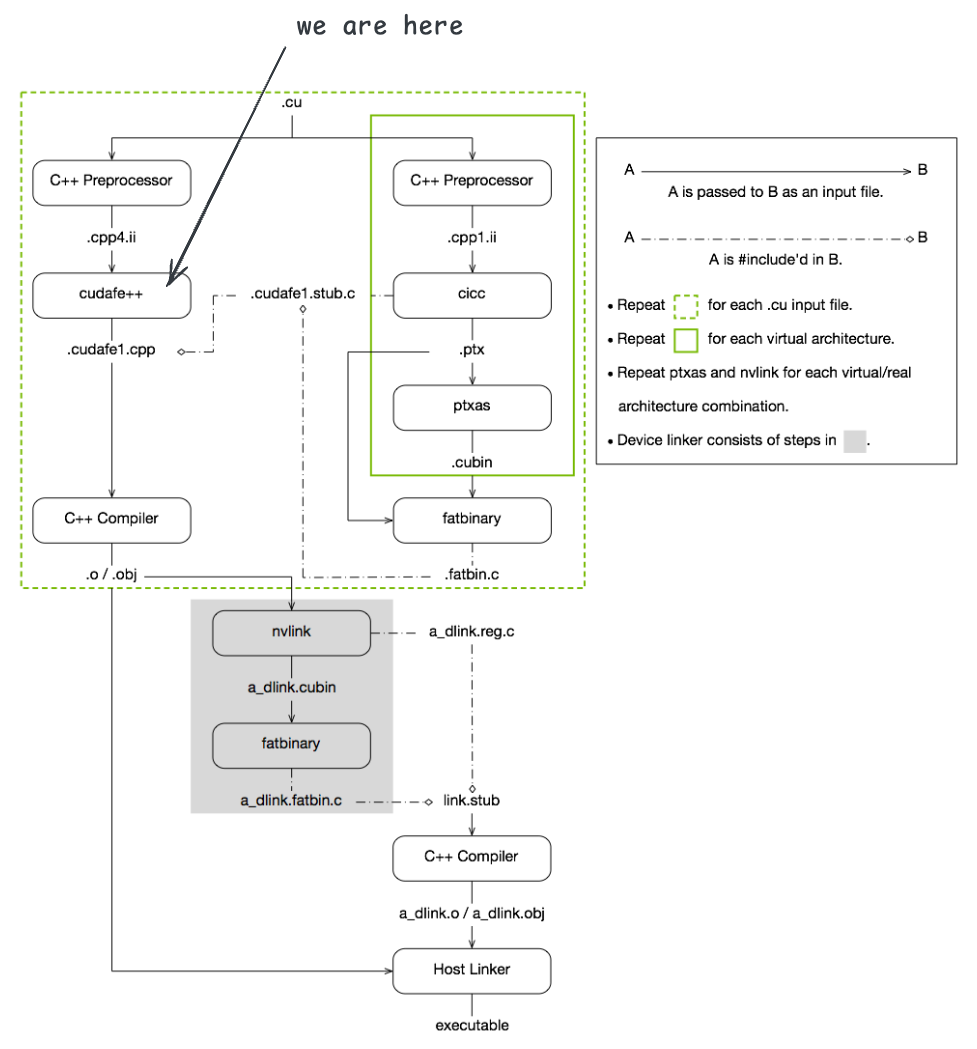
形如 kernel<<<...>>>(...) 这样的语法 C/C++ 编译器是无法识别的。nvcc 使用 cudafe++ 工具对预处理后的代码进行处理,将 kernel 启动语法糖转换为符合 C++ 语法的代码。
$ cudafe++ --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed --m64 --parse_templates --gen_c_file_name "add.cudafe1.cpp" --stub_file_name "add.cudafe1.stub.c" --gen_module_id_file --module_id_file_name "add.module_id" "add.cpp4.ii"$ cudafe++ --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed --m64 --parse_templates --gen_c_file_name "add.cudafe1.cpp" --stub_file_name "add.cudafe1.stub.c" --gen_module_id_file --module_id_file_name "add.module_id" "add.cpp4.ii"第二步使用 cudafe++ 工具对预处理后的文件进行处理,生成 add.cudafe1.cpp 和 add.cudafe1.stub.c 文件。add.cudafe1.cpp 文件包含了主机代码的转换结果,add.cudafe1.stub.c 文件包含了 kernel 的启动辅助代码。
在 add.cudafe1.cpp 文件中,排除掉预处理后包含的大量头文件内容后,我们前面写的 CUDA 代码被转换为如下形式:
__attribute__((visibility("hidden"))) void vector_add(const float* A, const float* B, float* C, int N);
#if 0
{
int idx = ((__device_builtin_variable_blockIdx.x) * (__device_builtin_variable_blockDim.x)) + (__device_builtin_variable_threadIdx.x);
if (idx < N) {
(C[idx]) = ((A[idx]) + (B[idx]));
}
}
#endif
int main() {
const int N = 1024;
float *A, *B, *C;
cudaMallocManaged(&A, N * sizeof(float));
cudaMallocManaged(&B, N * sizeof(float));
cudaMallocManaged(&C, N * sizeof(float));
(__cudaPushCallConfiguration((N + 255) / 256, 256)) ? (void)0 : vector_add(A, B, C, N);
cudaDeviceSynchronize();
return 0;
}
#include "add.cudafe1.stub.c"__attribute__((visibility("hidden"))) void vector_add(const float* A, const float* B, float* C, int N);
#if 0
{
int idx = ((__device_builtin_variable_blockIdx.x) * (__device_builtin_variable_blockDim.x)) + (__device_builtin_variable_threadIdx.x);
if (idx < N) {
(C[idx]) = ((A[idx]) + (B[idx]));
}
}
#endif
int main() {
const int N = 1024;
float *A, *B, *C;
cudaMallocManaged(&A, N * sizeof(float));
cudaMallocManaged(&B, N * sizeof(float));
cudaMallocManaged(&C, N * sizeof(float));
(__cudaPushCallConfiguration((N + 255) / 256, 256)) ? (void)0 : vector_add(A, B, C, N);
cudaDeviceSynchronize();
return 0;
}
#include "add.cudafe1.stub.c"可以看到 kernel 函数 vector_add 的函数体被包裹在 #if 0 ... #endif 中,表示该部分代码不会被编译执行。原来的函数定义被转换为一个函数声明,并添加了 __attribute__((visibility("hidden"))) 属性以隐藏符号。
在 main 函数中,kernel 的启动语法糖 vector_add<<<...>>>(...) 被转换为对 __cudaPushCallConfiguration 函数的调用,这个函数负责设置 kernel 的执行配置(如 grid 和 block 的维度)。如果配置成功,则调用 vector_add 函数。
最后,add.cudafe1.stub.c 文件被包含进来,可以想象,这个文件中定义了 vector_add 函数的具体实现。这个 add.cudafe1.stub.c 文件是由 CUDA 的编译器 cicc 生成的,负责封装设备代码的启动逻辑,我们后面会详细分析这个文件的内容。
设备代码的预处理¶
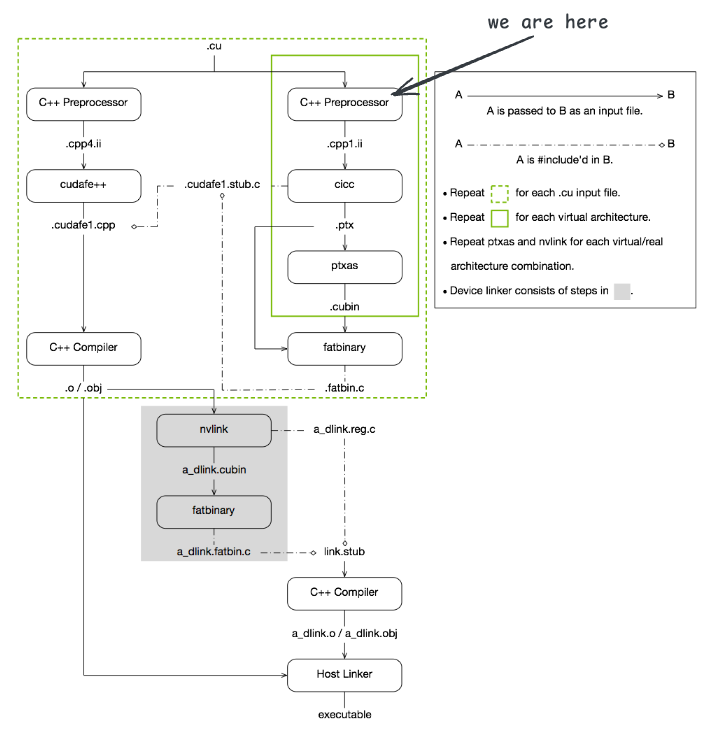
nvcc 在编译设备代码时,首先会进行预处理。观察 nvcc 的执行日志可以看到,第三步是调用 gcc 进行预处理,生成 add.cpp1.ii 文件:
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp1.ii"$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.cpp1.ii"此处设置了多个宏定义,特别是 -D__CUDA_ARCH__=750,表示目标 GPU 架构是 compute capability 7.5。在编写 kernel 代码时,可以使用 __CUDA_ARCH__ 宏来编写与特定架构相关的代码。预处理后的设备代码会根据目标架构进行条件编译。
编译设备代码¶
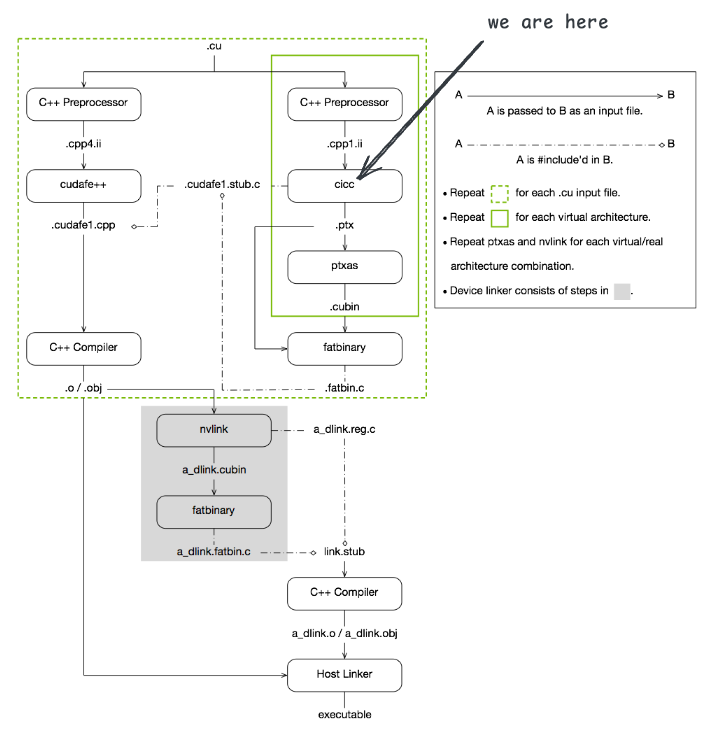
经过预处理后的设备代码会被传递给 cicc(CUDA Intermediate Code Compiler)进行编译,生成 PTX 代码。观察 nvcc 的执行日志可以看到,第四步是调用 cicc 进行编译,生成 add.ptx 文件:
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed -arch compute_75 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.cudafe1.c" --stub_file_name "add.cudafe1.stub.c" --gen_device_file_name "add.cudafe1.gpu" "add.cpp1.ii" -o "add.ptx"$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/add/add.cu" --allow_managed -arch compute_75 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.cudafe1.c" --stub_file_name "add.cudafe1.stub.c" --gen_device_file_name "add.cudafe1.gpu" "add.cpp1.ii" -o "add.ptx"在这一步中,cicc 会将设备代码编译为 PTX 代码,生成的 PTX 代码存储在 add.ptx 文件中。PTX 是一种中间表示形式,可以被进一步编译为特定 GPU 架构的机器码。同时生成包含 vector_add 函数的具体实现的 add.cudafe1.stub.c 文件。在这个过程中,还生成了 add.cudafe1.gpu 文件,包含了设备代码。
下面我们重点分析 add.cudafe1.stub.c 文件的内容,这个文件定义了 vector_add 函数,其内容经过格式化,并去掉无关信息后如下所示:
#include "add.fatbin.c"
#include "crt/host_runtime.h"
static void __sti____cudaRegisterAll(void) __attribute__((__constructor__));
__attribute__((visibility("hidden"))) void
__device_stub__Z10vector_addPKfS0_Pfi(const float *__par0, const float *__par1,
float *__par2, int __par3) {
__cudaLaunchPrologue(4);
__cudaSetupArgSimple(__par0, 0UL);
__cudaSetupArgSimple(__par1, 8UL);
__cudaSetupArgSimple(__par2, 16UL);
__cudaSetupArgSimple(__par3, 24UL);
__cudaLaunch(((char *)((void (*)(const float *, const float *, float *,
int))vector_add)),
0U);
}
void vector_add(const float *__cuda_0, const float *__cuda_1, float *__cuda_2, int __cuda_3) {
__device_stub__Z10vector_addPKfS0_Pfi(__cuda_0, __cuda_1, __cuda_2, __cuda_3);
}
static void __nv_cudaEntityRegisterCallback(void **__T0) {
__nv_dummy_param_ref(__T0);
__nv_save_fatbinhandle_for_managed_rt(__T0);
__cudaRegisterEntry(
__T0, ((void (*)(const float *, const float *, float *, int))vector_add),
_Z10vector_addPKfS0_Pfi, (-1));
}
static void __sti____cudaRegisterAll(void) {
__cudaRegisterBinary(__nv_cudaEntityRegisterCallback);
}#include "add.fatbin.c"
#include "crt/host_runtime.h"
static void __sti____cudaRegisterAll(void) __attribute__((__constructor__));
__attribute__((visibility("hidden"))) void
__device_stub__Z10vector_addPKfS0_Pfi(const float *__par0, const float *__par1,
float *__par2, int __par3) {
__cudaLaunchPrologue(4);
__cudaSetupArgSimple(__par0, 0UL);
__cudaSetupArgSimple(__par1, 8UL);
__cudaSetupArgSimple(__par2, 16UL);
__cudaSetupArgSimple(__par3, 24UL);
__cudaLaunch(((char *)((void (*)(const float *, const float *, float *,
int))vector_add)),
0U);
}
void vector_add(const float *__cuda_0, const float *__cuda_1, float *__cuda_2, int __cuda_3) {
__device_stub__Z10vector_addPKfS0_Pfi(__cuda_0, __cuda_1, __cuda_2, __cuda_3);
}
static void __nv_cudaEntityRegisterCallback(void **__T0) {
__nv_dummy_param_ref(__T0);
__nv_save_fatbinhandle_for_managed_rt(__T0);
__cudaRegisterEntry(
__T0, ((void (*)(const float *, const float *, float *, int))vector_add),
_Z10vector_addPKfS0_Pfi, (-1));
}
static void __sti____cudaRegisterAll(void) {
__cudaRegisterBinary(__nv_cudaEntityRegisterCallback);
}你可以在 https://github.com/w4096/cuda/tree/main/labs/compile/add 找到完整的中间文件。
在 vector_add 函数中,直接调用了 __device_stub__Z10vector_addPKfS0_Pfi 函数,在 __device_stub__Z10vector_addPKfS0_Pfi 函数中,使用了一些 CUDA 运行时库中定义的宏函数来设置 kernel 的参数,并启动 kernel 的执行:
__device_stub__Z10vector_addPKfS0_Pfi(const float *__par0, const float *__par1,
float *__par2, int __par3) {
__cudaLaunchPrologue(4);
__cudaSetupArgSimple(__par0, 0UL);
__cudaSetupArgSimple(__par1, 8UL);
__cudaSetupArgSimple(__par2, 16UL);
__cudaSetupArgSimple(__par3, 24UL);
__cudaLaunch(((char *)((void (*)(const float *, const float *, float *,
int))vector_add)),
0U);
}__device_stub__Z10vector_addPKfS0_Pfi(const float *__par0, const float *__par1,
float *__par2, int __par3) {
__cudaLaunchPrologue(4);
__cudaSetupArgSimple(__par0, 0UL);
__cudaSetupArgSimple(__par1, 8UL);
__cudaSetupArgSimple(__par2, 16UL);
__cudaSetupArgSimple(__par3, 24UL);
__cudaLaunch(((char *)((void (*)(const float *, const float *, float *,
int))vector_add)),
0U);
}其中使用到的几个宏定义在 crt/host_runtime.h 中,因不想偏离主题,此处不再展开讲解。你可以在 /usr/local/cuda/include/crt/host_runtime.h 文件中查看这些宏的具体实现,或参见 labs/compile/launch.cpp。
接下来需要考虑的一个问题是,vector_add kernel 函数的具体实现在哪里?
继续看 add.cudafe1.stub.c 后面的内容,此处定义了一个用 __constructor__ 修饰的函数,表示该函数会在程序启动时自动执行。
static void __sti____cudaRegisterAll(void) __attribute__((__constructor__));
static void __nv_cudaEntityRegisterCallback(void **__T0) {
__nv_dummy_param_ref(__T0);
__nv_save_fatbinhandle_for_managed_rt(__T0);
__cudaRegisterEntry(
__T0, ((void (*)(const float *, const float *, float *, int))vector_add),
_Z10vector_addPKfS0_Pfi, (-1));
}
static void __sti____cudaRegisterAll(void) {
__cudaRegisterBinary(__nv_cudaEntityRegisterCallback);
}static void __sti____cudaRegisterAll(void) __attribute__((__constructor__));
static void __nv_cudaEntityRegisterCallback(void **__T0) {
__nv_dummy_param_ref(__T0);
__nv_save_fatbinhandle_for_managed_rt(__T0);
__cudaRegisterEntry(
__T0, ((void (*)(const float *, const float *, float *, int))vector_add),
_Z10vector_addPKfS0_Pfi, (-1));
}
static void __sti____cudaRegisterAll(void) {
__cudaRegisterBinary(__nv_cudaEntityRegisterCallback);
}在这个函数内部,调用了 __cudaRegisterBinary 函数来注册设备代码,最终将 vector_add 映射到了 _Z10vector_addPKfS0_Pfi 符号上。这个符号对应了设备代码中 vector_add kernel 函数的实现。在该文件的开头部分,还包含了 add.fatbin.c 文件,这个文件中包含了设备代码的二进制数据,我们后面会详细分析这个文件的内容。
汇编 PTX 指令¶
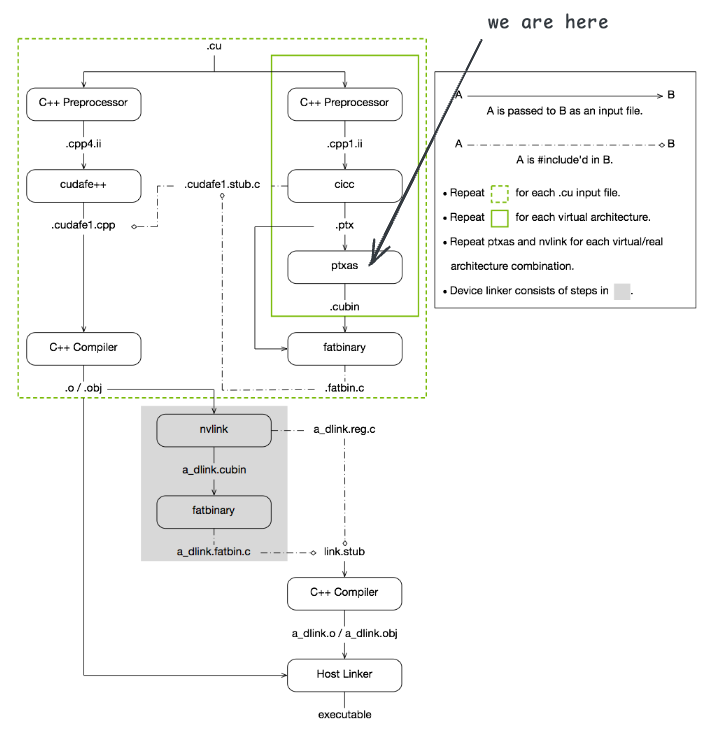
观察 nvcc 的执行日志可以看到,紧接着调用 ptxas 进行汇编,生成 add.sm_75.cubin 文件:
$ ptxas -arch=sm_75 -m64 "add.ptx" -o "add.sm_75.cubin"$ ptxas -arch=sm_75 -m64 "add.ptx" -o "add.sm_75.cubin"我们在启动 nvcc 时没有指定目标架构,默认会使用 compute capability 7.5(sm_75)。生成的 add.sm_75.cubin 文件是特定于 sm_75 架构的机器码文件,包含了设备代码的二进制表示。
该文件是 ELF 格式的文件,可以使用 readelf 命令查看其头信息:
readelf -h ./add.sm_75.cubin
ELF Header:
Magic: 7f 45 4c 46 02 01 01 41 08 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: <unknown: 41>
ABI Version: 8
Type: EXEC (Executable file)
Machine: NVIDIA CUDA architecture
Version: 0x1
Entry point address: 0x0
Start of program headers: 3072 (bytes into file)
Start of section headers: 2176 (bytes into file)
Flags: 0x6004b04
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 3
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 1readelf -h ./add.sm_75.cubin
ELF Header:
Magic: 7f 45 4c 46 02 01 01 41 08 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: <unknown: 41>
ABI Version: 8
Type: EXEC (Executable file)
Machine: NVIDIA CUDA architecture
Version: 0x1
Entry point address: 0x0
Start of program headers: 3072 (bytes into file)
Start of section headers: 2176 (bytes into file)
Flags: 0x6004b04
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 3
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 1可以看到该文件的类型是可执行文件(EXEC),机器类型是 NVIDIA CUDA 架构。使用 cuobjdump 命令可以反汇编该文件,查看其中的汇编指令:
$ cuobjdump -sass ./add.sm_75.cubin
code for sm_75
.target sm_75
Function : _Z10vector_addPKfS0_Pfi
.headerflags @"EF_CUDA_SM75 EF_CUDA_VIRTUAL_SM(EF_CUDA_SM75)"
/*0000*/ MOV R1, c[0x0][0x28] ; /* 0x00000a0000017a02 */
/* 0x000fe40000000f00 */
/*0010*/ S2R R6, SR_CTAID.X ; /* 0x0000000000067919 */
/* 0x000e280000002500 */
/*0020*/ S2R R3, SR_TID.X ; /* 0x0000000000037919 */
/* 0x000e240000002100 */
/*0030*/ IMAD R6, R6, c[0x0][0x0], R3 ; /* 0x0000000006067a24 */
/* 0x001fca00078e0203 */
/*0040*/ ISETP.GE.AND P0, PT, R6, c[0x0][0x178], PT ; /* 0x00005e0006007a0c */
/* 0x000fd80003f06270 */
/*0050*/ @P0 EXIT ; /* 0x000000000000094d */
/* 0x000fea0003800000 */
/*0060*/ MOV R7, 0x4 ; /* 0x0000000400077802 */
/* 0x000fca0000000f00 */
/*0070*/ IMAD.WIDE R4, R6, R7, c[0x0][0x168] ; /* 0x00005a0006047625 */
/* 0x000fc800078e0207 */
/*0080*/ IMAD.WIDE R2, R6, R7, c[0x0][0x160] ; /* 0x0000580006027625 */
/* 0x000fc800078e0207 */
/*0090*/ LDG.E.SYS R4, [R4] ; /* 0x0000000004047381 */
/* 0x000ea800001ee900 */
/*00a0*/ LDG.E.SYS R3, [R2] ; /* 0x0000000002037381 */
/* 0x000ea200001ee900 */
/*00b0*/ IMAD.WIDE R6, R6, R7, c[0x0][0x170] ; /* 0x00005c0006067625 */
/* 0x000fc800078e0207 */
/*00c0*/ FADD R9, R4, R3 ; /* 0x0000000304097221 */
/* 0x004fd00000000000 */
/*00d0*/ STG.E.SYS [R6], R9 ; /* 0x0000000906007386 */
/* 0x000fe2000010e900 */
/*00e0*/ EXIT ; /* 0x000000000000794d */
/* 0x000fea0003800000 */
/*00f0*/ BRA 0xf0; /* 0xfffffff000007947 */
/* 0x000fc0000383ffff *$ cuobjdump -sass ./add.sm_75.cubin
code for sm_75
.target sm_75
Function : _Z10vector_addPKfS0_Pfi
.headerflags @"EF_CUDA_SM75 EF_CUDA_VIRTUAL_SM(EF_CUDA_SM75)"
/*0000*/ MOV R1, c[0x0][0x28] ; /* 0x00000a0000017a02 */
/* 0x000fe40000000f00 */
/*0010*/ S2R R6, SR_CTAID.X ; /* 0x0000000000067919 */
/* 0x000e280000002500 */
/*0020*/ S2R R3, SR_TID.X ; /* 0x0000000000037919 */
/* 0x000e240000002100 */
/*0030*/ IMAD R6, R6, c[0x0][0x0], R3 ; /* 0x0000000006067a24 */
/* 0x001fca00078e0203 */
/*0040*/ ISETP.GE.AND P0, PT, R6, c[0x0][0x178], PT ; /* 0x00005e0006007a0c */
/* 0x000fd80003f06270 */
/*0050*/ @P0 EXIT ; /* 0x000000000000094d */
/* 0x000fea0003800000 */
/*0060*/ MOV R7, 0x4 ; /* 0x0000000400077802 */
/* 0x000fca0000000f00 */
/*0070*/ IMAD.WIDE R4, R6, R7, c[0x0][0x168] ; /* 0x00005a0006047625 */
/* 0x000fc800078e0207 */
/*0080*/ IMAD.WIDE R2, R6, R7, c[0x0][0x160] ; /* 0x0000580006027625 */
/* 0x000fc800078e0207 */
/*0090*/ LDG.E.SYS R4, [R4] ; /* 0x0000000004047381 */
/* 0x000ea800001ee900 */
/*00a0*/ LDG.E.SYS R3, [R2] ; /* 0x0000000002037381 */
/* 0x000ea200001ee900 */
/*00b0*/ IMAD.WIDE R6, R6, R7, c[0x0][0x170] ; /* 0x00005c0006067625 */
/* 0x000fc800078e0207 */
/*00c0*/ FADD R9, R4, R3 ; /* 0x0000000304097221 */
/* 0x004fd00000000000 */
/*00d0*/ STG.E.SYS [R6], R9 ; /* 0x0000000906007386 */
/* 0x000fe2000010e900 */
/*00e0*/ EXIT ; /* 0x000000000000794d */
/* 0x000fea0003800000 */
/*00f0*/ BRA 0xf0; /* 0xfffffff000007947 */
/* 0x000fc0000383ffff *生成 fatbin 并嵌入 C/C++ 文件¶
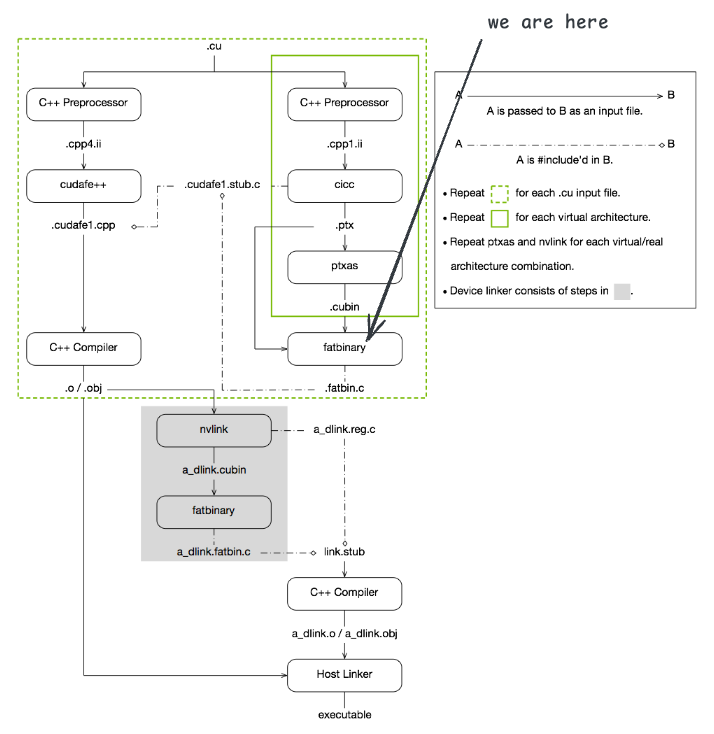
观察 nvcc 的执行日志可以看到,随后调用了 fatbinary,并生成了 add.fatbin.c 和 add.fatbin 文件:
$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=75,file=add.sm_75.cubin" "--image3=kind=ptx,sm=75,file=add.ptx" --embedded-fatbin="add.fatbin.c"$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=75,file=add.sm_75.cubin" "--image3=kind=ptx,sm=75,file=add.ptx" --embedded-fatbin="add.fatbin.c"fatbin 是一种包含多种设备代码格式的容器格式。命令行中 "--image3=kind=elf,sm=75,file=add.sm_75.cubin" "--image3=kind=ptx,sm=75,file=add.ptx" 表示其中包含了两种格式的设备代码:ELF 格式的机器码和 PTX 格式的中间代码。
生成的 add.fatbin 文件是二进制格式的 fatbin 文件,而 add.fatbin.c 文件是一个 C 语言源文件,包含了 fatbin 文件的二进制数据,以便后续编译器可以将其嵌入到最终的可执行文件中。
add.fatbin.c 文件的内容如下:
#ifndef __SKIP_INTERNAL_FATBINARY_HEADERS
#include "fatbinary_section.h"
#endif
#define __CUDAFATBINSECTION ".nvFatBinSegment"
#define __CUDAFATBINDATASECTION ".nv_fatbin"
asm(
".section .nv_fatbin, \"a\"\n"
".align 8\n"
"fatbinData:\n"
".quad 0x00100001ba55ed50,0x0000000000000ed0,0x0000004001010002,0x0000000000000ca8\n"
".quad 0x0000000000000000,0x0000004b00010008,0x0000000000000000,0x0000000000000011\n"
".quad 0x0000000000000000,0x0000000000000000,0x41010102464c457f,0x0000000000000008\n"
".quad 0x0000000100be0002,0x0000000000000000,0x0000000000000c00,0x0000000000000880\n"
".quad 0x0038004006004b04,0x0001000e00400003,0x7472747368732e00,0x747274732e006261\n"
// ... 省略大量二进制数据 ...
".text\n");
static const __fatBinC_Wrapper_t __fatDeviceText __attribute__ ((aligned (8))) __attribute__ ((section (__CUDAFATBINSECTION)))=
{ 0x466243b1, 1, fatbinData, 0 };#ifndef __SKIP_INTERNAL_FATBINARY_HEADERS
#include "fatbinary_section.h"
#endif
#define __CUDAFATBINSECTION ".nvFatBinSegment"
#define __CUDAFATBINDATASECTION ".nv_fatbin"
asm(
".section .nv_fatbin, \"a\"\n"
".align 8\n"
"fatbinData:\n"
".quad 0x00100001ba55ed50,0x0000000000000ed0,0x0000004001010002,0x0000000000000ca8\n"
".quad 0x0000000000000000,0x0000004b00010008,0x0000000000000000,0x0000000000000011\n"
".quad 0x0000000000000000,0x0000000000000000,0x41010102464c457f,0x0000000000000008\n"
".quad 0x0000000100be0002,0x0000000000000000,0x0000000000000c00,0x0000000000000880\n"
".quad 0x0038004006004b04,0x0001000e00400003,0x7472747368732e00,0x747274732e006261\n"
// ... 省略大量二进制数据 ...
".text\n");
static const __fatBinC_Wrapper_t __fatDeviceText __attribute__ ((aligned (8))) __attribute__ ((section (__CUDAFATBINSECTION)))=
{ 0x466243b1, 1, fatbinData, 0 };可见,add.fatbin.c 文件使用了汇编指令将设备代码以二进制数据的形式存储在了 .nv_fatbin 段中。并定义了一个 __fatDeviceText 变量,指向这些二进制数据。
你可以使用 readelf 命令可以查看可执行文件中的 .nv_fatbin 段,你会发现该段中存储的内容就包含前面生成的 cubin 文件和 PTX 代码。
如果在编译的时候指定 --no-compress 选项,就可以在 fatbin 中看到未压缩的 PTX 代码:
$ nvcc -v --keep add.cu -o add --no-compress
$ hexdump -C ./add.fatbin$ nvcc -v --keep add.cu -o add --no-compress
$ hexdump -C ./add.fatbin虽然 fatbin 的具体格式较为复杂,但通过 hexdump 可以看到其中包含 ELF 文件的头部信息和 PTX 代码:
$ hexdump -C add.fatbin
00000000 50 ed 55 ba 01 00 10 00 48 11 00 00 00 00 00 00 |P.U.....H.......|
00000010 02 00 01 01 40 00 00 00 a8 0c 00 00 00 00 00 00 |....@...........|
00000020 00 00 00 00 00 00 00 00 08 00 01 00 4b 00 00 00 |............K...|
00000030 00 00 00 00 00 00 00 00 11 00 00 00 00 00 00 00 |................|
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 7f 45 4c 46 02 01 01 41 08 00 00 00 00 00 00 00 |.ELF...A........|
00000060 02 00 be 00 01 00 00 00 00 00 00 00 00 00 00 00 |................|
00000070 00 0c 00 00 00 00 00 00 80 08 00 00 00 00 00 00 |................|
00000080 04 4b 00 06 40 00 38 00 03 00 40 00 0e 00 01 00 |.K..@.8...@.....|
00000090 00 2e 73 68 73 74 72 74 61 62 00 2e 73 74 72 74 |..shstrtab..strt|
000000a0 61 62 00 2e 73 79 6d 74 61 62 00 2e 73 79 6d 74 |ab..symtab..symt|
000000b0 61 62 5f 73 68 6e 64 78 00 2e 6e 6f 74 65 2e 6e |ab_shndx..note.n|
000000c0 76 2e 74 6b 69 6e 66 6f 00 2e 6e 6f 74 65 2e 6e |v.tkinfo..note.n|
000000d0 76 2e 63 75 69 6e 66 6f 00 2e 6e 76 2e 69 6e 66 |v.cuinfo..nv.inf|
000000e0 6f 00 2e 74 65 78 74 2e 5f 5a 31 30 76 65 63 74 |o..text._Z10vect|
000000f0 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 66 69 00 |or_addPKfS0_Pfi.|
00000100 2e 6e 76 2e 69 6e 66 6f 2e 5f 5a 31 30 76 65 63 |.nv.info._Z10vec|
00000110 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 66 69 |tor_addPKfS0_Pfi|
00000120 00 2e 6e 76 2e 73 68 61 72 65 64 2e 5f 5a 31 30 |..nv.shared._Z10|
00000130 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
00000140 50 66 69 00 2e 6e 76 2e 63 6f 6e 73 74 61 6e 74 |Pfi..nv.constant|
00000150 30 2e 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 |0._Z10vector_add|
00000160 50 4b 66 53 30 5f 50 66 69 00 2e 72 65 6c 2e 6e |PKfS0_Pfi..rel.n|
00000170 76 2e 63 6f 6e 73 74 61 6e 74 30 2e 5f 5a 31 30 |v.constant0._Z10|
00000180 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
...
00000d50 2e 76 65 72 73 69 6f 6e 20 39 2e 30 0a 2e 74 61 |.version 9.0..ta|
00000d60 72 67 65 74 20 73 6d 5f 37 35 0a 2e 61 64 64 72 |rget sm_75..addr|
00000d70 65 73 73 5f 73 69 7a 65 20 36 34 0a 0a 0a 0a 2e |ess_size 64.....|
00000d80 76 69 73 69 62 6c 65 20 2e 65 6e 74 72 79 20 5f |visible .entry _|
00000d90 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 |Z10vector_addPKf|
00000da0 53 30 5f 50 66 69 28 0a 2e 70 61 72 61 6d 20 2e |S0_Pfi(..param .|
00000db0 75 36 34 20 5f 5a 31 30 76 65 63 74 6f 72 5f 61 |u64 _Z10vector_a|
00000dc0 64 64 50 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 |ddPKfS0_Pfi_para|
00000dd0 6d 5f 30 2c 0a 2e 70 61 72 61 6d 20 2e 75 36 34 |m_0,..param .u64|
00000de0 20 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 50 | _Z10vector_addP|
00000df0 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 6d 5f 31 |KfS0_Pfi_param_1|
00000e00 2c 0a 2e 70 61 72 61 6d 20 2e 75 36 34 20 5f 5a |,..param .u64 _Z|
00000e10 31 30 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 |10vector_addPKfS|
00000e20 30 5f 50 66 69 5f 70 61 72 61 6d 5f 32 2c 0a 2e |0_Pfi_param_2,..|
00000e30 70 61 72 61 6d 20 2e 75 33 32 20 5f 5a 31 30 76 |param .u32 _Z10v|
00000e40 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 |ector_addPKfS0_P|
00000e50 66 69 5f 70 61 72 61 6d 5f 33 0a 29 0a 7b 0a 2e |fi_param_3.).{..|
00000e60 72 65 67 20 2e 70 72 65 64 20 25 70 3c 32 3e 3b |reg .pred %p<2>;|
00000e70 0a 2e 72 65 67 20 2e 66 33 32 20 25 66 3c 34 3e |..reg .f32 %f<4>|
00000e80 3b 0a 2e 72 65 67 20 2e 62 33 32 20 25 72 3c 36 |;..reg .b32 %r<6|
00000e90 3e 3b 0a 2e 72 65 67 20 2e 62 36 34 20 25 72 64 |>;..reg .b64 %rd|
00000ea0 3c 31 31 3e 3b 0a 0a 0a 6c 64 2e 70 61 72 61 6d |<11>;...ld.param|
00000eb0 2e 75 36 34 20 25 72 64 31 2c 20 5b 5f 5a 31 30 |.u64 %rd1, [_Z10|
00000ec0 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
00000ed0 50 66 69 5f 70 61 72 61 6d 5f 30 5d 3b 0a 6c 64 |Pfi_param_0];.ld|
00000ee0 2e 70 61 72 61 6d 2e 75 36 34 20 25 72 64 32 2c |.param.u64 %rd2,|
00000ef0 20 5b 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 | [_Z10vector_add|
00000f00 50 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 6d 5f |PKfS0_Pfi_param_|
...$ hexdump -C add.fatbin
00000000 50 ed 55 ba 01 00 10 00 48 11 00 00 00 00 00 00 |P.U.....H.......|
00000010 02 00 01 01 40 00 00 00 a8 0c 00 00 00 00 00 00 |....@...........|
00000020 00 00 00 00 00 00 00 00 08 00 01 00 4b 00 00 00 |............K...|
00000030 00 00 00 00 00 00 00 00 11 00 00 00 00 00 00 00 |................|
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 7f 45 4c 46 02 01 01 41 08 00 00 00 00 00 00 00 |.ELF...A........|
00000060 02 00 be 00 01 00 00 00 00 00 00 00 00 00 00 00 |................|
00000070 00 0c 00 00 00 00 00 00 80 08 00 00 00 00 00 00 |................|
00000080 04 4b 00 06 40 00 38 00 03 00 40 00 0e 00 01 00 |.K..@.8...@.....|
00000090 00 2e 73 68 73 74 72 74 61 62 00 2e 73 74 72 74 |..shstrtab..strt|
000000a0 61 62 00 2e 73 79 6d 74 61 62 00 2e 73 79 6d 74 |ab..symtab..symt|
000000b0 61 62 5f 73 68 6e 64 78 00 2e 6e 6f 74 65 2e 6e |ab_shndx..note.n|
000000c0 76 2e 74 6b 69 6e 66 6f 00 2e 6e 6f 74 65 2e 6e |v.tkinfo..note.n|
000000d0 76 2e 63 75 69 6e 66 6f 00 2e 6e 76 2e 69 6e 66 |v.cuinfo..nv.inf|
000000e0 6f 00 2e 74 65 78 74 2e 5f 5a 31 30 76 65 63 74 |o..text._Z10vect|
000000f0 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 66 69 00 |or_addPKfS0_Pfi.|
00000100 2e 6e 76 2e 69 6e 66 6f 2e 5f 5a 31 30 76 65 63 |.nv.info._Z10vec|
00000110 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 66 69 |tor_addPKfS0_Pfi|
00000120 00 2e 6e 76 2e 73 68 61 72 65 64 2e 5f 5a 31 30 |..nv.shared._Z10|
00000130 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
00000140 50 66 69 00 2e 6e 76 2e 63 6f 6e 73 74 61 6e 74 |Pfi..nv.constant|
00000150 30 2e 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 |0._Z10vector_add|
00000160 50 4b 66 53 30 5f 50 66 69 00 2e 72 65 6c 2e 6e |PKfS0_Pfi..rel.n|
00000170 76 2e 63 6f 6e 73 74 61 6e 74 30 2e 5f 5a 31 30 |v.constant0._Z10|
00000180 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
...
00000d50 2e 76 65 72 73 69 6f 6e 20 39 2e 30 0a 2e 74 61 |.version 9.0..ta|
00000d60 72 67 65 74 20 73 6d 5f 37 35 0a 2e 61 64 64 72 |rget sm_75..addr|
00000d70 65 73 73 5f 73 69 7a 65 20 36 34 0a 0a 0a 0a 2e |ess_size 64.....|
00000d80 76 69 73 69 62 6c 65 20 2e 65 6e 74 72 79 20 5f |visible .entry _|
00000d90 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 |Z10vector_addPKf|
00000da0 53 30 5f 50 66 69 28 0a 2e 70 61 72 61 6d 20 2e |S0_Pfi(..param .|
00000db0 75 36 34 20 5f 5a 31 30 76 65 63 74 6f 72 5f 61 |u64 _Z10vector_a|
00000dc0 64 64 50 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 |ddPKfS0_Pfi_para|
00000dd0 6d 5f 30 2c 0a 2e 70 61 72 61 6d 20 2e 75 36 34 |m_0,..param .u64|
00000de0 20 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 50 | _Z10vector_addP|
00000df0 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 6d 5f 31 |KfS0_Pfi_param_1|
00000e00 2c 0a 2e 70 61 72 61 6d 20 2e 75 36 34 20 5f 5a |,..param .u64 _Z|
00000e10 31 30 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 |10vector_addPKfS|
00000e20 30 5f 50 66 69 5f 70 61 72 61 6d 5f 32 2c 0a 2e |0_Pfi_param_2,..|
00000e30 70 61 72 61 6d 20 2e 75 33 32 20 5f 5a 31 30 76 |param .u32 _Z10v|
00000e40 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f 50 |ector_addPKfS0_P|
00000e50 66 69 5f 70 61 72 61 6d 5f 33 0a 29 0a 7b 0a 2e |fi_param_3.).{..|
00000e60 72 65 67 20 2e 70 72 65 64 20 25 70 3c 32 3e 3b |reg .pred %p<2>;|
00000e70 0a 2e 72 65 67 20 2e 66 33 32 20 25 66 3c 34 3e |..reg .f32 %f<4>|
00000e80 3b 0a 2e 72 65 67 20 2e 62 33 32 20 25 72 3c 36 |;..reg .b32 %r<6|
00000e90 3e 3b 0a 2e 72 65 67 20 2e 62 36 34 20 25 72 64 |>;..reg .b64 %rd|
00000ea0 3c 31 31 3e 3b 0a 0a 0a 6c 64 2e 70 61 72 61 6d |<11>;...ld.param|
00000eb0 2e 75 36 34 20 25 72 64 31 2c 20 5b 5f 5a 31 30 |.u64 %rd1, [_Z10|
00000ec0 76 65 63 74 6f 72 5f 61 64 64 50 4b 66 53 30 5f |vector_addPKfS0_|
00000ed0 50 66 69 5f 70 61 72 61 6d 5f 30 5d 3b 0a 6c 64 |Pfi_param_0];.ld|
00000ee0 2e 70 61 72 61 6d 2e 75 36 34 20 25 72 64 32 2c |.param.u64 %rd2,|
00000ef0 20 5b 5f 5a 31 30 76 65 63 74 6f 72 5f 61 64 64 | [_Z10vector_add|
00000f00 50 4b 66 53 30 5f 50 66 69 5f 70 61 72 61 6d 5f |PKfS0_Pfi_param_|
...编译主机代码¶
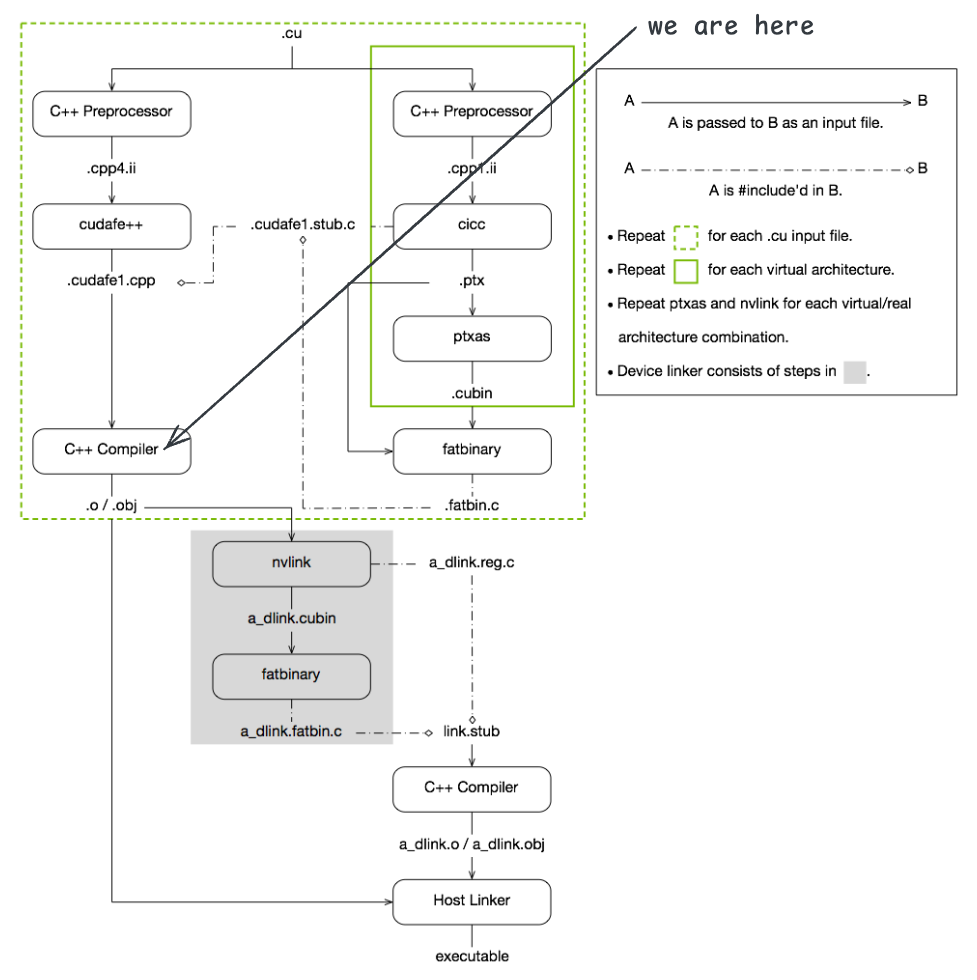
至此,设备端的代码已经被编译完成并嵌入到了 add.fatbin.c 文件中。而这些文件被包含到 add.cudafe1.stub.c 文件中,而 add.cudafe1.stub.c 文件又被包含到主机代码文件 add.cudafe1.cpp 中。
接下来,nvcc 使用系统的 C/C++ 编译器进行编译,生成目标文件 add.o。
$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -m64 "add.cudafe1.cpp" -o "add.o"$ gcc -D__CUDA_ARCH__=750 -D__CUDA_ARCH_LIST__=750 -c -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -Wno-psabi "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -m64 "add.cudafe1.cpp" -o "add.o"设备代码链接¶
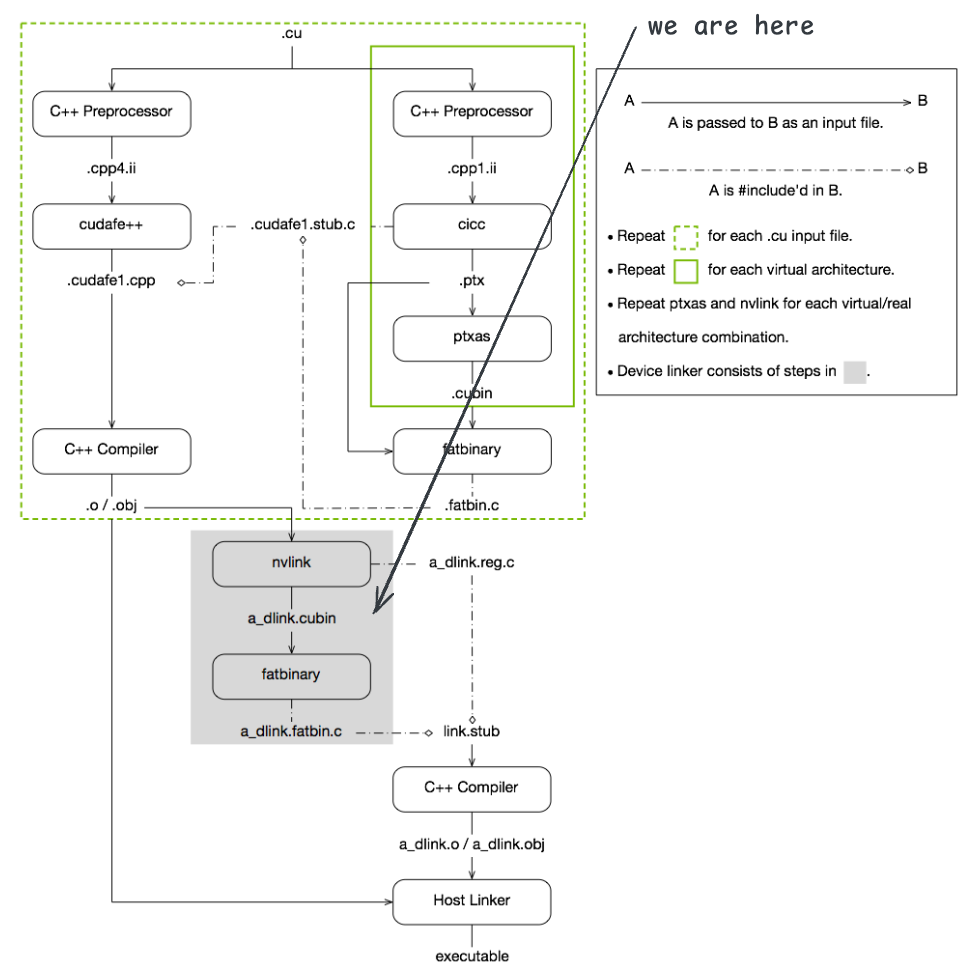
按理说前面的步骤中,设备代码已经编译完成并封装到了 add.o 文件中,接下来应该可以直接调用链接器 ld 生成可执行文件了。但实际上,nvcc 还会进行一次设备代码的链接,它会从所有的目标文件中提取设备代码,执行链接操作。
链接器输入是前面生成的所有的目标文件,本例中只有一个 add.o,链接器会提取其中的设备代码,进行链接操作,生成一个中间的 cubin 文件。观察 nvcc 的执行日志可以看到,这一步调用 nvlink 进行链接,生成 add_dlink.sm_75.cubin 文件:
$ nvlink -m64 --arch=sm_75 --register-link-binaries="add_dlink.reg.c" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -cpu-arch=X86_64 "add.o" -lcudadevrt -o "add_dlink.sm_75.cubin" --host-ccbin "gcc"$ nvlink -m64 --arch=sm_75 --register-link-binaries="add_dlink.reg.c" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -cpu-arch=X86_64 "add.o" -lcudadevrt -o "add_dlink.sm_75.cubin" --host-ccbin "gcc"此处处理 CUDA 代码的可重定位和跨模块调用等场景;如果不涉及这些复杂情况,设备代码链接这一步通常没有实际作用。本例中,add_dlink.sm_75.cubin 只是一个空的 ELF 文件。
链接生成可执行文件¶
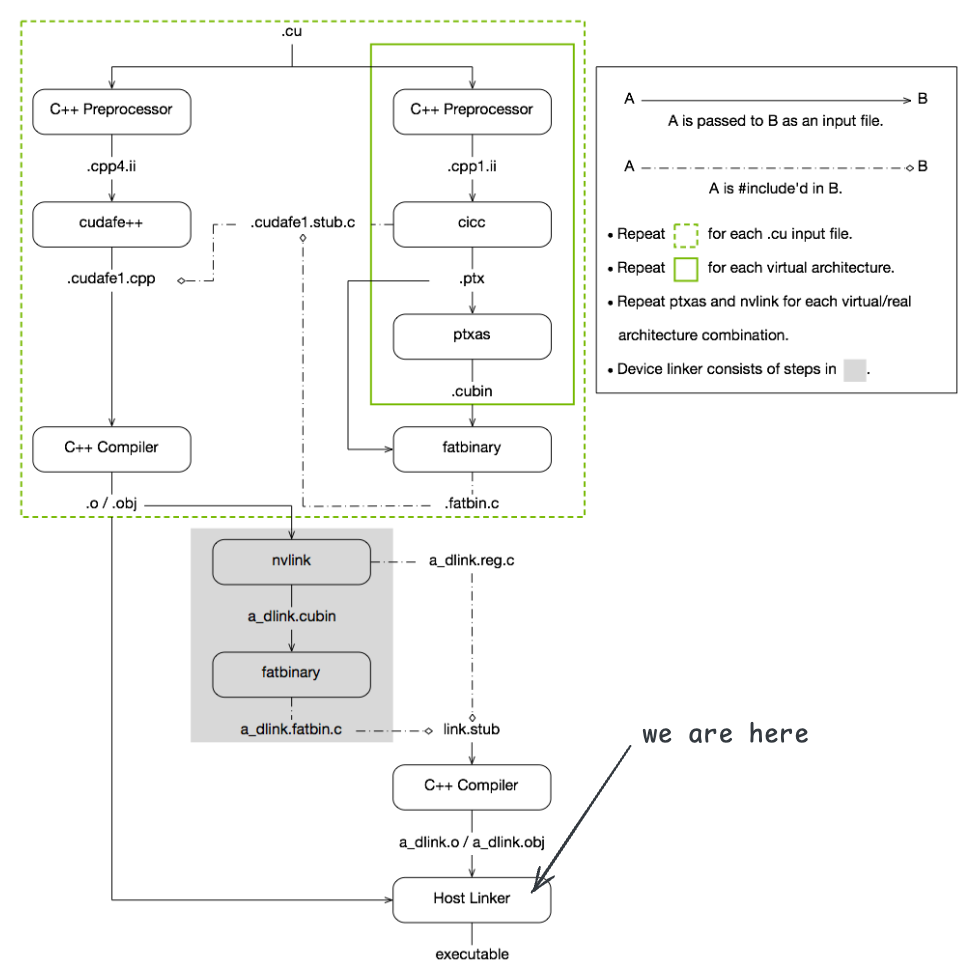
至此,可以调用系统的链接器 ld,将所有目标文件链接生成最终的可执行文件。观察 nvcc 的执行日志可以看到,这一步调用 gcc 进行链接,生成 add 可执行文件:
$ g++ -D__CUDA_ARCH_LIST__=750 -m64 -Wl,--start-group "add_dlink.o" "add.o" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group -o "add"$ g++ -D__CUDA_ARCH_LIST__=750 -m64 -Wl,--start-group "add_dlink.o" "add.o" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib/stubs" "-L/usr/local/cuda-13.0/bin/../targets/x86_64-linux/lib" -lcudadevrt -lcudart_static -lrt -lpthread -ldl -Wl,--end-group -o "add"小结¶
到此为止,整个 CUDA 程序的编译流程就分析完毕了。整个流程并不复杂,就是使用专用的编译工具链将 kernel 编译为 GPU 可执行的代码,并将其嵌入到可执行文件的某个 section 中。并将主机代码中的 kernel 启动函数替换为调用 CUDA 运行时库的接口函数。在程序运行时,CUDA 运行时库会负责将设备代码加载到 GPU 上执行。
多目标架构编译¶
在整个编译流程图中,绿色实线框中的流程表示单目标架构编译流程。如果在编译时指定了多个目标架构,则需要针对每个目标架构重复执行设备代码的预处理、编译、汇编和链接步骤,最终生成多个 cubin 文件,然后将这些 cubin 文件封装到一个 fatbin 文件中,嵌入到主机代码中。
nvcc add.cu \
--generate-code arch=compute_90,code=sm_90 \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_86,code=sm_86 \
--generate-code arch=compute_86,code=sm_89 \
--keep -v -o addnvcc add.cu \
--generate-code arch=compute_90,code=sm_90 \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_86,code=sm_86 \
--generate-code arch=compute_86,code=sm_89 \
--keep -v -o add如果执行以上命令,nvcc 会针对每个目标架构生成对应的中间文件,在基于中间文件生成 GPU 机器码。最终生成一个包含多个架构代码的 fatbin 文件。虽然为多个架构生成了多个 cubin 文件,但其他流程都没有变,只是在启动 kernel 时,CUDA 运行时会根据当前 GPU 的架构选择合适的设备代码进行加载和执行。
# arch=compute_90
$ gcc -D__CUDA_ARCH__=900 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_90.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_90 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_90.cudafe1.c" --stub_file_name "add.compute_90.cudafe1.stub.c" --gen_device_file_name "add.compute_90.cudafe1.gpu" "add.compute_90.cpp1.ii" -o "add.compute_90.ptx"
# code=sm_90
$ ptxas -arch=sm_90 -m64 "add.compute_90.ptx" -o "add.compute_90.cubin"
# arch=compute_80
$ gcc -D__CUDA_ARCH__=800 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_80.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_80 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_80.cudafe1.c" --stub_file_name "add.compute_80.cudafe1.stub.c" --gen_device_file_name "add.compute_80.cudafe1.gpu" "add.compute_80.cpp1.ii" -o "add.compute_80.ptx"
# code=sm_80
$ ptxas -arch=sm_80 -m64 "add.compute_80.ptx" -o "add.compute_80.cubin"
# arch=compute_86
$ gcc -D__CUDA_ARCH__=860 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_86.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_86 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_86.cudafe1.c" --stub_file_name "add.compute_86.cudafe1.stub.c" --gen_device_file_name "add.compute_86.cudafe1.gpu" "add.compute_86.cpp1.ii" -o "add.compute_86.ptx"
# code=sm_89
$ ptxas -arch=sm_89 -m64 "add.compute_86.ptx" -o "add.compute_86.sm_89.cubin"
# code=sm_86
$ ptxas -arch=sm_86 -m64 "add.compute_86.ptx" -o "add.compute_86.sm_86.cubin"
$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=90,file=add.compute_90.cubin" "--image3=kind=elf,sm=80,file=add.compute_80.cubin" "--image3=kind=elf,sm=89,file=add.compute_86.sm_89.cubin" "--image3=kind=elf,sm=86,file=add.compute_86.sm_86.cubin" --embedded-fatbin="add.fatbin.c"# arch=compute_90
$ gcc -D__CUDA_ARCH__=900 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_90.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_90 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_90.cudafe1.c" --stub_file_name "add.compute_90.cudafe1.stub.c" --gen_device_file_name "add.compute_90.cudafe1.gpu" "add.compute_90.cpp1.ii" -o "add.compute_90.ptx"
# code=sm_90
$ ptxas -arch=sm_90 -m64 "add.compute_90.ptx" -o "add.compute_90.cubin"
# arch=compute_80
$ gcc -D__CUDA_ARCH__=800 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_80.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_80 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_80.cudafe1.c" --stub_file_name "add.compute_80.cudafe1.stub.c" --gen_device_file_name "add.compute_80.cudafe1.gpu" "add.compute_80.cpp1.ii" -o "add.compute_80.ptx"
# code=sm_80
$ ptxas -arch=sm_80 -m64 "add.compute_80.ptx" -o "add.compute_80.cubin"
# arch=compute_86
$ gcc -D__CUDA_ARCH__=860 -D__CUDA_ARCH_LIST__=800,860,900 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ "-I/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include" "-isystem" "/usr/local/cuda-13.0/bin/../targets/x86_64-linux/include/cccl" -D__CUDACC_VER_MAJOR__=13 -D__CUDACC_VER_MINOR__=0 -D__CUDACC_VER_BUILD__=88 -D__CUDA_API_VER_MAJOR__=13 -D__CUDA_API_VER_MINOR__=0 -D__NVCC_DIAG_PRAGMA_SUPPORT__=1 -D__CUDACC_DEVICE_ATOMIC_BUILTINS__=1 -include "cuda_runtime.h" -m64 "add.cu" -o "add.compute_86.cpp1.ii"
$ "$CICC_PATH/cicc" --c++17 --static-host-stub --device-hidden-visibility --gnu_version=130300 --display_error_number --orig_src_file_name "add.cu" --orig_src_path_name "/home/wangyu/code/cuda/labs/compile/multi-arch/add.cu" --allow_managed -arch compute_86 -m64 --no-version-ident -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 --include_file_name "add.fatbin.c" -tused --module_id_file_name "add.module_id" --gen_c_file_name "add.compute_86.cudafe1.c" --stub_file_name "add.compute_86.cudafe1.stub.c" --gen_device_file_name "add.compute_86.cudafe1.gpu" "add.compute_86.cpp1.ii" -o "add.compute_86.ptx"
# code=sm_89
$ ptxas -arch=sm_89 -m64 "add.compute_86.ptx" -o "add.compute_86.sm_89.cubin"
# code=sm_86
$ ptxas -arch=sm_86 -m64 "add.compute_86.ptx" -o "add.compute_86.sm_86.cubin"
$ fatbinary --create="add.fatbin" -64 --cicc-cmdline="-ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 " "--image3=kind=elf,sm=90,file=add.compute_90.cubin" "--image3=kind=elf,sm=80,file=add.compute_80.cubin" "--image3=kind=elf,sm=89,file=add.compute_86.sm_89.cubin" "--image3=kind=elf,sm=86,file=add.compute_86.sm_86.cubin" --embedded-fatbin="add.fatbin.c"cicc 用来生成针对不同架构的 PTX 代码,ptxas 则用来将 PTX 代码编译为特定硬件的机器码 cubin 文件。整个流程如下图所示:

那么 compute_86、sm_86 和 sm_89 又代表什么呢?本节将详细描述 CUDA 是如何支持多目标架构编译的。
计算能力与实际架构¶
CUDA 设备代码编译时需要指定两个相关但不同的概念:计算能力(compute capability)和实际架构(real architecture)。
计算能力(compute capability)是一个抽象的概念,每个计算能力对应一组特性和指令集,CUDA 程序可以根据计算能力来决定使用哪些特性。计算能力通常以 compute_XY 的形式表示,其中 X 是主版本号,Y 是次版本号。例如,compute_75 表示计算能力为 7.5 的 GPU。比如,计算能力 9.0 的 GPU 支持 TMA 功能,而计算能力 8.0 的 GPU 则不支持。
下面是一些常见计算能力及其对应的 GPU 架构:
compute_75 | Turing support |
compute_80, compute_86 and compute_87, compute_88 | NVIDIA Ampere GPU architecture support |
compute_89 | Ada support |
compute_90, compute_90a | Hopper support |
compute_100, compute_100f, compute_100a, compute_103, compute_103f, compute_103a, compute_110, compute_110f, compute_110a, compute_120, compute_120f, compute_120a, compute_121, compute_121f, compute_121a | Blackwell support |
在 https://developer.nvidia.com/cuda/gpus 中可以看到完整的计算能力列表。
而实际架构(real architecture)则是指具体的 GPU 硬件架构,每个实际架构对应一个特定的 GPU 型号。实际架构通常以 sm_XY 的形式表示,其中 X 是主版本号,Y 是次版本号。例如,sm_75 表示实际架构为 7.5 的 GPU。
比如 RTX 4090 的实际架构是 sm_89,对应的计算能力是 compute_89。H100 的实际架构是 sm_90,对应的计算能力是 compute_90。RTX 5070 的实际架构是 sm_120,对应的计算能力是 compute_120。
控制代码生成¶
我们编写的 CUDA 程序可能会被运行在不同计算能力和实际架构的 GPU 上。为了确保程序能在更多的 GPU 上运行,我们的程序需要更低计算能力,比如不能使用最新的 GPU 特性,否则在计算能力较低的 GPU 上就无法运行。但我们又希望程序能在更高计算能力的 GPU 上运行时,能利用更高计算能力 GPU 的特性以提升性能。这个时候就需要多目标架构编译。
在编写代码时,可以使用 #if __CUDA_ARCH__ >= XY 预处理指令来判断当前编译的计算能力,从而选择性地启用某些代码路径。例如:
#if __CUDA_ARCH__ >= 800
// 使用计算能力 8.0 及以上的特性
#else
// 兼容较低计算能力的代码路径
#endif#if __CUDA_ARCH__ >= 800
// 使用计算能力 8.0 及以上的特性
#else
// 兼容较低计算能力的代码路径
#endif在编译时,可以针对不同的计算能力来生成不同的 PTX 代码,还可以针对不同的实际架构生成不同的机器码 cubin 文件。这样,在程序运行时,CUDA 运行时库会根据当前 GPU 的计算能力选择合适的设备代码进行加载和执行。如果当前可执行文件中没有包含适用于当前 GPU 的设备指令,只要有包含适用于当前计算能力的 PTX 代码,CUDA 运行时库也会将 PTX 代码 JIT 编译为适用于当前 GPU 的机器码并执行。

下面这几个命令行选项用于控制多目标架构编译:
=> --gpu-architecture (-arch)
该选项指定 GPU 虚拟架构,即计算能力,该选项会影响 PTX 代码的生成,编译时只会使用低于等于该计算能力的特性。例如:
nvcc add.cu -arch=compute_80 -o addnvcc add.cu -arch=compute_80 -o add这个命令会使用计算能力 8.0 进行编译,因为没有指定 --gpu-code 选项,所以默认会将 --gpu-code 设置为与 --gpu-architecture 相同的值。因为不涉及具体的实际架构,所以生成的设备代码是 PTX 代码。程序启动时,如果计算能力匹配,则会加载 PTX 代码进行 JIT 编译执行;否则,如果 GPU 的计算能力低于 8.0,则无法运行该程序。
nvcc add.cu -arch=sm_80 -o addnvcc add.cu -arch=sm_80 -o add这个命令会使用实际架构 8.0 对应的计算能力 8.0 来编译产生 PTX,并为 sm_80 生成机器码 cubin 文件并嵌入到可执行文件中。
nvcc add.cu -arch=native -o addnvcc add.cu -arch=native -o add有一个特殊的计算能力 native,表示使用当前系统中安装的 GPU 的计算能力进行编译。这个命令会查询当前系统中的 GPU,获取其计算能力,然后使用该计算能力进行编译。使用 native 选项可以确保生成的设备代码能够充分利用当前系统中 GPU 的特性,并且通常最终都是在当前环境下运行,因此使用 native 选项编译时,不会包含 PTX 代码,而是直接生成适用于当前 GPU 的机器码 cubin 文件。因此使用 native 选项编译生成的可执行文件只能在完全相同架构的 GPU 上运行。
=> --gpu-code (-code)
该选项指定实际架构,该选项会影响最终生成的机器码 cubin 文件。例如:
nvcc add.cu -arch=compute_80 -code=sm_80,sm_120 -o addnvcc add.cu -arch=compute_80 -code=sm_80,sm_120 -o add这个命令会使用计算能力 8.0 进行编译,并生成适用于实际架构 sm_80 和 sm_120 的机器码 cubin 文件。在程序运行时,如果 GPU 的实际架构是 sm_80 或 sm_120,则会加载对应的机器码进行执行;否则,如果 GPU 的计算能力低于 8.0,则无法运行该程序,如果 GPU 的计算能力高于 8.0,则会 JIT 编译 PTX 代码进行执行。
=> --generate-code (-gencode)
使用 -arch 和 -code 选项只能指定单个计算能力和实际架构的组合,而要想针对多个计算能力和实际架构进行编译,就需要使用 --generate-code 选项。下面是 --generate-code 选项的语法:
nvcc add.cu \
--generate-code arch=compute_75,code=sm_75 \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_86,code=sm_86nvcc add.cu \
--generate-code arch=compute_75,code=sm_75 \
--generate-code arch=compute_80,code=sm_80 \
--generate-code arch=compute_86,code=sm_86这个命令表示针对计算能力 7.5、8.0 和 8.6 进行编译,并分别生成适用于实际架构 sm_75、sm_80 和 sm_86 的机器码 cubin 文件。
小结¶
通过 --gpu-architecture、--gpu-code 和 --generate-code 选项,可以控制 CUDA 程序的多目标架构编译,从而确保程序能够在更多的 GPU 上运行,并充分利用不同计算能力和实际架构的特性以提升性能。
在程序启动后,CUDA 运行时会使用以下流程来选择合适的设备代码进行加载和执行:
- 获取当前 GPU 的版本,比如 RTX 5070,其实际架构为
sm_120,计算能力为compute_120。 - 检查可执行文件中是否包含适用于
sm_120的机器码cubin文件。 - 如果包含,则直接加载该机器码进行执行。
- 如果不包含,则检查可执行文件中是否包含适用于
compute_120的 PTX 代码,只要编译时指定的计算能力小于等于 120,就可以现场将 PTX 编译成 SM_120 的 SASS。 - 如果既不包含适用于
sm_120的机器码,也不包含适用于compute_120的 PTX 代码,则无法运行该程序。会报错:no kernel image is available for execution on the device。
总结¶
至此,本文对 CUDA 程序的编译流程进行了详细介绍,了解了 CUDA 程序是如何从源代码经过预处理、编译、汇编、链接等步骤,最终生成可执行文件的。并且了解了多目标架构编译的原理和实现方法。