本文详细介绍了 SGLang RL 团队在优化 verl 中的内存使用方面所做的努力,重点介绍了减少峰值内存需求并在有限的 GPU 资源上训练更大模型的技术。
简介¶
大型语言模型(LLM)的强化学习(RL)面临独特的挑战,因为它在每一步都整合了推理和训练,需要显著的可扩展性和资源效率。verl 库专为 LLM 的 RL 训练而设计,将先进的训练策略如 Fully Sharded Data Parallel(FSDP)和 Megatron-LM 与推理引擎(如 SGLang)相结合,以实现高效的 rollout 生成。本文详细介绍了 SGLang RL 团队在优化 verl 中的内存使用方面所做的努力,重点介绍了减少峰值内存需求并在有限的 GPU 资源上训练更大模型的技术。
高层 RL 训练工作流¶
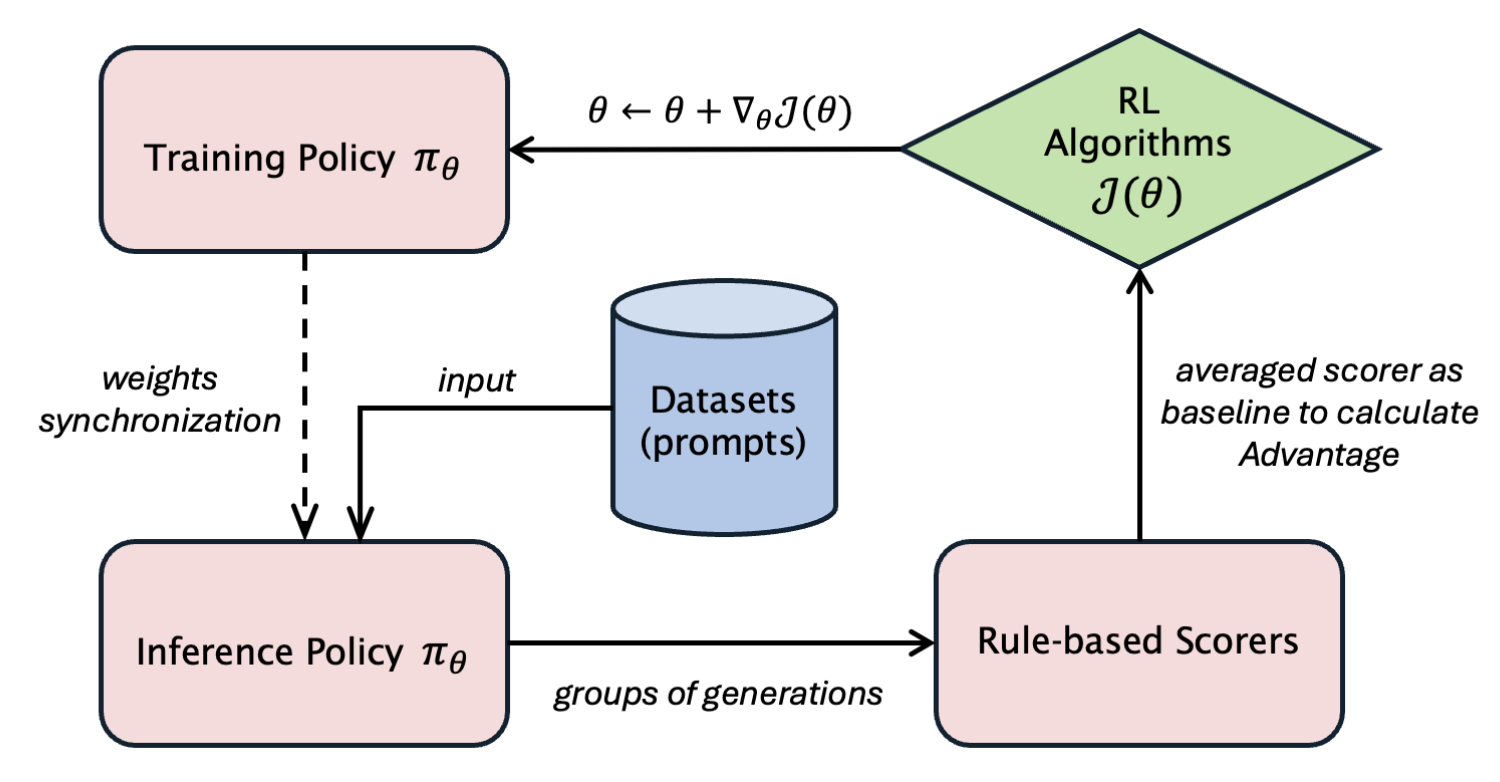
上图展示了在线 RL 训练过程,为简化起见,省略了参考模型和 critic 模型,并假设使用基本奖励函数(在代码和推理任务中很常见)而不是奖励模型。策略模型存在两个实例:一个针对训练进行优化(使用 FSDP 或 Megatron-LM),另一个用于推理(使用 SGLang 或 vLLM)。
简化的 PPO 示例¶
以下是使用 Proximal Policy Optimization(PPO)的简化实现:
for prompts, pretrain_batch in dataloader:
# Stage 1: Rollout generation (inference)
batch = actor.generate_sequences(prompts)
# Stage 2: Prepare experience
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch) # Reward function or model
batch = compute_advantages(batch, algo_type)
# Stage 3: Actor training
actor_metrics = actor.update_actor(batch)for prompts, pretrain_batch in dataloader:
# Stage 1: Rollout generation (inference)
batch = actor.generate_sequences(prompts)
# Stage 2: Prepare experience
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch) # Reward function or model
batch = compute_advantages(batch, algo_type)
# Stage 3: Actor training
actor_metrics = actor.update_actor(batch)每次迭代都包括使用 actor 模型的 rollout(推理)阶段,然后进行训练。verl 的设计将 actor 模型的 rollout 和训练版本共同放置在同一 GPU 上,优化了资源共享,但使内存管理变得复杂。本文重点解决 actor 模型的内存挑战。
内存挑战¶
verl 中的 RL 训练需要在 rollout 和训练阶段之间无缝切换,这两个阶段都是内存密集型的。在同一 GPU 上共同放置这些阶段会面临内存不足(OOM)错误的风险,尤其是对于大型模型。以下是在 H200 GPU 节点(8 个 GPU,每个约 141 GB VRAM)上使用 FSDP 进行训练和 SGLang 进行 rollout 的 Qwen2.5-7B-Instruct 的内存分解。
训练阶段内存分解¶
使用 FSDP 在 8 个 GPU 上进行分片,并启用完全分片模式和完全激活检查点,每个 GPU 持有:
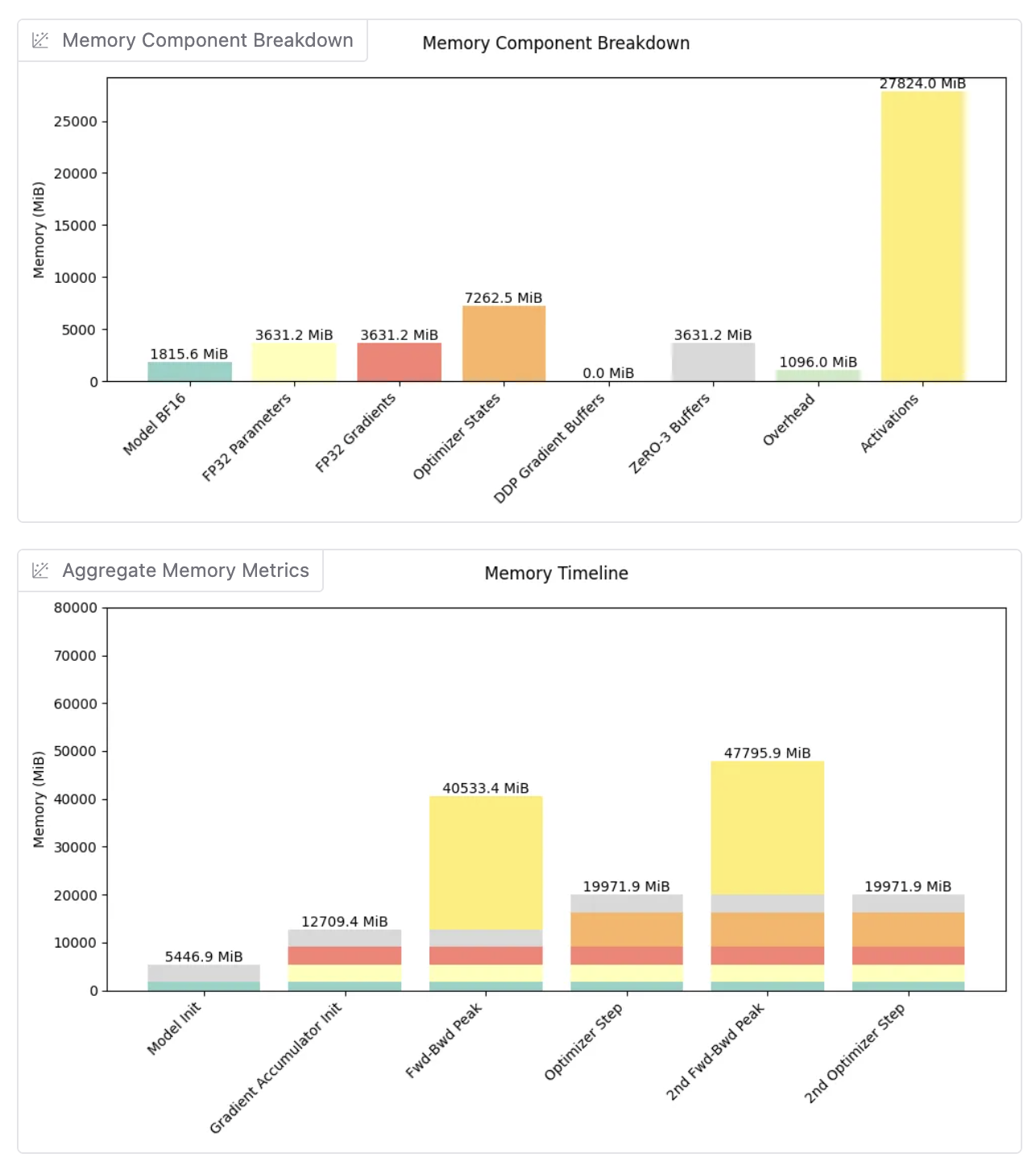
训练峰值内存:每个 GPU 约 48 GB
Rollout 阶段内存分解¶
在推理期间,通常加载完整模型(不分片):
- 模型权重:约 15.4 GB(为推理效率而加载的完整模型)
- KV 缓存:约 60-90 GB(主导因素,可通过 SGLang 中的
mem-fraction调整,假设比率为 0.7-0.9) - CUDA Graph:约 1-3 GB(捕获计算图以加速推理)
- 输入/输出缓冲区:约 3-7 GB(请求批处理和响应生成)
Rollout 总内存:每个 GPU 约 80-115 GB
在同一 GPU 上管理这些内存需求需要仔细优化,以避免阶段转换期间的 OOM 错误。
内存优化历程¶
朴素方法¶
在我们最初的方法中,我们将训练模型权重和推理引擎(SGLang)都保留在 GPU 内存中,而不进行卸载。
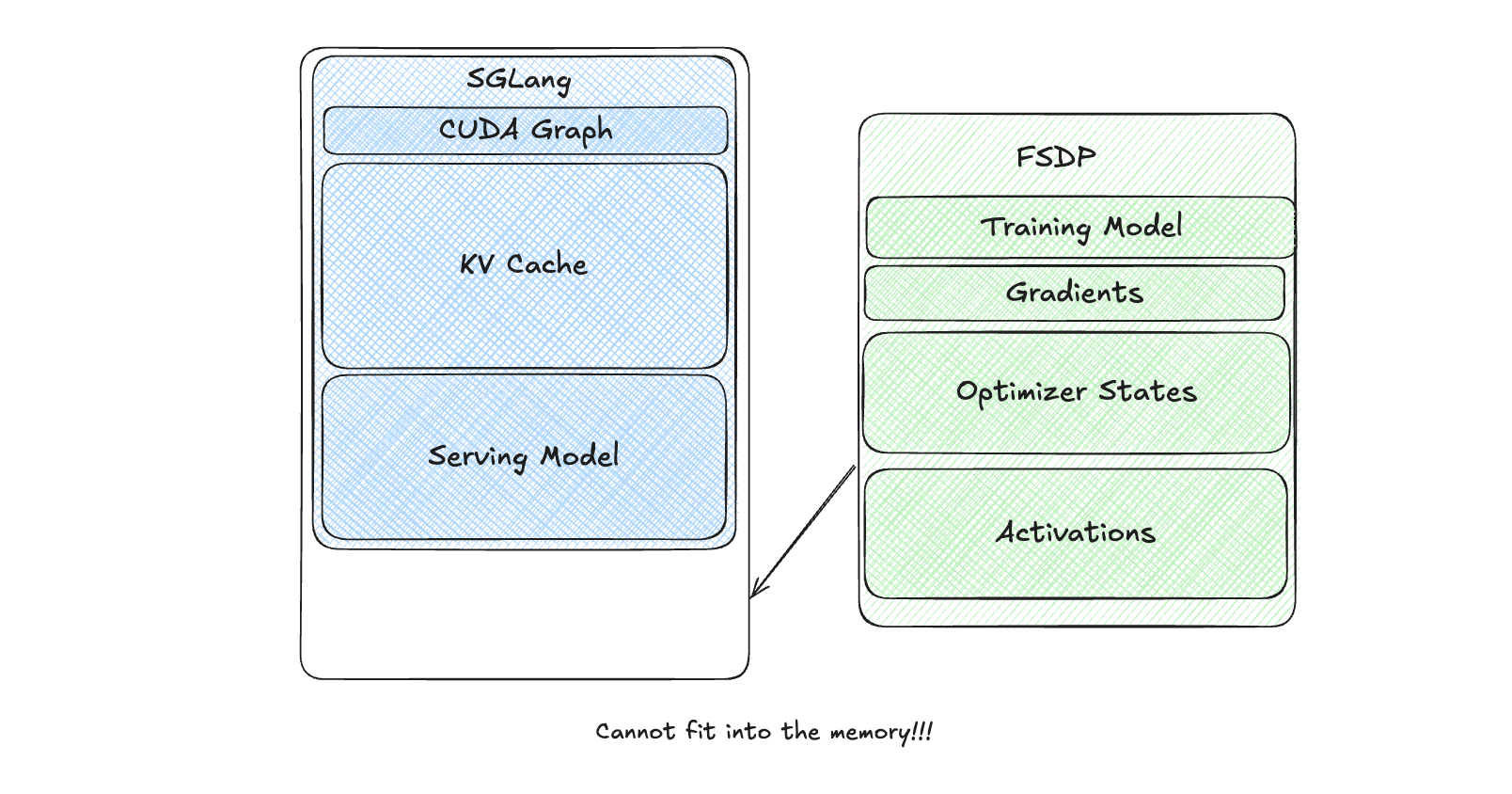
然而,SGLang 巨大的内存占用使得无法开始训练。这只是一个概念基线,从未实现。
将权重卸载到 CPU 并重新启动推理引擎¶
为了解决这个问题,我们在训练后将训练模型权重卸载到 CPU,并将其序列化到磁盘。在 rollout 阶段,我们重新启动 SGLang 引擎,从磁盘加载权重。
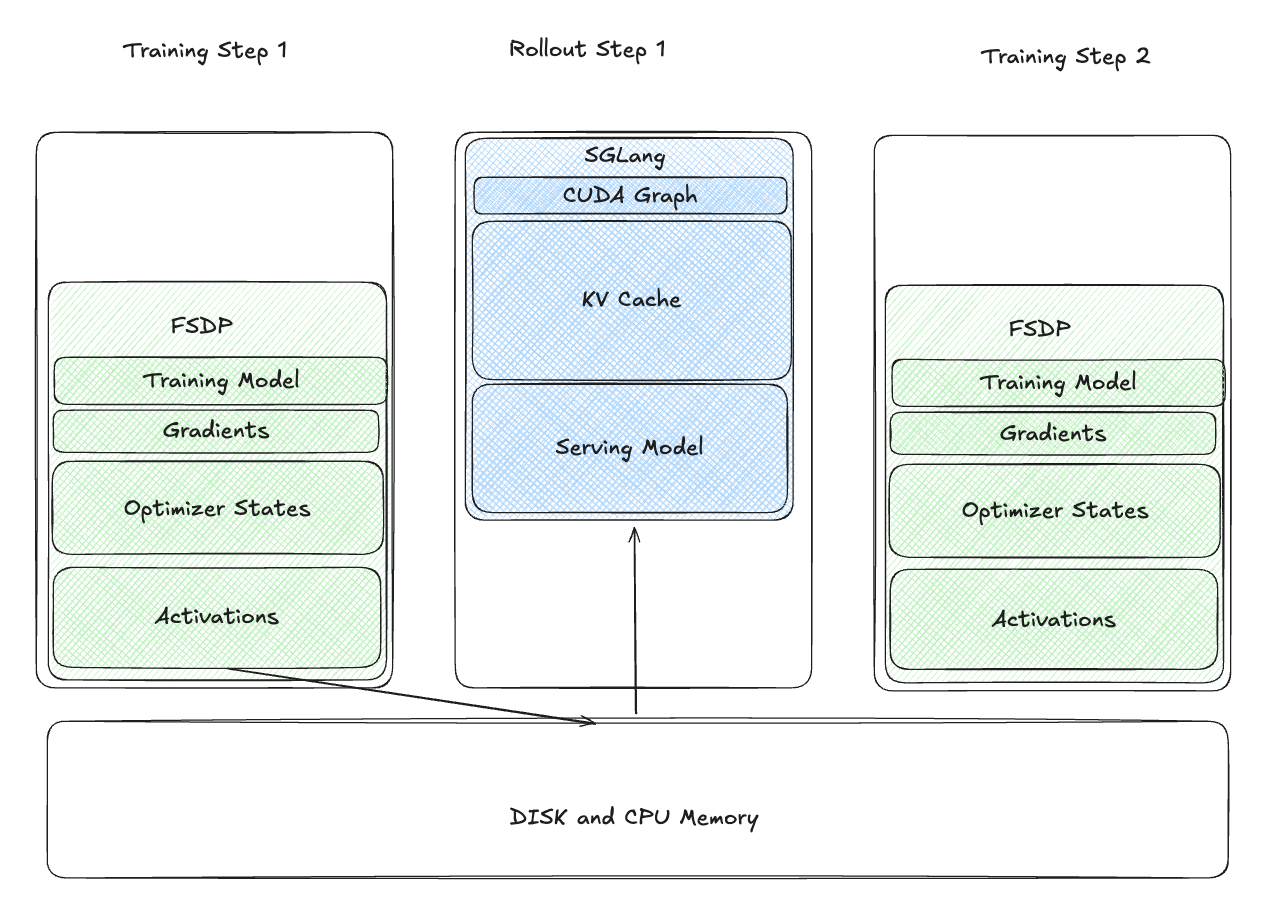
这减少了 rollout 期间的 GPU 内存使用,但引入了显著的延迟:
- 慢速磁盘 I/O:从磁盘加载权重非常耗时。
- 重新捕获 CUDA Graph:重新捕获 CUDA Graph 增加了开销。
虽然这是一个改进,但对于实际使用来说太慢了。
休眠推理引擎¶
我们探索了在训练期间保持 CUDA Graph 存活,同时释放权重和 KV cache 内存。挑战在于重新创建这些张量会破坏 CUDA Graph replay,因为虚拟内存地址发生了变化。
因此目标可以重新表述为:
- 在训练期间释放物理内存以分配空间。
- 在 rollout 期间在相同的虚拟内存地址处重新分配权重和 KV cache 的 GPU 内存。
SGLang RL 团队(感谢 Tom)开发了 torch_memory_saver 库,实现了内存暂停和恢复,同时保持 CUDA Graph 兼容性。
以下是它的工作原理:
import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# Create tensors in a pausable region
with memory_saver.region():
pauseable_tensor = torch.full((1_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# Pause to free CUDA memory
memory_saver.pause()
# Resume to reallocate memory at the same virtual address
memory_saver.resume()import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# Create tensors in a pausable region
with memory_saver.region():
pauseable_tensor = torch.full((1_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# Pause to free CUDA memory
memory_saver.pause()
# Resume to reallocate memory at the same virtual address
memory_saver.resume()使用 CUDA 虚拟内存 API 实现¶
在 CUDA 10.2 之前,内存管理依赖于 cudaMalloc、cudaFree 和 cudaMemcpy,这些缺乏对虚拟内存地址的控制。CUDA 10.2 引入了用于细粒度虚拟内存管理的 API:
cuMemCreate:创建物理内存句柄。cuMemAddressReserve:保留虚拟地址范围。cuMemMap:将物理内存句柄映射到虚拟地址范围。
这些 API 使自定义内存分配器能够保留虚拟内存地址。在 SGLang 和 verl 系统中,我们利用 LD_PRELOAD 用我们的自定义分配器替换默认的 cuda malloc 和 free。
修改的 CUDA Malloc¶
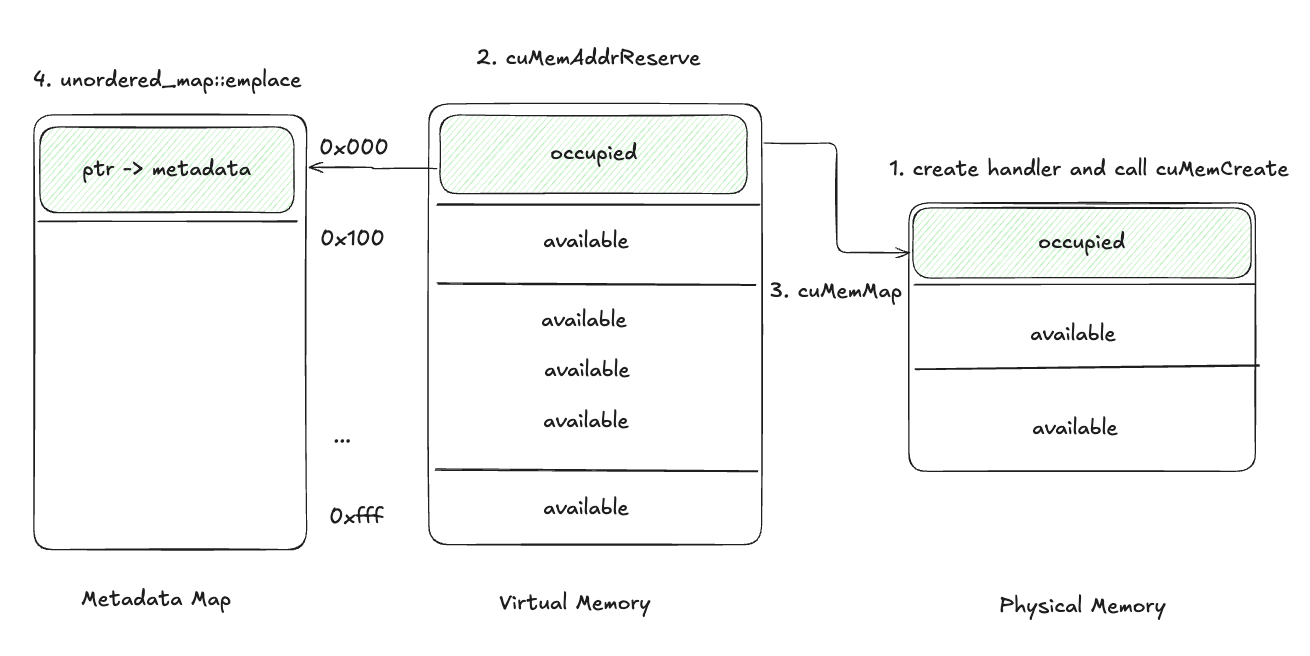
- 创建一个
CUmemGenericAllocationHandle并使用cuMemCreate分配物理内存,句柄包含要分配的内存的属性,例如此内存物理位置在哪里或应提供哪种可共享句柄。 - 使用
cuMemAddressReserve保留虚拟地址范围。 - 使用
cuMemMap将物理内存映射到虚拟地址。 - 将虚拟内存指针和物理内存句柄存储在元数据映射中。
暂停张量¶
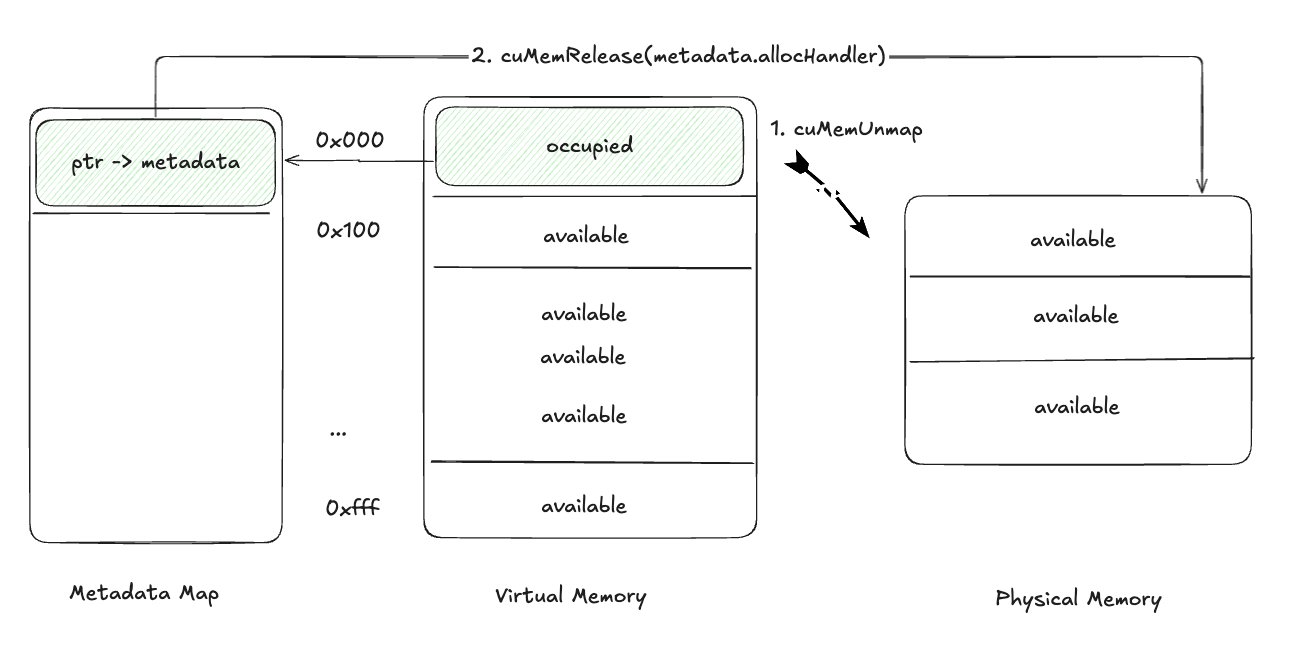
- 使用
cuMemUnmap从虚拟地址范围取消映射内存。 - 从元数据映射中检索物理内存句柄并使用
cuMemRelease释放它。
这释放了物理内存,同时保留了虚拟地址。
恢复张量¶
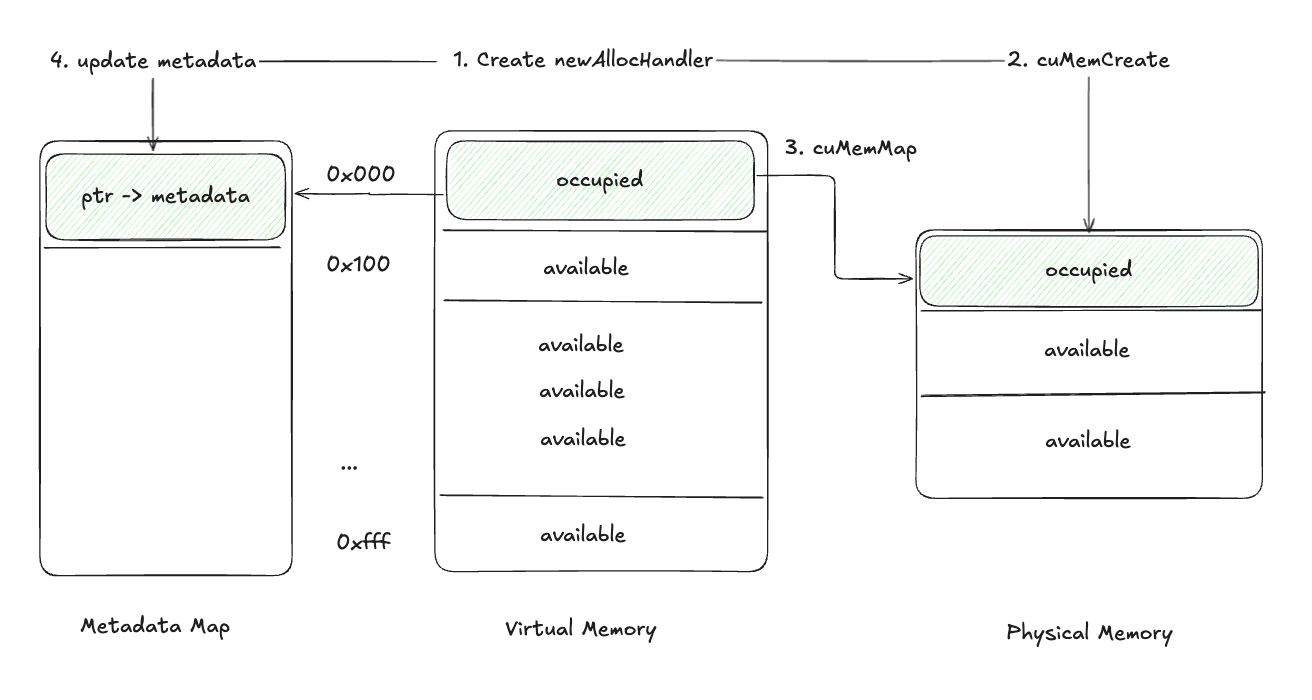
- 使用
cuMemCreate创建一个新的物理内存句柄。 - 使用
cuMemAlloc分配物理内存。 - 使用
cuMemMap将新的物理内存映射到存储的虚拟地址。 - 更新元数据映射以包含新的句柄。
到目前为止,我们针对内存挑战已经有了一个相当不错的解决方案。
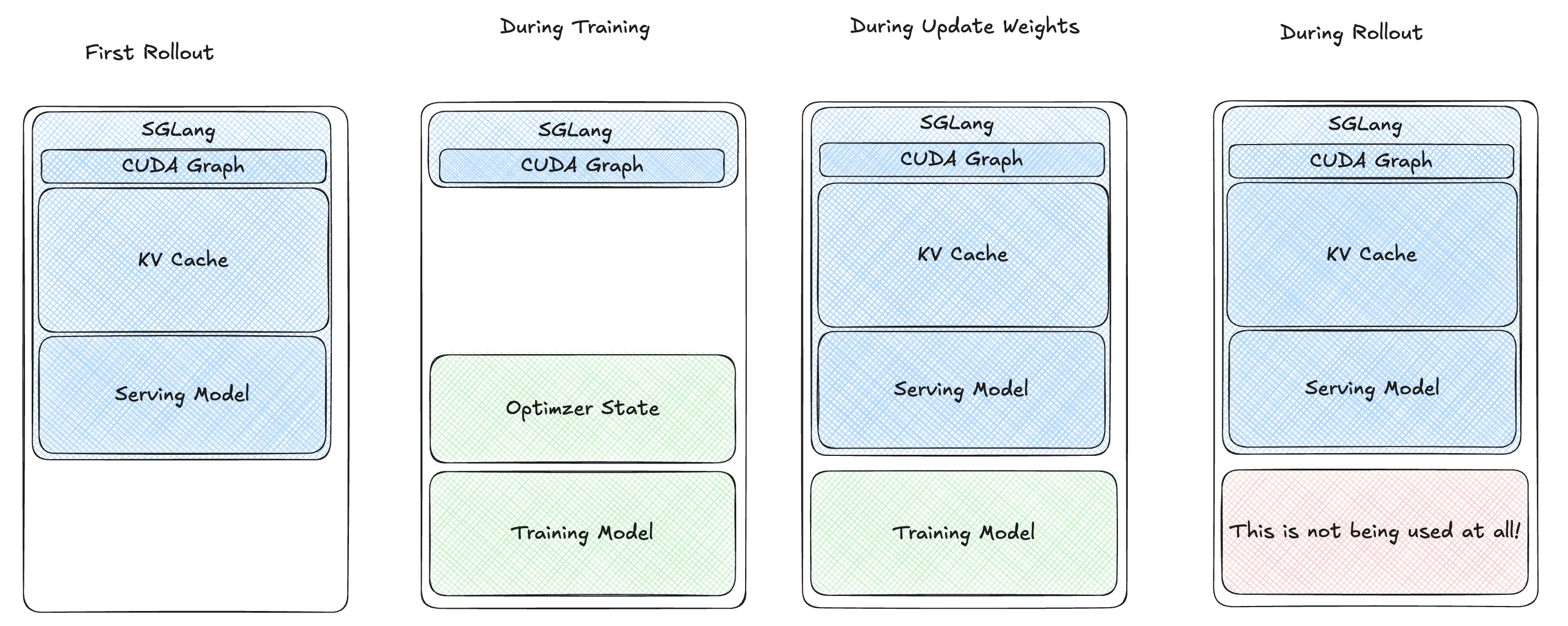
权重加载优化¶
为了解决权重加载缓慢的问题,我们避免了磁盘序列化。相反,我们将训练模型权重加载到 GPU 上,并通过 CUDA 进程间通信更新 rollout 引擎的权重。这显著减少了训练到 rollout 切换的时间(例如,对于 7B 模型,时间小于 0.5 秒)。
多阶段唤醒¶
尽管有这些改进,我们的用户报告在使用更大模型或高 KV 缓存比率(> 0.7)时,在训练-rollout 切换期间出现内存不足(OOM)错误。我们发现在恢复过程中存在内存浪费(上图中的红色块)。为了优化,我们将恢复过程分为多个阶段:
- 将训练模型权重加载到 GPU 上。
- 恢复推理模型权重。
- 同步权重。
- 卸载训练模型。
- 为 rollout 恢复 KV 缓存。
最初,torch_memory_saver 的单例设计不支持选择性暂停/恢复内存区域。我们探索了两种解决方案:
- 多个
torch_memory_saver实例。 - 基于标签的暂停/恢复 API。
我们选择了基于标签的方法,以最小化对 SGLang 代码库的更改,因为 SGLang 严重依赖单例设计。您可以在 RFC 中找到两种实现的详细信息。
基于标签的内存管理¶
我们向张量元数据添加了一个标签参数,实现了选择性暂停/恢复。
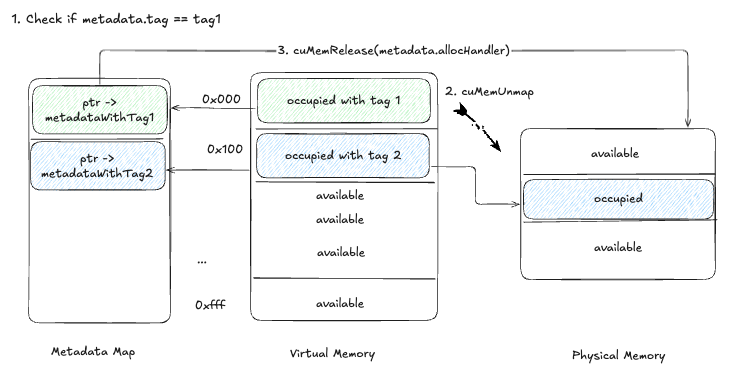
暂停过程:
- 检查每个张量的元数据以匹配标签。
- 如果匹配,使用
cuMemUnmap取消映射内存。 - 使用
cuMemRelease释放物理内存。
新接口:
import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# 使用特定标签创建张量
with torch_memory_saver.region(tag="weights"):
tensor1 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
with torch_memory_saver.region(tag="kv_cache"):
tensor2 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# 选择性暂停和恢复
torch_memory_saver.pause("weights")
torch_memory_saver.pause("kv_cache")
torch_memory_saver.resume("weights")
# 同步权重并卸载训练模型
torch_memory_saver.resume("kv_cache")import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# 使用特定标签创建张量
with torch_memory_saver.region(tag="weights"):
tensor1 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
with torch_memory_saver.region(tag="kv_cache"):
tensor2 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# 选择性暂停和恢复
torch_memory_saver.pause("weights")
torch_memory_saver.pause("kv_cache")
torch_memory_saver.resume("weights")
# 同步权重并卸载训练模型
torch_memory_saver.resume("kv_cache")多阶段恢复过程:
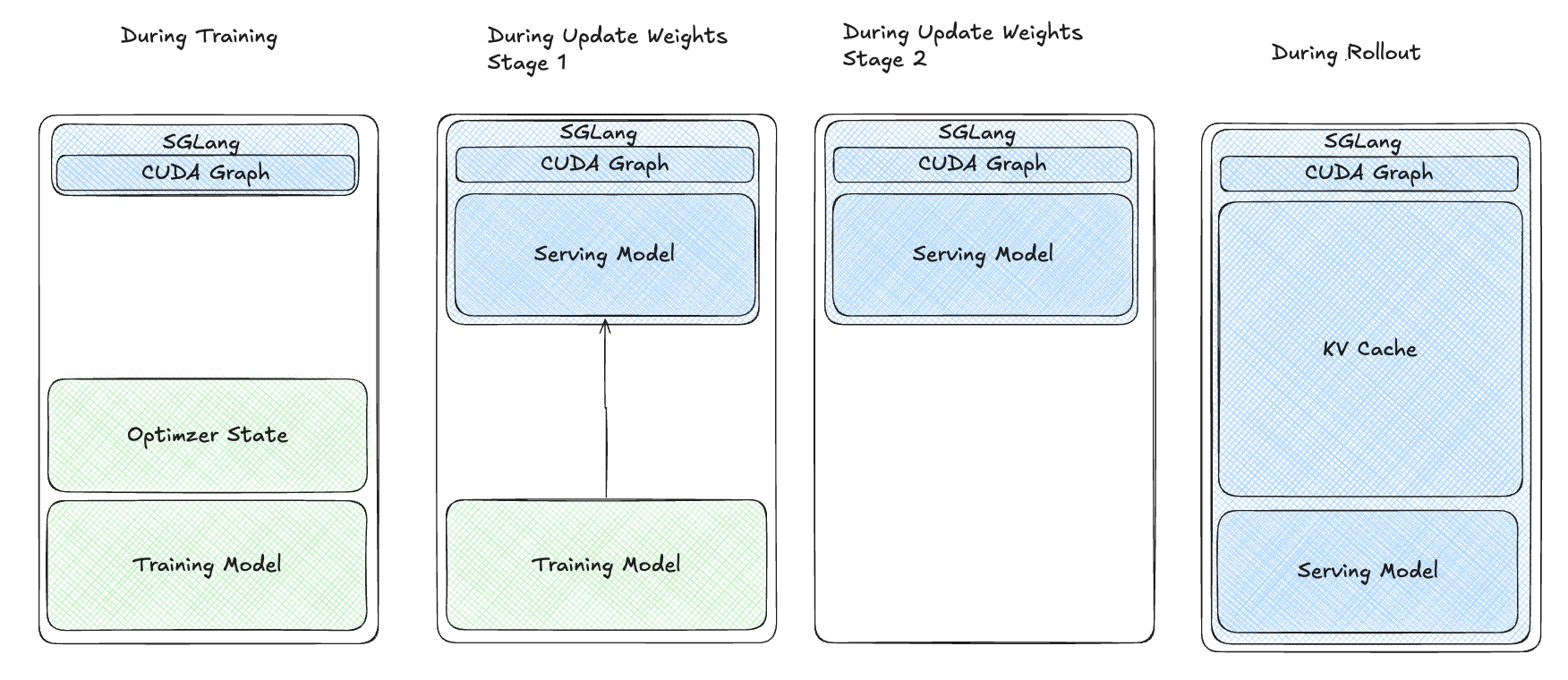
这种方法最小化了内存浪费,解决了 OOM 问题,并提高了大模型和高 KV 缓存比率的效率。
结论¶
通过本文概述的优化,我们成功地在 Qwen 32B 上训练了模型,KV 缓存内存比率为 0.9,使用了 8 个 H200 GPU - 这一成就最初是无法实现的。本文总结了 SGLang RL 团队的内存优化努力,为强化学习(RL)训练的高效内存管理提供了见解。我们希望它能作为理解和应对类似挑战的宝贵资源。
致谢¶
我们向 SGLang RL 团队和 verl 团队表示诚挚的感谢,特别感谢 Tom 开发了紧凑而强大的 torch_memory_saver 库,并为 SGLang 奠定了基础,以及 Chenyang 领导 SGLang RL 计划并提供关键指导和支持。