LLM 强化学习(RL)训练过程的性能与资源效率是 AI Infra 重点关注的内容。RL 的场景比预训练(或者 SFT)的工作流更长、协同工作的模块更多,容易出现资源利用率低的情况。Infra 的目标是在保证算法精度/效果满足前提下,应尽量去提升资源效率。本篇简单介绍 RL 训练中可能遇到的问题,并列举几个业界的解决方案。
训练的步骤¶
强化学习常见算法步骤:
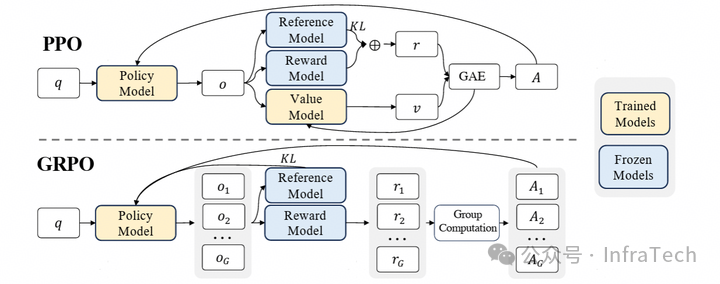
梳理出三个层:1 生成(Generation)、2 准备 / 推理(Preparation/Inference)、3 训练(Training)。
源自 HybridFlow 图片
到 AI Infra 关注的训练步骤大致是这样的:
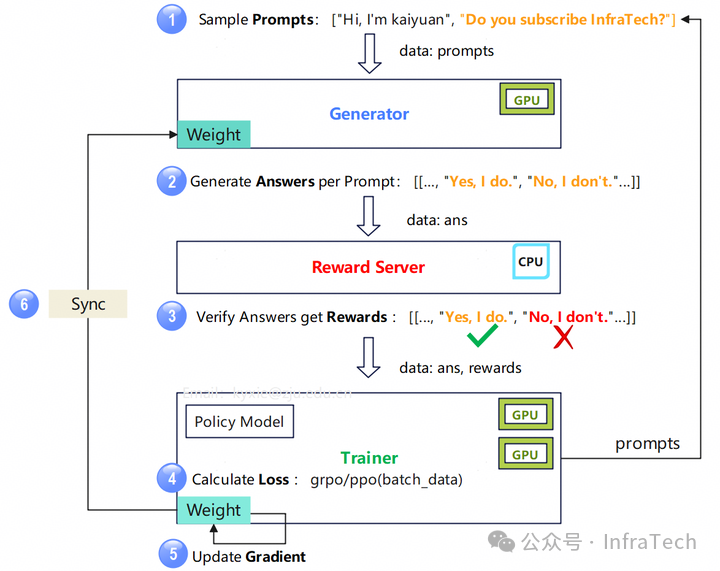
上图包含了:
-
生成模块(Generator):加载 Policy 模型运行推理任务,负责流程中 rollout 阶段,硬件资源一般是 GPU。
-
奖励模块(Reward Server):加载评价模型,模型参数固定,硬件资源 CPU。
-
训练模块(Trainer):训练 Policy 模型,运行参考模型。硬件资源 GPU。
大致有 6 个处理步骤:
-
提示词(Prompts):Trainer 生成提示词给到 Generator,数据大小 ;
-
答案(Answers):每一个 prompt 生成 个数据,输出数据 ;
-
奖励(Rewards):对 数据进行打分,得到奖励值 rewards;
-
损失(Loss):计算模型损失,函数可以是 grpo、ppo 等算法。
-
梯度(Gradient):计算模型梯度,更新模型权重。
-
同步(Sync):将 Trainer 的权重同步到 Generator 中。
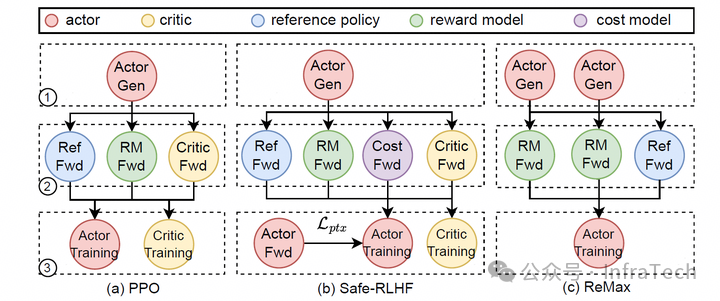
注意:此例的算法仅考虑了 Reward 模型,若选取的算法改变,步骤和资源分配也将发生改变。

PPO 算法,考虑 Critic、Reference 模型
存在问题 / 挑战¶
权重同步¶
训练与推理权重的传递理想中是这样的:
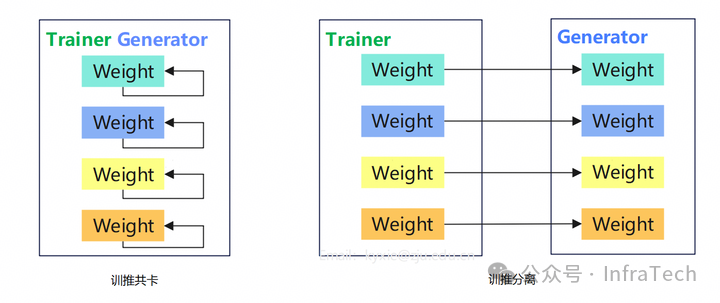
实际上可能是这样的:
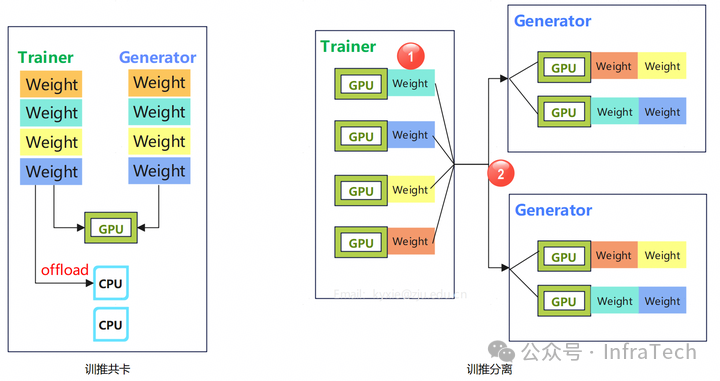
存在问题:
-
训推共卡(task-collocated)方案,由于显存不足,权重需要卸载到 CPU 上;
-
训推分离(task-separated/disaggregated)方案:1、分布式并行方案不一致让权重 size 不同;2、跨节点带宽小,多实例传输共用一条链路;
-
权重同步产生空泡(bubble):
- 精度差异:训练与推理的权重采用的精度格式不同。
除了上述提到的多实例传输链路带宽共用的情况外,还会出现多种实例链路并非一致情况:
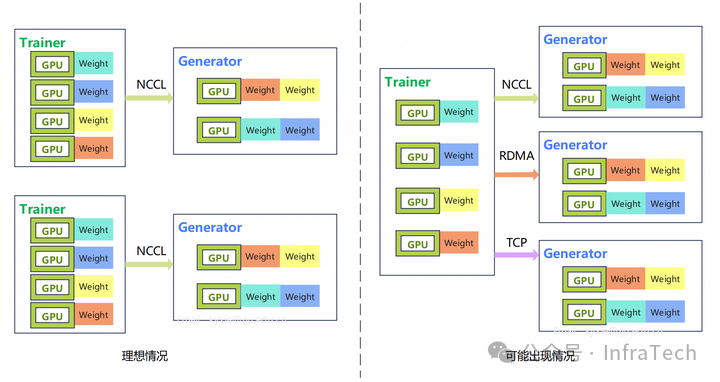
产生这种问题的可能原因:
-
不是所有训、推实例都在同一个 NCCL 网络平面下,跨节点之间仅支持 IB/RoCE 或者 TCP 平面传输;
-
训练、推理的 NCCL 版本不一致;
-
系统要求实例支持扩缩容,扩缩容导致实例之间的网络建链失败(一种系统 BUG)。
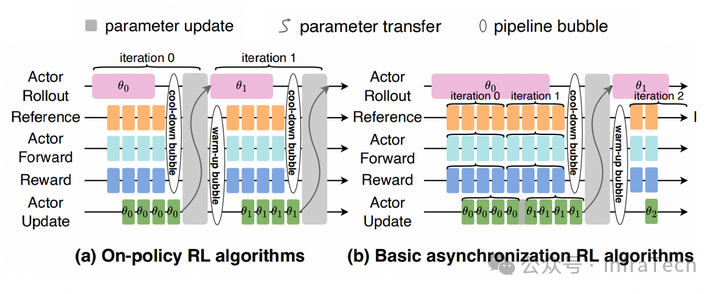
OnPolicy 的挑战¶
1、Rollout 的长尾 / 拖尾(Long-Tail):
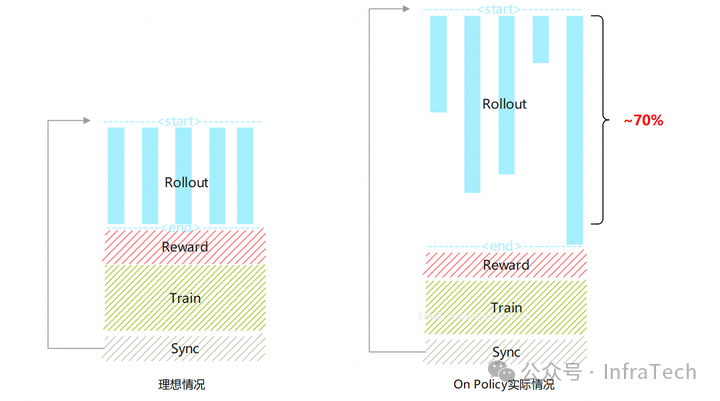
Rollout 阶段生成数据的结束时机不一致,存在短板效应。耗时占比可以超过 70%。
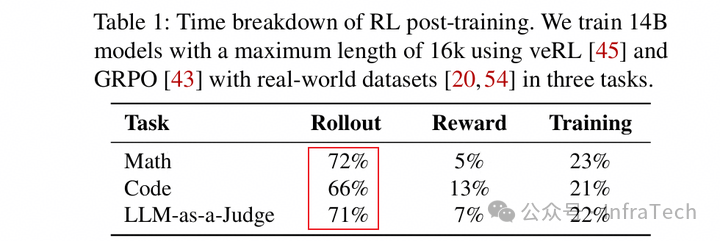
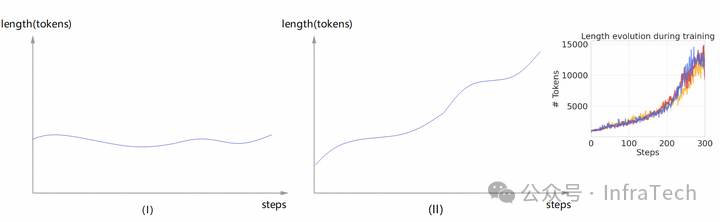
2、序列变化。序列长度随着训练进行会波动变化。当生成序列保持相对平稳时,如下图(I)所示对推理 rollout 的资源要求也是平稳的,但可能会出现(II)所示的情况,rollout 所需资源也得相应地提升。
性能提速方案¶
负载调整¶
根据 Rollout 的负载情况调整负载加载顺序,算法依然是 On policy,无精度损失。
负载均衡器。通过一个动态负载均衡器实现 DPLB(Data Parallel Load Balance),这个方法发挥出优势的条件:请求数量比较多(>>generator 数量),没有极端长度。
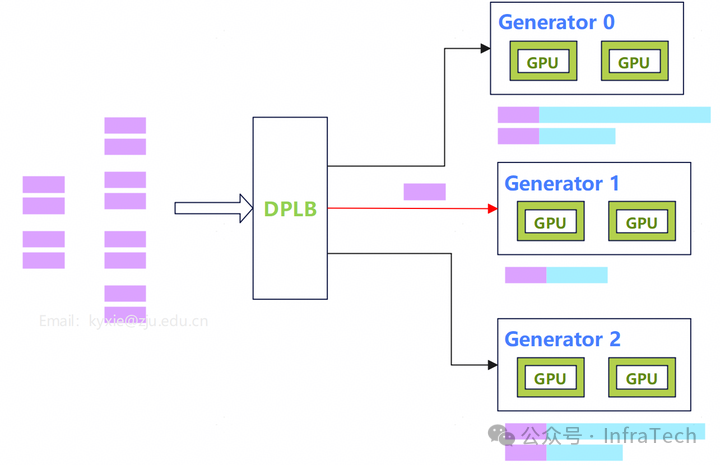
DPLB 给 Generator1 调度请求
我们团队尝试了该方法,在一定条件下提速收益可达 ~30%。
Tail Batching。根据生成长度组 batch,当 batch 里面出现了过长的数据,打断后放入队列,寻找相同长度数据组 batch 重新调度。
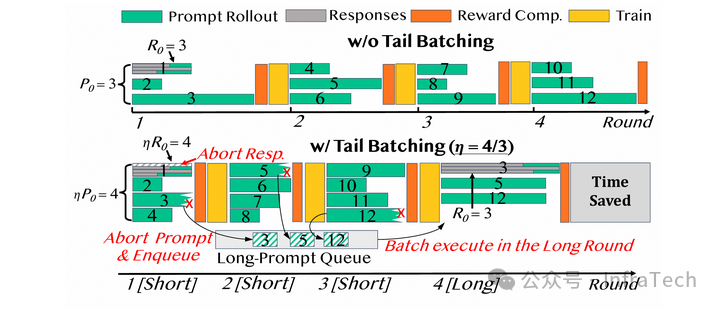
Tail Batching
步骤融合。将 rollout 与后续的模型操作(例如 PPO 算法的 Reward/Reference/Critic)进行融合。如 RLHFuse 提到的方案:rollout 阶段将零散的长尾数据打断后集中到部分 GPU 资源上,把 Ref.Infer、Crit.Infer、Rew.Infer 运算调度到 rollout 阶段释放出的资源中。使得 Generate 与 Inference 从串行,变为有部分重叠,从而提升效率。
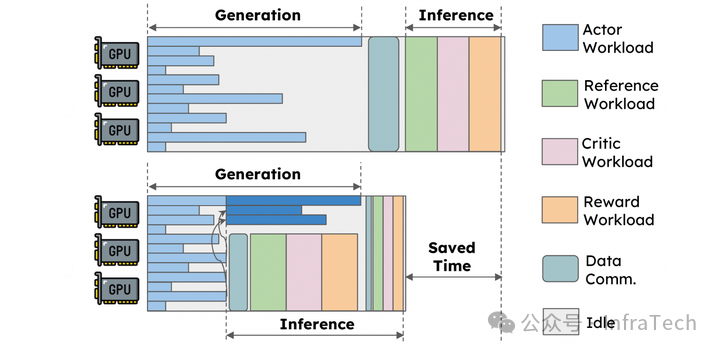
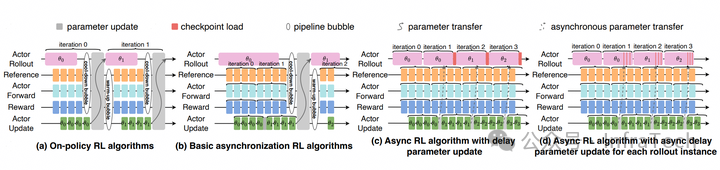
异步训练¶
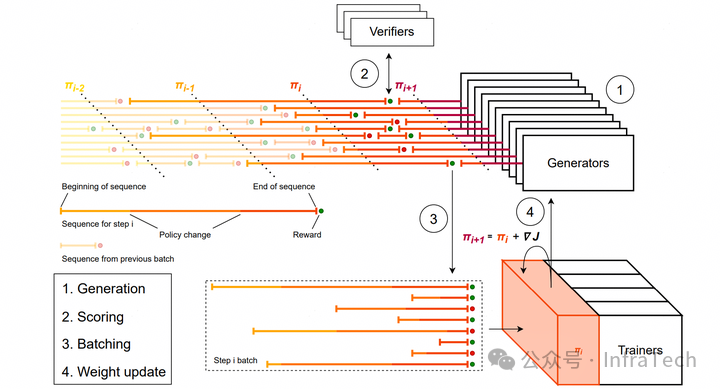
异步强化学习(Asynchronous Reinforcement),off-policy 方式,本轮训练的数据可能来自上一轮 / 上几轮的权重的生成。需要调整算法保证精度。
KV cache 保持。在 Magistral 中提到了 KV cache 保持的方式,其原理:当遇到过长的生成时,打断生成,但不释放被打断数据的 KV cache。下一轮权重更新后,继续上一轮的生成。单个序列数据可能混合了几个不同权重推理出来的结果。
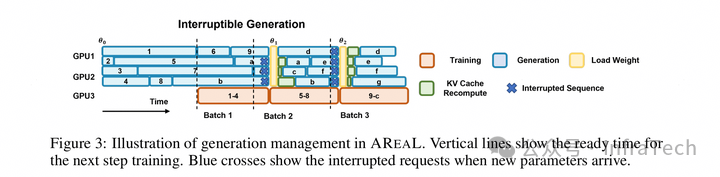
KV cache 重算。rollout 持续生成,当需要更新权重时才停止,并打断当前数据生成,未完成的数据下一轮重新推理,已生成的 KV cache 重新计算,如 AREAL 的异步流方法。
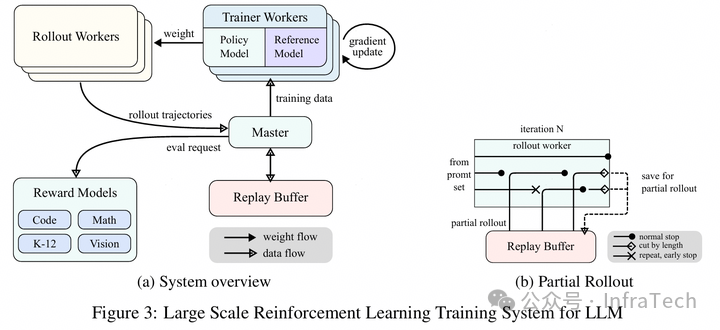
长序列分段处理。在 Kimi K1.5 中采用的策略是Partial Rollout,长序列会分段。大概原理:设置推理的最长 tokens 阈值,在一轮 rollout 中当一个序列计算 tokens 数超过该阈值时,该序列会被打断,并存入一个“replay buffer”中。在后面的rollout 过程中,当有序列推理结束,出现空闲资源时,从replay buffer 中拿出未计算完的数据继续推理。这个方式不涉及KV cache 保存/重算。为什么是“partial”?因为短序列不受影响。
权重同步¶
分离方案的权重同步¶
异步权重更新。允许 policy model 训、推之间权重异步更新,如 AsyncFlow 中提到方式,权重从 actor 的 train 到 rollout 传递更新,支持分实例异步操作。rollout 实例与实例之间运行的权重可以不一致。
AsyncFlow
统一的训推权重转换。面对训、推框架不同的并行策略、精度、格式,构建统一的转换层。如 asystem-awex 中提到的,在训练中配置权重写入器(WeightWriter)、推理中配置权重读取器(WeightReader),实现权重分片存储、传输和转换。
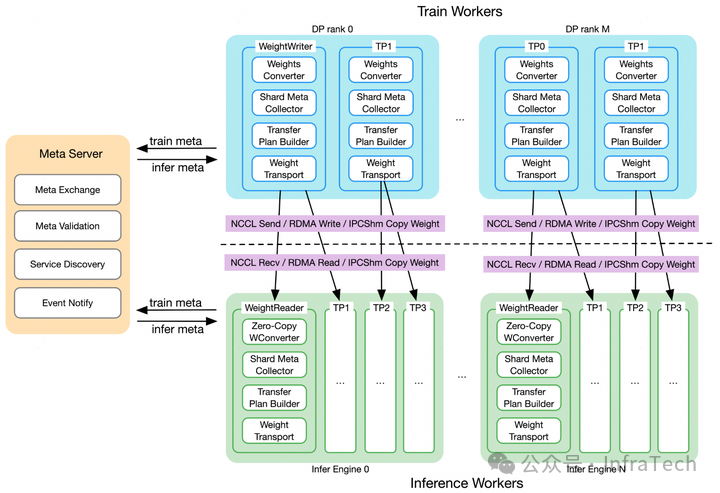
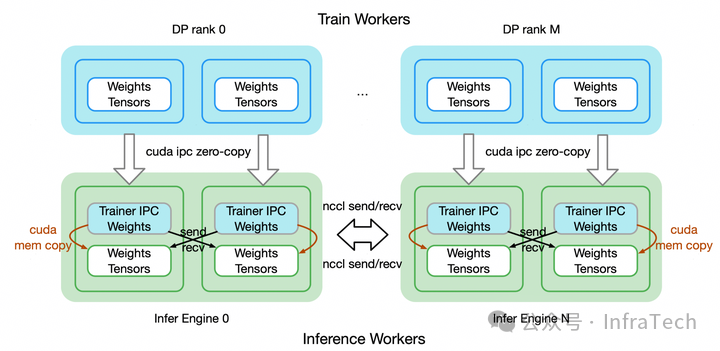
不同网络用不同传输模式。训练和推理的实例可能位于相同节点、也可能位于不同节点,数据传输的网络不一样需要采用不同的传输模式。比如 awex 提到的训、推之间先用 CUDA IPC 的 zero-copy 操作,然后推理实例之间进行 P2P 同步如下图所示。
共卡方案的权重同步¶
共享内存传递权重。如 K1.5 的 megatron 与 vLLM 的混合框架中,用一个通用模块 Checkpoint Engine 完成权重传输(解决不同 ProcessGroup 之间互通的问题)。权重的分片注册到一个公共位置,训练或者推理步骤结束时释放掉一些显存。训推引擎在一个 pod 中,共享 GPU 的资源。两个引擎中的 TP 切分策略存在差异,在加载时完成转换。
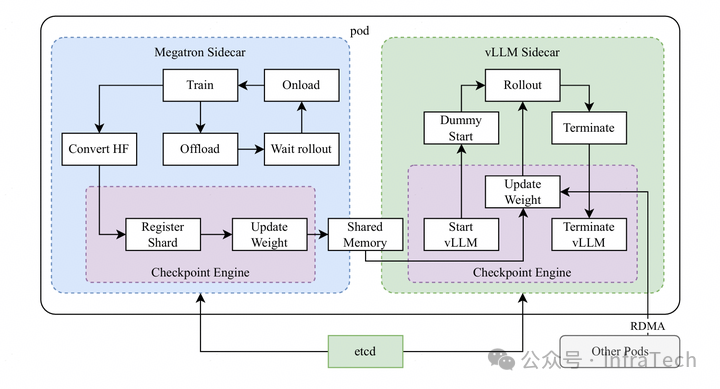
相比分离方案,共享权重方案的 H2D 会降低传输速度,需要做一定优化处理。
Rollout 提速¶
Rollout 性能取决于推理的运算速度。要降低 E2EL,其中 ITL 是大头。推理框架的下发效率、特性,算子等对速度都能构成影响。目前主流的两款框架 vLLM、SGLang 各有优劣,所以在 RL 架构中两种框架都能见到。
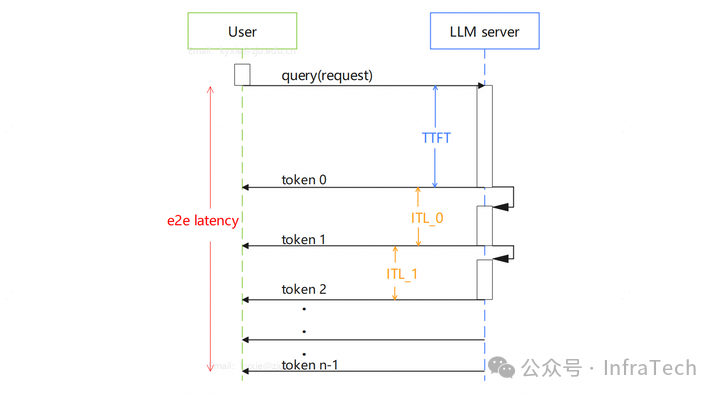
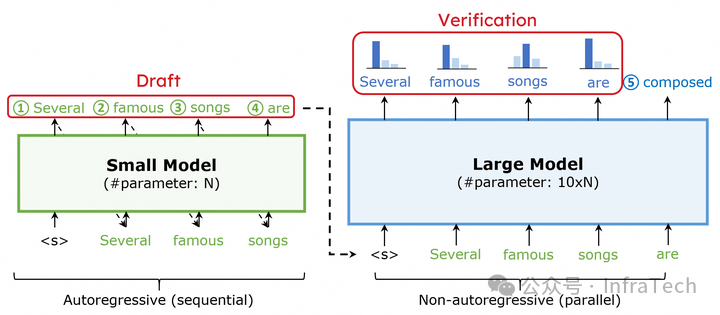
提速特性:如投机推理(Speculative Decoding),可以一次生成多个数据,对于一些短输入长输出的场景(prefill 2k -> decode 20k),能带来较大性能提升。
量化:在 rollout 优化的相关讨论中,提到了一种量化的方式”FlashRL: 8Bit Rollouts”。

这种可能对精度产生影响的方案,一般不会由 Infra 单方发起,需要与算法共同讨论。
框架下发速度:是指框架的调度器(scheduler)将任务从 CPU 侧下发到 GPU 侧的速度。这个是一个通用优化点,既能用于 rollout,也能用于推理部署。比如在 vLLM 中的多进程协同(scheduler 与 worker 在不同进程),multi-step 等特性。
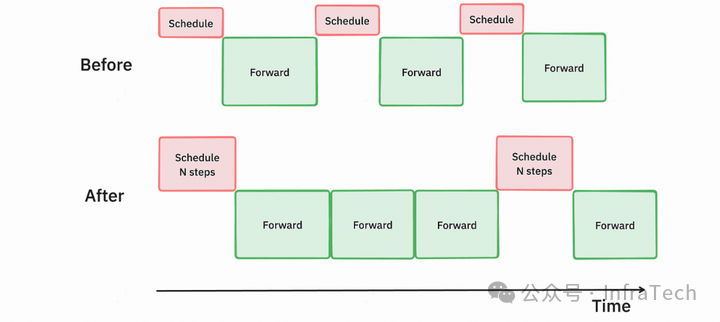
muti step
小结:与预训练动辄千卡 / 万卡规模相比,RL 的资源使用量比较少,目前 RL 性能问题还没有成为 AI 算法迭代的关键瓶颈。在 Infra 的性能优化工作项中,RL 性能优化工作一般排在预训练性能、推理性能之后。随着大家开始尝试扩大(scale up)RL 规模,寻找更好的训练效果,后续 RL 的性能关注度应该会逐步提升。