优质博客¶
- [LLM性能优化] 聊聊长文本推理性能优化方向 - 知乎
- Deploying DeepSeek with PD Disaggregation and Large-Scale Expert Parallelism on 96 H100 GPUs | LMSYS Org
- Implement Flash Attention Backend in SGLang - Basics and KV Cache · Biao’s Blog
- Unleashing the Power of Long Context in Large Language Models | by Aakash Tomar | Medium
超长上下文(Long Context / Long Sequence)推理面临四大核心挑战:显存爆炸、计算复杂度高、访存/通信瓶颈、延迟不可接受。为了解决这些问题,业界已经形成了一整套工程级优化技术栈(如 vLLM、SGLang、TensorRT-LLM 等系统所采用的方案)。本文将从体系化视角,全面梳理大模型超长上下文推理中的各种优化技术,帮助读者建立对这些技术的清晰认知。
一、问题本质:为什么长上下文这么难?¶
长上下文会让 Transformer 推理面临指数级增长的计算和存储需求。设:上下文长度为 ,隐藏维度为 ,注意力头数为 。
-
Attention 计算复杂度高
自注意力机制在处理长序列时计算量巨大。对于 长度的输入序列:
- Prefill(全量前向)阶段:计算复杂度约 ,因为需要计算 的完整矩阵并 softmax 后乘以
- Decode(自回归解码)阶段:每生成一个新 token,需要计算与所有已有 个 token 的注意力,复杂度约 。虽然单步是线性,但由于需要迭代 步生成,且每一步都依赖完整的 KV 缓存,这使解码总体计算仍非常庞大。
-
KV Cache 显存占用爆炸
为了避免重复计算,自注意力会缓存每层过往的 Key/Value(KV Cache)。KV 缓存大小近似 (2表示 Key 和 Value 两部分),随上下文长度线性增长。对于 128K 甚至 1M 长度的上下文,单层 KV 缓存就需要数 GB 显存!例如,对 LLaMA-70B 模型(80层,64头,头维 128)处理 128K 长度序列时,KV缓存总占用约 80GB(单层约 1GB)——几乎耗尽一张 A100 80GB 卡的容量。
-
Decode 阶段访存瓶颈
在自回归生成每个新 token 时,模型需要从每层的 KV Cache 中读取所有历史 个token的 Key/Value 用于 Attention 计算。这意味着每一步解码都要扫描一遍历史 KV,导致计算变成 memory-bound(受限于显存带宽)和 communication-bound(多卡时受限于通信)。即使 Attention 算子本身算力足够强,这种频繁的大内存访问和多 GPU 通信也严重拖慢了解码速度。
-
解码延迟挑战
由于 decode 阶段严格的自回归顺序,每个 token 生成都在等待前一个完成,无法并行。这使得长上下文下的输出延迟(latency)飙升。如果没有特别优化,长上下文模型往往 TTFT(首字延迟)和逐 token 延迟都不可接受,难以满足交互式应用需求。
综上,长上下文难在:计算量随序列平方增长,KV 缓存内存线性暴涨,访存和通信成瓶颈,生成时延线性累积。下面我们将介绍业界围绕这些难题发展出的五大类优化技术。
二、核心优化技术全景图¶
我们可以将超长上下文推理的优化手段分为五大方向,每一类技术都已经在主流推理框架中落地应用:
2.1 Attention 计算优化(算得更快)¶
长上下文下,Attention 计算的 开销是 Prefill 阶段的主要瓶颈。为提升 Attention 计算效率,业界提出了多种更快的实现:
-
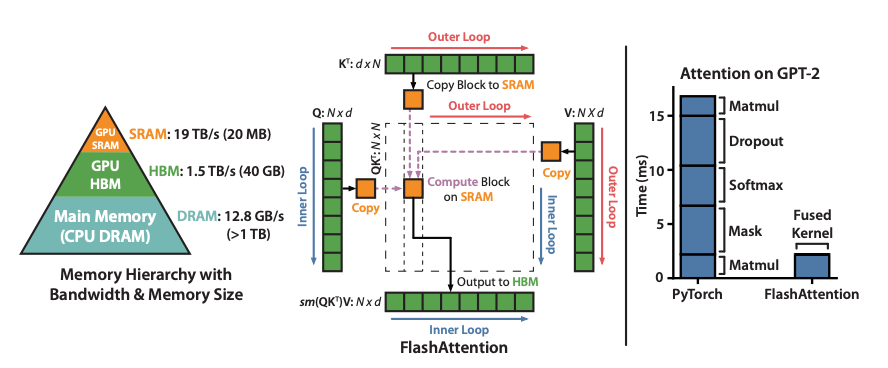
FlashAttention 系列(FA1/2/3): 这是近年来最受关注的 Attention 优化内核。
FlashAttention 通过分块计算和在高速片上 SRAM 复用来避免显式构建完整的 矩阵,并采用“在线”逐块 Softmax 归一化策略,大幅减少了 GPU 高带宽显存(HBM)的读写,极大提升了长序列 Attention 的速度。右图对比了未优化(PyTorch 标准 Attention)与 FlashAttention 的计算时间,可以看到 FlashAttention 将 Attention 算子的耗时显著缩短。
FlashAttention 的核心思想是 IO 优化:将注意力的计算按块(tile)分割,在高速的 SMEM 寄存器/片上存储器中完成 片块的乘积和归一化,避免反复在 HBM 读取大矩阵。这样 Prefill 阶段的 计算大量变为片上操作,大幅加速;Decode 阶段 FlashAttention 3(FA3)进一步针对生成场景优化了 kernel,实现极致高效的单步解码 Attention。
FlashAttention 已经有多个版本演进:FA1 注重 IO 高效,FA2 改进并行度和划分策略,FA3 专为推理设计,利用最新 Hopper 架构的 Tensor Core 异步执行和超长寄存器/片上内存,让解码场景的注意力计算达到了新的性能峰值。总的来说,FlashAttention 在 Prefill 和 Decode 阶段都有效,已成为现代 LLM 推理的标准配置。
-
块状/分块注意力(Block-wise / Chunked Attention)
这是另一类思路:将超长的序列按照长度划分为若干块,每次只对一个块内部或有限邻近块计算注意力,而非对全长序列计算。这类似于 Longformer、MosaicMPT 等模型的局部窗口注意力思想,通过限制 Attention 计算范围来降低计算复杂度和内存占用。例如将 128K 序列按每 1K 切块,只计算块内或相邻块间的 Attention,可将 复杂度近似降为 。这种 Chunked Attention 通常结合后文的 KV 分页或上下文并行一起使用,在不大幅牺牲模型效果的前提下,显著减少了长序列 Attention 的计算和存储开销。但需要注意这属于近似优化,会引入一点信息损失,工程上需要权衡使用。
-
稀疏注意力(Sparse Attention)
2.2 KV Cache 显存优化(存得更少)¶
面对超长上下文,KV 缓存的显存占用是生死线:如果不能优化 KV 缓存,长上下文几乎无法在单卡甚至多卡上运行。为此,业界发展了以下策略:
-
KV Cache 分块分页(Paged KV Cache)
这是 vLLM 系统的基石设计,被称为“PagedAttention”。其做法是不再按每个请求序列连续存储 KV,而是把 KV 拆分为小块(pages)分散管理。类似操作系统的虚拟内存分页,vLLM 引入了 KV 缓存管理器,将每个请求的 KV 按需分配若干固定大小的块,允许动态增长和回收,并通过“页表”映射实现逻辑上连续。这种设计带来多重收益:
- 消除显存碎片:传统连贯分配 KV 会造成严重的内外碎片。Paged KV 让每块 KV 可放置于任意闲置内存,避免预留长连续区,极大减少了内存碎片和“Swiss cheese”现象。
- 支持变长和并发:因为每请求按块动态分配 KV,不同请求的上下文长度可以不同,不再需要为最长序列预留统一大缓冲。未用完的块可立即用于其他请求,实现更高的批处理并发和显存利用率。实际测算显示,以前系统 KV 缓存有 60%-80% 内存浪费,而 vLLM 的 PagedAttention 把浪费降到不到 4%。
- 解锁超长上下文:Paged KV 配合其它并行技术,可以轻松支持 128K 甚至 1M 长度的上下文,在总显存固定的前提下存储如此海量的 KV 成为可能。
简单来说,Paged KV类似于把KV缓存“虚拟化”了:按块管理,灵活调度。这也是 vLLM 名字中“virtual LLM”的由来之一。
-
KV Cache 压缩与量化
另一条思路是降低每个 token 的 KV 存储精度,从而减小内存占用。典型做法是将 KV 从 FP16 压缩为更低位宽,如 FP8 或 INT8 甚至 INT4。可以仅量化 Value,或 Key/Value 一起量化。以 FP8 为例,vLLM 支持将 KV 缓存存为 FP8 格式,从而占用缩小一半。在这种实现中,存储时对 KV 张量按比例缩放后量化为 FP8,需要用时再解码回 BF16 参与计算。由于注意力计算最终用的是解量化后的高精度值,所以精度损失很小,实测 E4M3 格式 FP8 对推理准确度仅有极微小影响。KV 量化的权衡是显存占用下降换取极小的精度下降,通常在工程上是可以接受的。这种方法可以让每张卡存储约双倍数量的 token。除了 FP8,INT8/INT4 等定点量化也有研究。需要注意的是,目前一些框架 KV 量化主要提升吞吐和容量,对单 token 延迟帮助不大,因为解码时还需实时解量化操作。未来随着硬件支持,也有望出现端到端的量化注意力内核进一步减少这方面开销。
-
KV Cache Offload(异构存储卸载)
当上下文特别长或并发很多时,即使有分页和量化,KV 缓存总量仍可能超出 GPU 显存。这时可以考虑将冷门的 KV 缓存转移到 GPU 外。典型策略是:“热 KV 留 GPU,冷 KV 转 CPU/NVMe”。比如最近的一些系统(如 LMCache)支持将不活跃会话或较久之前的 token 的 KV 通过 PCIe/NVLink 转移到 CPU 内存,甚至NVMe SSD。当需要用到时再预取回来。这样可以释放宝贵的 GPU 显存,显著提高单机能支持的上下文数量或长度上限。当然,Offload 的代价是每次取回会有额外延迟,所以一般在用户停顿、长时间不用的情况下才做,或者配合异步 IO 和流水线隐藏这部分延迟。总之,KV Offload 通过利用更廉价的大容量存储(CPU 内存/磁盘)来扩展 KV 容量,是实现超长上下文和多会话共存的关键技术之一。
2.3 上下文并行(Context Parallel,CP)¶
当单卡无论如何也放不下超长上下文的计算和 KV 时,就需要多卡协作从序列维度拆分工作,这就是“上下文并行”。这是近一年长上下文支持的最重要突破之一,直接让 128K/1M 这样的长度成为可能。
-
Context Parallel (分段并行)
PCP & DCP: 传统的张量并行 (Tensor Parallel) 是沿隐藏维度拆分模型权重和计算,复制整个序列在每卡上计算;而上下文并行则是沿序列长度方向拆分,让多张卡各自保存/计算序列的一部分,从而不再每卡都存完整 KV。
- PCP(Prefill Context Parallel): 用于提示的前向阶段。当输入序列极长时,可以将序列等分成 段,分给 张 GPU 分别并行计算每段的 表示。最简单策略是“部分 Query,全量 KV”:每卡算自己那段 token 的 Q、K、V,然后所有卡汇集 K/V,再各自完成对本段 Q 的注意力输出。这样总计算量几乎平均分摊,大幅加快了 Prefill 处理长输入的速度。如果序列过长连 K/V 也放不下一整份,可以更激进地采用“部分 Query,部分 KV”策略,借助环形通信(Ring Attention)逐块交换 KV 计算。PCP 的收益在于降低单卡计算和显存占用,并将 Prefill 的长序列计算延迟按长度切分并行化,显著缩短 TTFT。
- DCP(Decode Context Parallel): 用于生成解码阶段。当单卡 KV 缓存放不下整个长历史时,采用 DCP 可以沿序列长度维度将 KV 缓存切分到多卡。例如有 个注意力头,一个请求已有 个token,那么原本每卡需存 个 KV 条目;现在如果有 2 卡 DCP,每卡各存一半 token 的 KV,即每卡存 条。更一般地,DCP 大小 表示每张卡只保存 的历史 KV。这样单卡 KV 显存需求降为原来的 ,等价于多卡共同提供更大 KV 存储容量。解码时,各卡并行对自己那部分 KV 计算注意力分值,然后通过 All-Reduce 汇总结果,保证最终语义与单卡计算完全等价。DCP 的直接效果是显著降低解码时 KV 内存压力,从而解锁超长上下文(如 128K/1M)的解码可能性。代价则是需要额外的通信:每步解码的注意力输出需要跨卡同步,以及某些非注意力层计算需要全局聚合。因此 DCP 通常配合高带宽通信(NVLink/NVSwitch/RDMA)以及高效Attention kernel(如 FlashAttention 的 Online softmax 版本)才能发挥最佳效果。目前 vLLM、SGLang 等开源推理引擎都已深度支持上下文并行。
小结: 上下文并行的引入,使得“单卡放不下,多卡拆着放”成为可能:Prefill 通过 PCP 并行加速长输入处理,Decode 通过 DCP 分担 KV 存储压力。这两者结合,让 128K 乃至更长上下文的推理在 GPU 集群上成为现实方案。
2.4 Decode 阶段专项优化(降低生成延迟)¶
针对解码生成逐 Token 串行、依赖 KV 的特点,有一些专门为降低延迟和提高解码效率设计的优化:
-
多查询或分组查询注意力(Multi-Query / Grouped-Query Attention, MQA/GQA)
这是对 Transformer 注意力结构的改动,以减少 KV 缓存的维度。通常 Transformer 的注意力是多头(例如 H=16 头),每个 Attention head 都有自己独立的 投影。而 Multi-Query Attention 提出:共享所有头的 Key/Value,只保留一个公共的 K/V 表示,多个 Query 头共用这一组 K/V。极端情况下 MQA 就是只有 1 组 K/V(即 K/V 头数 =1),那么 KV 缓存大小直接从原来的 倍降为 倍。这对解码阶段意义重大——KV 缓存减少意味着每步解码需要读取的历史 KV 数据量减少了 倍,从而访存开销大幅下降,加速生成。许多大型模型(如 Google 的 PaLM 系列)就采用了 MQA 来支持长序列和高效解码。
Grouped-Query Attention (GQA) 则是介于 MHA 和 MQA 之间的一种折中:把 个注意力头划分成 组,每组共享一套 K/V(等价于 K/V 头数变为 )。当 时,就减小了 KV 缓存和访存。GQA 在一些模型(如 Llama2-chat 版)中有使用,其在尽量保证精度的前提下降低 KV 开销,被视为比 MQA 更平衡的方案。
总的来说,MQA/GQA 可以视为“用更少的 K/V 头完成注意力”。它们对解码阶段优化尤为显著,因为这时 KV 缓存的读写和存储是主要瓶颈。实际效果方面,据报告采用 MQA 的模型在相同硬件上解码吞吐可提升 1.3-2 倍左右,而对模型准确度的影响很小(但纯 MQA 有时略降精度,GQA 可平衡)。
-
推测解码(Speculative Decoding)
这是通过引入小模型来加速大模型解码的策略。基本思想是:用一个小模型(draft model)先预测接下来的 n 个 token,大模型一次性验证这些预测。如果小模型预测正确,大模型相当于一下生成了多个 token;若有错误,大模型会识别纠正,但无论如何都比每次只生成一个 token 快。因为小模型速度快,可以“大胆猜”,大模型则少做很多步计算。
举例来说,假设我们用一个 6 亿参数的小模型来给一个 700 亿参数的大模型做草稿。小模型可能一下猜出后面 5 个词,大模型拿这 5 个词过一遍自己的 forward,在一个前向中验证 5 个 token。如果前面 3 个是对的,后面第 4 个错了,那大模型实际生成了 3 个token,小模型再继续从第 4 个往后猜。通过这种机制,可以将大模型生成步数减少一半以上,从而加速 2-3 倍而且理论上不损失准确度。
推测解码的难点在于选取合适的小模型——要足够快又不能太“不靠谱”。业界也探索了不需要单独小模型的方案,例如 Medusa/Eagle 等直接在大模型内部增加并行分支来预测多个 token。总之,Speculative Decoding 非常适合长上下文+长输出场景,因为越长的生成越能摊薄验证开销。
-
双批次重叠(Two-Batch Overlap,TBO)
这是在分布式多卡环境下重叠通信和计算以降低解码延迟的一种技巧。其做法是将一次解码请求的 batch 拆成两个 micro-batch 流水执行:当 micro-batch 1 正在 GPU 上进行 Attention 计算时,micro-batch 2 可以同时在网络上进行 KV、权重通信调度,为下一步计算做准备。这样避免了 GPU 干等通信的时间。
通俗讲,TBO让解码流程像“交替双手剪刀”一样工作:一手算本步,一手取下步,实现计算-通信的并行。它的效果是降低每步解码等待,使硬件资源利用更充分,同时有效将峰值内存需求平摊到两批中(每 micro-batch 只有原来一般大小)。需要注意 TBO 实现上会增加代码复杂度和同步难度,但通过好的抽象设计可以减小维护成本。对于大 batch 长序列推理,TBO 可以在不改变算法前提下显著隐藏通信开销,降低分布式解码的总延迟。
2.5 系统与通信层优化(让多 GPU 高效协同)¶
最后一类是从系统架构和底层通信出发的优化手段,它们不是直接改变模型计算逻辑,而是为上述各种并行和优化提供高效的实现保障:
-
高速互连通信(RDMA / NVLink / NVSwitch)
当使用张量并行 (TP)、上下文并行 (CP) 或专家并行 (EP) 时,不可避免会有大量 GPU 间通信(如 All-Reduce 聚合梯度/输出,All-Gather 广播 KV 等)。为降低通信对性能的拖累,现代 GPU 集群配备了高速互连:单机 8 卡常用 NVLink/NVSwitch 提供每卡数百 GB/s 直连带宽,多机集群则使用 RDMA (RoCE / InfiniBand) 通过网卡直接 GPU 直连通信。这些高速通道确保了像 DCP 这样的跨卡 KV 合并不会成为瓶颈。同时,大模型集群通常会精心规划通信拓扑,尽量在同一 NV Switch 域内完成大部分 All-Reduce,跨机尽可能压缩通信量,以充分利用 RDMA 带宽。没有这些互连技术,像前述上下文并行、双批次重叠等方案都很难有实际意义。
-
Prefill-Decode 分离架构(PD Disaggregation)
这是为高吞吐+长上下文服务打造的系统级优化,被认为是工业部署的“标配”方案之一。其核心思想是将原本在同一 GPU 上串行执行的 Prefill 和 Decode 两阶段拆解到不同的 GPU 资源池中各自执行。原因在前面也分析过:Prefill 和 Decode 的资源瓶颈截然不同,一个重计算、一个重内存,并且混跑时互相干扰效率。通过物理上分离:部署算力强大的 GPU 专门跑 Prefill,显存超大的 GPU 专门跑 Decode,分别优化 TTFT 和 ITL,就能兼顾两者。
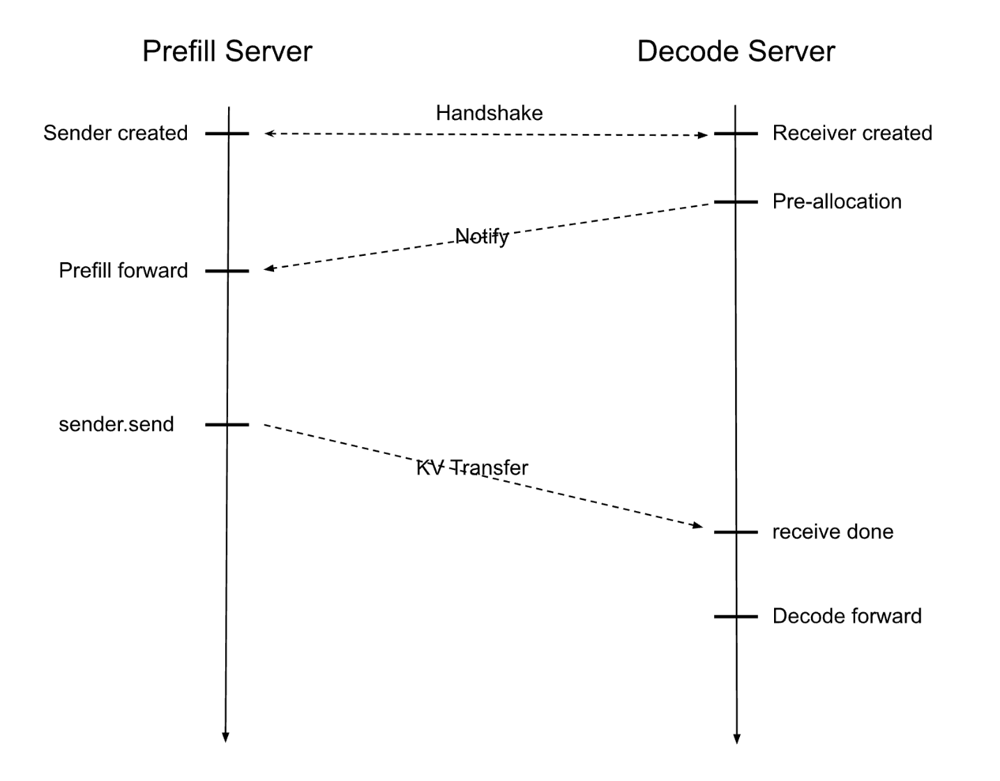
SGLang 中的 Prefill-Decode 解耦示意。左侧“Prefill Server”负责计算完整输入的前向并产生 KV 缓存,右侧“Decode Server”预先分配好 KV 空间,二者通过高速网络建立连接(RDMA 队列对),Prefill 算完后将 KV 数据直接传输给 Decode 服务器,后者随即开始迭代生成输出。这种架构让两阶段各自利用最优硬件资源,互不打扰。
PD分离的实现需要解决 KV 缓存传输问题——这通常通过 RDMA 等技术实现零拷贝高速传送。例如 SGLang 的实现中,Prefill 端通过 RDMA 把 KV 缓存直接写入 Decode 端 GPU 内存,采用后台线程异步传输以不阻塞主计算流程。NVidia 的 TensorRT-LLM 也提供了类似的 Disaggregated Serving 模式,并支持将 KV 传输与计算重叠以进一步提高效率。实际效果方面,PD 分离在高并发场景下大幅提高了吞吐延迟表现,据报道相比传统单引擎可提升 1.7~2 倍性能。需要注意 PD 分离在低并发短上下文时未必有优势,部署时需评估开销平衡。
总的来说,Prefill-Decode 分离为长上下文模型的服务部署提供了更灵活的异构伸缩手段——我们可以独立扩展 Prefill 算力或增加 Decode 内存节点,并通过高效互连让它们协同完成同一请求。
-
CUDA Graph 和内核融合
最后但同样重要的是,在 decode 等小批量高频调用场景下,CPU 启动 kernel 的开销本身会显著影响延迟。CUDA Graph 是一种让一系列 GPU 操作预先记录并一次性启动的方法,可极大减少每步推理时的驱动开销。在固定形状的解码循环中,可以使用 CUDA Graph 将每步涉及的 kernels(包括 Attention、MLP、拷贝等)Capture 为图,后续直接 Replay,大幅降低了 Kernel Launch overhead,对稳定低延迟非常关键。许多框架在 decode 阶段都强制使用固定 batch size 和序列长度的 Kernel 以启用 CUDA Graph。例如 SGLang 在 decode 采用“Low-latency dispatch”模式正是为了适配 CUDA Graph 运行。除了图模式,内核融合(Kernel Fusion)也是常用手段,将多个小 kernel 合并为一个以减少 launch 次数。比如将 RoPE 位置计算、KV 写入、Attn Softmax 等融合。最近的 FlashAttention-3 也把很多操作融合进单 kernel。总之,这些底层优化并不改变算法,但有效削减了软件开销,在需要极限低延迟的场景下是不可或缺的。
不同推理阶段和应用场景,对应的主要瓶颈和解决方案可总结如下:
| 阶段 | 瓶颈问题 | 核心优化技术 |
|---|---|---|
| Prefill(全序列前向) | 计算量 巨大 | FlashAttention 系列、PCP 并行 |
| Decode(自回归解码) | KV 缓存显存不足,访存慢 | DCP 并行、MQA/GQA 减少 KV、KV Offload |
| 服务并发 | 吞吐 & 并发受限,碎片严重 | 分页 KV 缓存、PD 分离架构、批次调度优化 |
在实际系统中,这些技术往往是组合使用的,以达到既快又省的目标。
三、终极组合:工业级最优解¶
综合上面的讨论,当前业界在超长上下文大模型推理上追求的最强组合方案包括:
- FlashAttention-3(高效 Attention 计算内核)
- Paged KV Cache(分页管理 KV,大幅提升显存利用)
- Context Parallel(PCP + DCP,实现多卡分担长序列计算和存储)
- MQA/GQA(减少 KV 维度,降低解码访存和显存)
- KV Cache Quantization/Offload(KV 缓存低精度存储或移出 GPU,进一步节省显存)
- 高速互连 + CUDA Graph (RDMA/NVLink 保障通信,图模式降低开销)