上个月,我参加了由 GPU MODE 主办的 AMD 分布式挑战赛。这对我来说非常令人兴奋,因为这是我第一次学习如何编写多 GPU 内核!尽管我通过 all-reduce 和 reduce-scatter 等集体原语对 DDP 和 FSDP 的工作原理有初步了解,但我不知道可以直接在内核中执行远程内存访问!这为多 GPU 优化(特别是计算与 GPU 间通信的重叠)开辟了许多机会。
这篇博客文章的结构是我关于第 1 个问题——All-to-All 内核的工作日志。您可以在 gpu-mode/reference-kernels 查看完整的问题描述,包括参考内核。我还发布了我在比赛期间开发的所有混乱解决方案,未做任何进一步润色(主要是因为懒得做),位于 gau-nernst/gpu-mode-kernels。
问题描述¶
单 GPU MoE¶
在描述问题之前,让我们简要回顾一下混合专家(MoE)模型的架构。MoE 层通常包含多个专家,在运行时每个 token 只有部分专家被激活。有一个小型**路由器(router)**决定为特定 token 选择哪些专家。DeepSeek-V3 为每个 token 激活 256 个总专家中的 8 个。
在实现层面,假设我们正在处理 个 token,那么我们有以下张量:
- 输入 token,形状
(M, dim) - Top-k 索引显示每个 token 选择了哪些专家,形状
(M, topk) - Top-k 权重用于在每个选定专家处理其输入份额后进行加权平均,形状
(M, topk)
当 较大时,输入数据的布局不理想——分配给特定专家的 token 可能在输入 token 张量中分散各处,使得高效数据加载变得困难。这个问题的常见解决方案是将属于同一专家的 token 分组在一起。对于单 GPU 情况,vLLM 称之为 moe_align_block_size()(取自 SGLang?)。
- 我不知道这个命名的历史背景,但感觉专注于“对齐块大小”方面有点奇怪(如果我没记错的话,它会填充专家边界,使每个专家的输入是
BLOCK_M的倍数)。我认为这无论如何都不是必要的。
分组 token 后,我们可以执行分组 GEMM,这是一种在一个内核中执行多个矩阵乘法的花哨说法。这很重要,因为我们不想单独启动 256 个 GEMM 内核,每个可能只执行一个小型 GEMM。然后,所有专家的结果可以发送回其原始位置,按它们的 topk_weights 缩放,并在 topk 个 token 上求和。
- 当我们使用特定映射将输入 token 转换为分组 GEMM 布局时,这是一个**收集(gather)操作。当我们使用相同映射恢复原始布局时,这是一个分散-归约(scatter-reduce)**操作。我们有一个“归约”,因为每个原始 token 被索引
topk次,因此会有topk个来自分组 GEMM 输出的 token 返回到同一位置。

单 GPU MoE 中的 token 重排。收集将分配给同一专家的 token 分组在一起。分组 GEMM 执行 MLP。分散-归约将结果聚合回原始 token 位置。
多 GPU MoE¶
在使用专家并行(EP)的多 GPU 情况下,与上述算法没有太大不同,尽管它们有新名称。dispatch 将 token 发送到它们各自的专家,这些专家现在分布在 GPU 之间。combine 将分组 GEMM 输出发送回其原始 GPU 和位置。
EP 通常与数据并行(DP)一起启用。每个 GPU 持有一个不相交的 token 集合,即输入数据被分片。dispatch 将数据从所有 GPU 发送到“所有”其他 GPU,类似地 combine,因此得名 all-to-all。

多 GPU MoE 中的 token 重排。此图与单 GPU 图完全相同。唯一的区别是表示跨 GPU 边界的额外空间。
问题在于实现 dispatch() 和 combine() 内核。听起来足够简单!
优化的纯 PyTorch 解决方案¶
这个参考内核相当慢,因为有很多 Python 循环。消除它们是我的第一个目标。
我之前花了一些时间研究 MoE 内核,因此我知道**排序(sorting)**是一种将属于同一专家的 token 分组在一起的方法。单 GPU 版本可以如下实现。
def moe(inputs: Tensor, moe_weights: Tensor, topk_indices: Tensor, topk_weights: Tensor):
# inputs: (M, dim)
# moe_weights: (num_experts, dim, dim)
# topk_indices: (M, topk)
# topk_weights (M, topk)
M, dim = inputs.shape
num_experts, _, _ = moe_weights.shape
_, topk = topk_indices.shape
# notice we flatten the indices tensor.
sort_indices = topk_indices.view(-1).argsort() # (M * topk,)
# get the token position in `inputs`, then perform gather.
sorted_pos = sort_indices // topk
grouped_gemm_inputs = inputs[sorted_pos] # (M * topk, dim)
# count number of tokens per expert to determine expert boundaries.
# your actual grouped GEMM kernel may require a different layout/metadata.
experts_count = topk_indices.view(-1).bincount(minlength=num_experts)
cu_experts_count = experts_count.cumsum(dim=0).to(torch.int32)
# perform grouped GEMM.
# in an actual MoE, each expert is an MLP, not just a matmul.
grouped_gemm_outputs = torch._grouped_mm(
grouped_gemm_inputs,
moe_weights.transpose(-1, -2),
cu_experts_count,
)
# apply topk weights. this should be fused with scatter-reduce instead.
grouped_gemm_outputs *= topk_weights.view(-1)[sort_indices].view(-1, 1)
# perform scatter-reduce to aggregate the tokens to their original positions.
outputs = inputs.new_zeros(M, dim)
sorted_pos_expanded = sorted_pos.view(-1, 1).expand(-1, dim) # scatter_add_() does not broadcast
outputs.scatter_add_(dim=0, index=sorted_pos_expanded, src=grouped_gemm_outputs)
return outputsdef moe(inputs: Tensor, moe_weights: Tensor, topk_indices: Tensor, topk_weights: Tensor):
# inputs: (M, dim)
# moe_weights: (num_experts, dim, dim)
# topk_indices: (M, topk)
# topk_weights (M, topk)
M, dim = inputs.shape
num_experts, _, _ = moe_weights.shape
_, topk = topk_indices.shape
# notice we flatten the indices tensor.
sort_indices = topk_indices.view(-1).argsort() # (M * topk,)
# get the token position in `inputs`, then perform gather.
sorted_pos = sort_indices // topk
grouped_gemm_inputs = inputs[sorted_pos] # (M * topk, dim)
# count number of tokens per expert to determine expert boundaries.
# your actual grouped GEMM kernel may require a different layout/metadata.
experts_count = topk_indices.view(-1).bincount(minlength=num_experts)
cu_experts_count = experts_count.cumsum(dim=0).to(torch.int32)
# perform grouped GEMM.
# in an actual MoE, each expert is an MLP, not just a matmul.
grouped_gemm_outputs = torch._grouped_mm(
grouped_gemm_inputs,
moe_weights.transpose(-1, -2),
cu_experts_count,
)
# apply topk weights. this should be fused with scatter-reduce instead.
grouped_gemm_outputs *= topk_weights.view(-1)[sort_indices].view(-1, 1)
# perform scatter-reduce to aggregate the tokens to their original positions.
outputs = inputs.new_zeros(M, dim)
sorted_pos_expanded = sorted_pos.view(-1, 1).expand(-1, dim) # scatter_add_() does not broadcast
outputs.scatter_add_(dim=0, index=sorted_pos_expanded, src=grouped_gemm_outputs)
return outputs我们可以利用这个想法来改进参考内核。在 dispatch() 中,每个 GPU 可以对其本地 token 进行排序并进行专家计数。然后,所有 GPU 集体执行非均匀 all-to-all(dist.all_to_all_single() 在 PyTorch 中)以获得分配给其本地专家的 token。实际上,这与参考内核相同,只是用 token 排序替换了 token 重排阶段的 Python 循环。
all2all 之后,token 位于其分配的 GPU 中,但未完全按其本地专家分配排序。这不是大问题:我们可以进行另一次排序以获得正确的分组 GEMM 输入布局。
- token 在每个源 GPU 组内部分排序,但如果没有自定义内核,我们无法利用这一事实。

调度的纯 PyTorch 实现。
由于此问题专注于 dispatch() 和 combine() 内核,分组 GEMM 用简单的逐点乘法模拟。
对于 combine(),如问题描述部分所述,它是 dispatch() 的逆操作。我们在 dispatch() 中执行两次收集,一次在原始 GPU 中,一次在分组 GEMM GPU 中。因此,在 combine() 中,我们也按相反顺序执行两次分散。查看上图,您可以反转箭头方向以获得 combine() 的流程。
这是我的 submission_v2.py。在排行榜上,此版本达到 1,311μs,而参考内核为 93,540μs。这种加速并没有太大意义,因为参考实现是故意设计得很差的。此时,我认为纯 PyTorch 实现已经没有多少提升空间了。因此,我开始研究 HIP 实现。
多 GPU 编程简介¶
点对点(P2P)¶
在讨论自定义 HIP 内核之前,我们先来谈谈点对点(P2P)和对称内存,这是多 GPU 通信的基本构建模块。P2P 内存访问可以大致理解为设备能够读取和写入其他设备的内存。这非常强大,因为我们可以编写自定义内核,直接以任何我们想要的模式执行远程内存访问,而无需启动单独的通信内核或发出直接内存访问(DMA)命令。讽刺的是,我阅读了 CUDA C++ 文档来理解 MI300X 上的 P2P 使用,尽管这也意味着 AMD 在 HIP 中镜像 CUDA API 的策略有一些好处。
使用 P2P 非常简单。
constexpr int WORLD_SIZE = 8;
int main() {
int rank = ...; // assigned GPU rank
CUDA_CHECK(cudaSetDevice(rank)); // switch to this particular GPU's CUDA context
// on each GPU, allocate memory and get its memory handles
char *ptr;
int size = 1 << 30; // 1 GiB
CUDA_CHECK(cudaMalloc(&ptr, size));
cudaIpcMemHandle_t h;
CUDA_CHECK(cudaIpcGetMemHandle(&h, ptr));
// exchange memhandles somehow
// since we have PyTorch, we can just call all-gather
cudaIpcMemHandle_t all_handles[WORLD_SIZE];
// "open" memory handles i.e. map remote memory addresses
// in the current CUDA context's address space.
char *all_ptrs[WORLD_SIZE];
for (int i = 0; i < WORLD_SIZE; i++) {
if (i == rank)
all_ptrs[i] = ptr;
else
CUDA_CHECK(cudaIpcOpenMemHandle(reinterpret_cast<void **>(all_ptrs + i),
all_handles[i],
cudaIpcMemLazyEnablePeerAccess));
}
// then you can pass pointers of remote memory to kernels
// and deference them as usual
}constexpr int WORLD_SIZE = 8;
int main() {
int rank = ...; // assigned GPU rank
CUDA_CHECK(cudaSetDevice(rank)); // switch to this particular GPU's CUDA context
// on each GPU, allocate memory and get its memory handles
char *ptr;
int size = 1 << 30; // 1 GiB
CUDA_CHECK(cudaMalloc(&ptr, size));
cudaIpcMemHandle_t h;
CUDA_CHECK(cudaIpcGetMemHandle(&h, ptr));
// exchange memhandles somehow
// since we have PyTorch, we can just call all-gather
cudaIpcMemHandle_t all_handles[WORLD_SIZE];
// "open" memory handles i.e. map remote memory addresses
// in the current CUDA context's address space.
char *all_ptrs[WORLD_SIZE];
for (int i = 0; i < WORLD_SIZE; i++) {
if (i == rank)
all_ptrs[i] = ptr;
else
CUDA_CHECK(cudaIpcOpenMemHandle(reinterpret_cast<void **>(all_ptrs + i),
all_handles[i],
cudaIpcMemLazyEnablePeerAccess));
}
// then you can pass pointers of remote memory to kernels
// and deference them as usual
}PyTorch 没有直接暴露这些功能,所以我必须为上述 CUDA/HIP 函数编写小型包装器(尽管 PyTorch 在内部确实使用它们,例如在 torch.multiprocessing 中跨进程发送 CUDA 张量)。你可以跳过一些额外的环节,比如 cudaDeviceCanAccessPeer() 和 cudaDeviceEnablePeerAccess(),但如果你的设置已经支持 P2P(如果不支持,你无论如何都会收到错误),这些就不是必需的。
P2P 可以由不同的传输层支持,例如 PCIe、NVLink(NVIDIA)和 xGMI(AMD)。在 NVIDIA GPU 上,你可以使用 nvidia-smi topo -p2p rw 和 nvidia-smi topo -m 来检查 P2P 支持和底层互连。
nvidia-smi topo -p2p rw
GPU0 GPU1 GPU2 GPU3
GPU0 X CNS CNS OK
GPU1 CNS X OK CNS
GPU2 CNS OK X CNS
GPU3 OK CNS CNS X
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3
GPU0 X PHB PHB NV4
GPU1 PHB X NV4 PHB
GPU2 PHB NV4 X PHB
GPU3 NV4 PHB PHB Xnvidia-smi topo -p2p rw
GPU0 GPU1 GPU2 GPU3
GPU0 X CNS CNS OK
GPU1 CNS X OK CNS
GPU2 CNS OK X CNS
GPU3 OK CNS CNS X
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3
GPU0 X PHB PHB NV4
GPU1 PHB X NV4 PHB
GPU2 PHB NV4 X PHB
GPU3 NV4 PHB PHB X对于 AMD GPU,遵循 Iris,我使用了细粒度内存用于远程访问的缓冲区。我不太确定它在做什么,以及是否必要,但遵循 Iris 可能不是个坏主意。
对称内存与对称堆¶
根据我的理解,对称内存可以看作是在每个 GPU 上分配的相同大小的内存,并且对所有其他 GPU 都是对等可访问的。OpenSHMEM 中关于对称数据对象的部分给出了更正式的定义。换句话说,任何在所有 GPU 进程之间共享其 IPC 内存句柄的内存分配都可以被视为对称的。
如果我们只分配一次,并根据需要从中切片数据,它就变成了一个对称堆!
class P2PState:
def __init__(self, rank: int, world_size: int, size: int = 1 << 30) -> None:
# allocate a large chunk of memory. same size across ranks
self.heap = torch.empty(size, dtype=torch.uint8, device="cuda")
self.ptr = 0
self.size = size
# exchange IPC mem handles -> this becomes a symmetric heap
...
def malloc_symmetric(self, shape: tuple[int, ...], dtype: torch.dtype, alignment: int = 128) -> Tensor:
start = triton.cdiv(self.ptr, alignment) * alignment
end = start + math.prod(shape) * dtype.itemsize
assert end <= self.size
out = self.heap[start:end].view(dtype).view(shape)
self.ptr = end
return outclass P2PState:
def __init__(self, rank: int, world_size: int, size: int = 1 << 30) -> None:
# allocate a large chunk of memory. same size across ranks
self.heap = torch.empty(size, dtype=torch.uint8, device="cuda")
self.ptr = 0
self.size = size
# exchange IPC mem handles -> this becomes a symmetric heap
...
def malloc_symmetric(self, shape: tuple[int, ...], dtype: torch.dtype, alignment: int = 128) -> Tensor:
start = triton.cdiv(self.ptr, alignment) * alignment
end = start + math.prod(shape) * dtype.itemsize
assert end <= self.size
out = self.heap[start:end].view(dtype).view(shape)
self.ptr = end
return out唯一需要注意的警告是,每个分配在所有秩上必须是相同的。你不能在秩 1 的对称堆上分配 (4, 128) 的 FP32,但在秩 2 上同时分配 (7, 128) 的 BF16。这个限制自然源于我们如何索引远程分配,我将在下面解释。
当我们从对称堆中切片对称内存时,我们没有远程分配的确切内存地址。我们只有所有其他 GPU 的堆基址,当我们交换 IPC 内存句柄时。使用 translate 技巧(我借用了 Iris 中的术语),我们就可以找到任何其他秩中对称对象的确切地址。
template <typename T>
__device__ __host__
T *translate(T *ptr, int64_t src_base, int64_t dst_base) {
static_assert(sizeof(ptr) == sizeof(int64_t));
const int64_t offset = reinterpret_cast<int64_t>(ptr) - src_base;
return reinterpret_cast<T *>(dst_base + offset);
}template <typename T>
__device__ __host__
T *translate(T *ptr, int64_t src_base, int64_t dst_base) {
static_assert(sizeof(ptr) == sizeof(int64_t));
const int64_t offset = reinterpret_cast<int64_t>(ptr) - src_base;
return reinterpret_cast<T *>(dst_base + offset);
}这只有在对象相对于堆基址的偏移在所有 GPU 上都相同时才有效。我们通过确保所有对称分配在所有秩上具有相同的大小来维持这种不变性。
使用对称堆的主要优点是它更方便:你只需要携带一组堆基址来处理所有对称分配,而不是每个分配都携带一组地址。
获取-释放语义¶
当我研究 pplx-kernels 和 triton-distributed 时,我遇到了这些陌生的词汇:acquire 和 release。我不知道它们是什么意思!幸运的是,我找到了 Dave Kilian 的这篇精彩博客文章,详细清晰地解释了这些概念。
在典型的通信内核中,你有一个生产者和一个消费者。生产者写入一些数据,消费者读取这些数据。棘手的部分是同步:消费者如何知道数据何时到达,以及何时可以安全读取?我们可以使用一个信号标志来实现这一点。
- 标志初始化为
0,表示数据尚未到达。 - 一旦生产者完成写入要发送的数据,它可以将此标志设置为
1。 - 从消费者方面,它执行一个自旋锁:持续检查标志是否为
1。如果是,那么消费者可以安全地继续读取传输的数据。
然而,在没有额外约束的情况下,两个内存指令之间没有内存排序的保证。当我们顺序写入 A 和 B 时,B 可能在 A 之前到达。类似地,当我们顺序读取 C 和 D 时,D 可能在 C 之前被获取。这不是 C/C++的限制,而是指令集架构(ISA)与程序员之间从汇编级别开始的内置契约。
这对我们来说非常成问题。这意味着当消费者看到 flag = 1 时,并不表示数据已经到达。消费者也可能在看到 flag = 1 之前预取数据。这就是为什么我们需要内存语义。在我们特定的情况下,我们需要的是获取-释放语义,这在 Dave Kilian 的上述博客文章中有精彩的解释。
总结一下,你需要知道的是:
- 作为生产者,一旦你完成数据写入,你使用释放语义设置一个标志。这确保在标志设置之前,所有先前的内存写入都已经完成。
- 作为消费者,你在读取数据之前使用获取语义检查标志。这确保在观察到标志被设置之前,不会执行标志读取之后的任何数据读取。
def producer(data, flag):
# write some data
data[0] = 1
data[1] = 2
# signal data has arrived, using release semantics
store_release(flag, 1)
def consumer(data, flag):
# spinlock using acquire semantic
while load_acquire(flag) == 0:
pass
# reset flag. not compulsory, but common
flag[0] = 0
# read the data
process(data[0])
process(data[1])def producer(data, flag):
# write some data
data[0] = 1
data[1] = 2
# signal data has arrived, using release semantics
store_release(flag, 1)
def consumer(data, flag):
# spinlock using acquire semantic
while load_acquire(flag) == 0:
pass
# reset flag. not compulsory, but common
flag[0] = 0
# read the data
process(data[0])
process(data[1])确切的措辞通常包含“可见”和“观察”等术语,因为仅仅数据到达还不够,它还必须对消费者可见。一个可能的原因是内存缓存——所有全局内存事务都会经过某些级别的缓存。因此,在读取数据之前,有必要使相关缓存级别无效。
在 NVIDIA GPU 上,你可以直接在它们的PTX 指令中指定内存语义。
asm volatile("st.release.sys.global.u32 [%1], %0;" ::"r"(flag), "l"(flag_addr));
asm volatile("ld.acquire.sys.global.u32 %0, [%1];" : "=r"(flag) : "l"(flag_addr));asm volatile("st.release.sys.global.u32 [%1], %0;" ::"r"(flag), "l"(flag_addr));
asm volatile("ld.acquire.sys.global.u32 %0, [%1];" : "=r"(flag) : "l"(flag_addr));在 AMD GPU 上,我找不到任何关于如何做到这一点的明确文档。Triton 的原子操作有一个选项可以指定内存语义,这将被正确编译用于 AMD GPU,如 Iris 所示。但它们缺少简单的加载和存储,我原本希望在 HIP C++中找到一些可用的东西。幸运的是,我遇到了“未文档化”的 __hip_atomic_load()/__hip_atomic_store() 内在函数,用于rocSHMEM。
__hip_atomic_store(flag_addr, flag, __ATOMIC_RELEASE, __HIP_MEMORY_SCOPE_SYSTEM);
__hip_atomic_load(flag_addr, __ATOMIC_ACQUIRE, __HIP_MEMORY_SCOPE_SYSTEM);__hip_atomic_store(flag_addr, flag, __ATOMIC_RELEASE, __HIP_MEMORY_SCOPE_SYSTEM);
__hip_atomic_load(flag_addr, __ATOMIC_ACQUIRE, __HIP_MEMORY_SCOPE_SYSTEM);从技术上讲,内存排序和内存语义不仅限于多 GPU 问题,也存在于单 GPU 情况中。然而,许多现有的内在函数如 __syncthreads() 已经强制执行内存排序。我们也可以使用内核边界作为单 GPU 情况的全局同步和内存排序。因此,内存语义也有作用域来确定哪些线程应该观察到特定的内存访问(根据给定的语义)。
- 线程块/CTA 作用域:同一线程块/CTA 中的线程(在 AMD GPU 上也称为工作组)。
- 设备/GPU 作用域:同一 GPU 上的线程(在 AMD GPU 上也称为代理)。
- 系统作用域:多 GPU 系统中所有 GPU 上的线程,以及 CPU 上的线程。
您可以参考 NVIDIA PTX 文档和 LLVM AMDGPU 文档获取更多信息。
其他次要细节¶
我花了很长时间阅读和理解所有这些新概念。但现在我们准备好编写我们的第一个多 GPU 内核:
- 使用 P2P 进行远程内存访问。
- 使用对称堆进行对称内存分配。
- 使用获取-释放语义进行正确的内存排序。
还有一个与竞赛相关的额外问题。由于 GPU 进程在测试用例之间被重用,并且 GPU 被随机重新分配,不可能一次性分配一个对称堆并在测试运行中重复使用。为了克服这一点,我修补了 dist.init_process_group() 和 dist.destroy_process_group()。
import torch.distributed as dist
original_init = dist.init_process_group
def patched_init(*args, rank, world_size, **kwargs):
original_init(*args, rank=rank, world_size=world_size, **kwargs)
# allocate symmetric memory and exchange memory handles
# store them in a global object for later access
...
dist.init_process_group = patched_initimport torch.distributed as dist
original_init = dist.init_process_group
def patched_init(*args, rank, world_size, **kwargs):
original_init(*args, rank=rank, world_size=world_size, **kwargs)
# allocate symmetric memory and exchange memory handles
# store them in a global object for later access
...
dist.init_process_group = patched_init另一件需要注意的事情是 MI300X 具有全连接的 xGMI 链路用于节点内通信。这意味着每对 GPU 之间都有直接的 P2P 连接,因此我们不需要太关心针对特定拓扑的复杂算法。
重新实现¶
有几个开源 MoE 全对全内核,例如 DeepEP 和 pplx-kernels。我主要研究了 Perplexity 的那个,可能是因为他们还发布了一篇伴随的博客文章更详细地解释了他们的代码。本节包含了许多来自 pplx-kernels 的设计,但并非所有细节都相同,因为我不太理解他们的一些代码,因此以自己的方式重新实现了它们。
对于 dispatch() 和 combine() 内核,我们将每个内核分成两部分:send 和 recv。
Dispatch¶
让我们看看 send 和 recv 对 dispatch。在每个 GPU 上,我们为每个接收数据的 GPU 分配一个通信缓冲区。因此,在 send 阶段,每个 GPU 在接收 GPU 中对其缓冲区拥有独占所有权,因此不需要跨 GPU 的预先规划或同步(每个 GPU 发送者仍然需要在自身内部进行同步)。recv 部分负责聚合来自所有 GPU 发送者的数据。通信缓冲区由对称内存支持,以便我们可以进行远程内存访问。

Dispatch 的 Send 和 Recv 内核,灵感来自 pplx-kernels。
查看上图,它与我们之前的纯 PyTorch 实现没有太大不同。第一次排序和 dist.all_to_all_single() 被融合成为 send,第二次排序成为 recv。我们的缓冲区中有额外的填充,因为我们需要适应最坏情况(所有令牌分配给同一专家),并确保所有缓冲区在 GPU 之间具有相同的大小(对称内存约束)。
让我们讨论 dispatch-send 的更具体实现细节:
- 线程块工作分区:每个线程块将处理输入令牌的一个子集。具体来说,每个 warp 将处理一个扁平令牌。
- 我指的是扁平令牌作为在
topk_indices中找到的令牌。换句话说,它是输入令牌重复了topk次。 - 当一个 warp 处理一个扁平令牌时,它需要知道远程缓冲区中的目标位置。我们为此使用全局内存中的计数器缓冲区 - 计数器表示我们到目前为止为特定目标 GPU 及其本地专家处理了多少令牌 -> 计数本身就是目标位置。
- 我们使用
atomicAdd()递增计数器,因为不同的线程块和 warp 正在并发工作。这是由每个 warp 的lane0完成的。 - 我们可以使用 warp shuffle 有效地将目标位置广播到整个 warp,从而不产生任何共享内存访问。
您可以在 dispatch-send 找到 submission_v4.py#L152-L184 的完整代码。
send 和 recv 内核通过先前讨论的具有获取-释放语义的信号标志进行同步。每个标志保护从发送者等级到接收者等级传输的所有数据。在 send(生产者)内核中,一旦我们完成写入所有数据,我们在所有远程 GPU 中设置信号标志,告诉那些 GPU 当前 GPU 已完成。还有一些额外细节:
- 为了等待所有线程块完成(在设置标志之前),我使用了协作内核,它允许使用
cooperative_groups::this_grid().sync()进行网格范围的同步。注意,启动一个单独的内核(以避免使用协作内核)也有效。 - 我们还需要发送令牌计数到目标 GPU,以便
recv内核知道要处理多少令牌。由于我们上面的atomicAdd()策略,我们已经有了这个计数。使用来自pplx-kernels的技巧,我们将令牌计数编码在信号标志flag = count + 1中。
在 dispatch-recv 中,跨线程块进行提前工作分区有点尴尬,因为我们只有在 dispatch-send 之后才知道接收到的令牌数量。此外,由于每个锁保护来自特定 GPU 的所有数据,如果有多个线程块处理同一源等级,我们必须跨线程块进行同步。我采用了一个相当简单的方案:每个线程块处理一个源等级,以避免网格范围的同步。这很糟糕,因为只有 WORLD_SIZE=8 个活动线程块。dispatch-recv 的其他细节不太有趣。您可以在 submission_v4.py#L209-L261 找到它们。
Combine¶
combine() 比 dispatch() 容易得多。由于我们知道每个令牌的确切原始位置(作为元数据附加在 dispatch()),每个 GPU 可以直接将输出令牌发送到其来源。通信缓冲区分配得足够大,以容纳归约前的“扁平”令牌。combine-recv 负责归约步骤,缩放来自 topk_weights。

Combine 的 Send 和 Recv 内核,灵感来自 pplx-kernels。
combine-send 遍历分组 GEMM 输出缓冲区中的所有令牌,根据已知的令牌计数跳过填充令牌。与 dispatch() 不同,combine() 使用每个令牌一个锁(信号标志)。这种设计也使 recv 部分变得容易得多:由于我们使用 1 个 warp 处理 1 个令牌,我们只需要进行warp 同步,这基本上是免费的。
- 当我首次实现这个版本时,我查看了 CUDA 的
__syncwarp(),这在 HIP 中不可用,可能是因为 AMD GPU 不支持mask中的__syncwarp()。我想出了一个使用__syncthreads()的解决方法(基本上确保线程块中的所有线程都能到达__syncthreads()),但一旦我发现__builtin_amdgcn_wave_barrier(),它就不再必要了。
对于 combine-recv,我考虑了几种执行归约的方法,例如在共享内存或全局内存中。最终,我选择了最简单的方法:在寄存器中进行归约,每个 warp 遍历通信缓冲区中的 topk 个“扁平”令牌。
- 在共享内存或全局内存中进行归约的潜在好处是,我们可以使用
topk个 warp 同时自旋锁定topk个令牌,然后立即处理到达的令牌。然而,这似乎没有必要。
你可以在 combine() 找到我的submission_v4.py#L383-L492。结合新的 dispatch() 和 combine()HIP 内核,我的新排行榜结果是116ms。是的,它比未优化的参考内核(包含大量 Python for 循环)更慢。
细粒度每令牌锁¶
PyTorch Profiler 显示瓶颈是 dispatch-recv 中的自旋锁定循环。我无法理解为什么会这样。无论如何,查看我队友的代码后,我决定用每令牌锁重写 dispatch 内核。概念上,我们可以决定锁保护数据的粒度。
- 粗粒度锁意味着自旋锁定循环更少(给定相同的数据量),释放硬件资源去做其他事情。
- 另一方面,使用细粒度锁,我们可以更好地流水线化逻辑,在数据到达时立即处理。同步也更容易,因为我们不需要与一大组线程同步。
在我们之前的 dispatch() 实现中,我们使用了每个 src->dst rank 一个锁。这也给 dispatch-recv 带来了一些同步上的麻烦。切换到每令牌锁将缓解其中一些复杂性。然而,我们仍然需要传输令牌计数,以便 dispatch-recv 知道要等待多少令牌。回想一下,我们在发送令牌后发送令牌计数,因为我们已经在使用令牌计数缓冲区来查找令牌在其目标缓冲区中的位置。我们不能在这里做同样的事情,因为这会违背使用每令牌标志的目的。
相反,我们使用 1 个线程块进行计数(在共享内存中),并并发地发送令牌计数,而其他线程块发送令牌。在 dispatch-recv 端,我们只需要等待令牌计数的到达,进行网格范围的同步,然后就可以开始进行每令牌自旋锁定。为了避免显式的网格范围同步,我在 dispatch-send 的末尾进行令牌计数的自旋锁定。
- 我尝试将令牌计数的自旋锁定放在
dispatch-recv中(这需要一个协作内核),但自旋锁定循环异常缓慢。我仍然不太理解原因。 - 由于我们使用内核边界作为隐式的网格范围同步,我们的
dispatch-send和dispatch-recv必须是两个独立的、顺序的内核。这限制了我们尝试像重叠send和recv这样的想法,这可能很有用,因为我们可以在发送数据的同时开始从其他 rank 接收令牌。
这总结了 submission_v5.py 中的新变化。由于每令牌锁,我在 dispatch-recv 中如何划分工作有一些更新,但我觉得这在代码中相当直接。这个实现达到了 517μs,比我们最好的 PyTorch-only 实现快了 2.5 倍。
融合 fake grouped GEMM 与 combine¶
我们现在终于有了一个基于 P2P 的工作 HIP 内核。自然的下一步是投资一个性能分析设置。PyTorch Profiler 是我的首选,但它有一个严重的缺陷:dispatch-send 异常缓慢。奇怪的是,这只发生在使用性能分析器时,而正常的运行时测量是正常的。
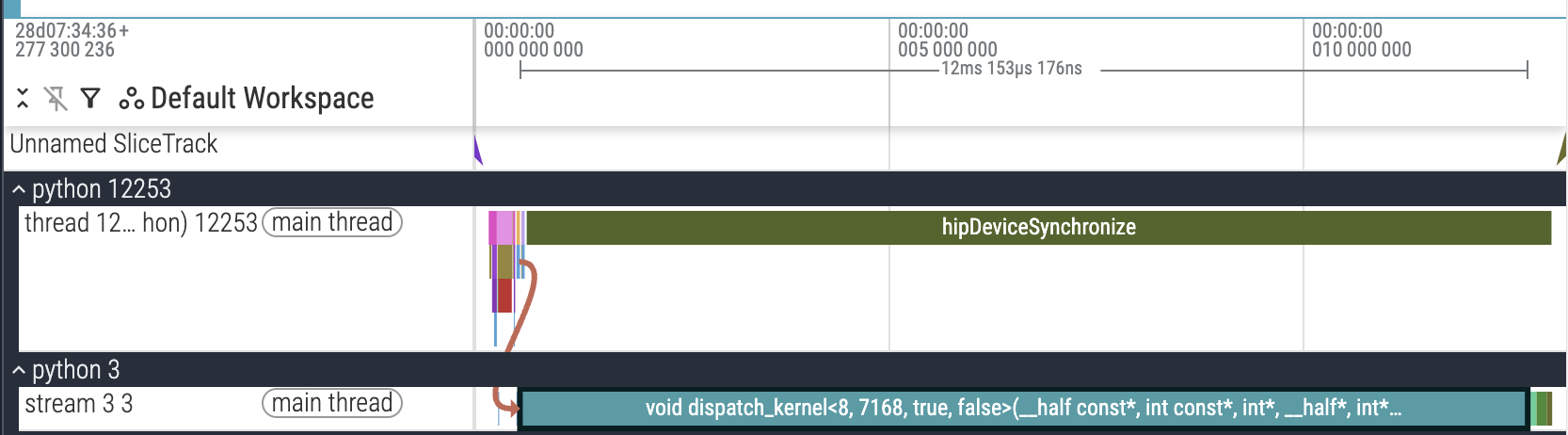
PyTorch Profiling trace,显示 dispatch-send 异常缓慢。
我将问题缩小到令牌计数的自旋锁定循环。我最好的猜测是 AMD 性能分析器后端与多 GPU 代码有奇怪的交互。无论如何,由于这个问题,我切换到手动 CUDA 事件计时(submission_v6.py#L893-L913),并获得了以下最大问题形状(num_experts=256,experts_per_token=8,hidden_dim=7168,max_num_tokens=256,world_size=8)的结果。
| 秩(Rank) | Dispatch | Grouped GEMM | Combine | 总计(Total) |
|---|---|---|---|---|
| 0 | 348.60 | 115.66 | 342.94 | 807.20 |
| 1 | 334.80 | 115.98 | 342.18 | 792.97 |
| 2 | 377.98 | 115.78 | 333.76 | 827.53 |
| 3 | 330.19 | 115.30 | 317.28 | 762.78 |
| 4 | 333.96 | 115.22 | 349.44 | 798.62 |
| 5 | 314.84 | 115.46 | 326.59 | 756.89 |
| 6 | 327.07 | 115.02 | 325.34 | 767.43 |
| 7 | 329.03 | 115.42 | 336.49 | 780.94 |
到目前为止,我只专注于 dispatch 和 combine,将“fake” grouped GEMM 单独留下。性能分析数据显示 grouped GEMM 对整体运行时间贡献相当大。将其与 combine 融合将减少约 100μs 的延迟,而且也很简单:“fake” grouped GEMM 只是一个逐点乘法。在与组织者确认这是一个有效的优化后,我实现了它,并将运行时间减少到421μs。
- 对于实际的 MoE 内核,我们仍然可以进行融合:
combine可以与 grouped GEMM 的 epilogue 融合。然而,也有新的复杂性:缓慢的 epilogue 会使 SM/CU 的计算单元空闲,除非使用像 warp specialization 这样的额外技巧;基于 GEMM tile 的输出与每令牌锁设计不直接兼容。
内核调优¶
通常,我不希望内核调优拥有自己的章节,因为从技术上讲,所有内核在发生变化时都应该重新调优,无论变化多么小。然而,有时调优会揭示设备的某些值得讨论的属性。
对于我的内核,我可以调优 grid_size(线程块数量)和 NUM_WARPS(线程块中的 warp 数量)。到目前为止我编写的所有代码都与这些超参数无关,因此调优它们很容易。为 combine 设置 grid_size=304(恰好是 MI300X 中的 CU 数量)导致端到端延迟为 345μs!这相当令人惊讶,因为线程块的数量必须恰好是 304。任何其他合理的大数字,如 256,都无法实现相同的加速。
使用 grid_size=256 进行 combine。
| 秩(Rank) | dispatch-send | dispatch-recv | combine-send | combine-recv | 总计(Total) |
|---|---|---|---|---|---|
| 0 | 225.99 | 78.78 | 300.92 | 46.26 | 651.96 |
| 1 | 225.35 | 77.50 | 310.66 | 53.48 | 666.99 |
| 2 | 289.38 | 38.29 | 311.23 | 47.15 | 686.03 |
| 3 | 289.58 | 32.51 | 299.80 | 49.71 | 671.60 |
| 4 | 231.08 | 77.17 | 307.38 | 62.30 | 677.94 |
| 5 | 211.76 | 90.44 | 302.80 | 65.03 | 670.04 |
| 6 | 279.92 | 32.95 | 292.10 | 48.07 | 653.04 |
| 7 | 205.35 | 87.68 | 305.97 | 47.99 | 646.99 |
使用 grid_size=304 进行 combine。
| 秩(Rank) | dispatch-send | dispatch-recv | combine-send | combine-recv | 总计(Total) |
|---|---|---|---|---|---|
| 0 | 219.33 | 95.70 | 108.88 | 60.02 | 483.93 |
| 1 | 216.93 | 106.40 | 115.42 | 50.75 | 489.50 |
| 2 | 283.88 | 64.19 | 117.95 | 46.54 | 512.56 |
| 3 | 291.94 | 32.27 | 97.66 | 56.09 | 477.96 |
| 4 | 236.97 | 60.94 | 126.17 | 43.06 | 467.13 |
| 5 | 211.08 | 106.96 | 113.14 | 54.24 | 485.41 |
| 6 | 304.65 | 32.83 | 113.46 | 46.02 | 496.96 |
| 7 | 214.08 | 106.68 | 113.17 | 52.04 | 485.97 |
grid_size=304 为 combine-send 提供了近 3 倍的加速!像 MI300X 上的许多其他观察一样,我没有解释。调优 dispatch 没有产生任何明显的加速。
消除开销¶
我在上一节中提到,PyTorch Profiler 没有显示非常有意义的跟踪,但偶尔在某些秩上是正常的。检查其中一个这样的跟踪揭示了来自动态分配(malloc)和清零缓冲区(memset)的不可接受的开销。

Malloc 和清零开销。
奇怪的是,存在 hipMalloc 调用,因为 PyTorch 的缓存分配器应该已经处理了它们。无论如何,消除 malloc 调用很简单——将 torch.empty() 移到主内核之外,并重用缓冲区。
清零缓冲区更成问题。在我的内核中,我依赖于缓冲区初始化为零的事实以实现正确的逻辑,例如使用 atomicAdd() 的 token 计数。一种解决方案是在 C++ 中切换到 cudaMemsetAsync() 以消除 Python 开销以及不必要的内核启动,但我认为我们可以做得更好。
主要思想是我们可以在后续内核中偷偷插入 memset 以恢复不变性。从逻辑上讲,我们正在执行以下操作。
# allocation, initialized to zeros
send_counts = torch.zeros(WORLD_SIZE)
# call the kernel multiple times
for _ in range(10):
dispatch_send(..., send_counts)
send_counts.zero_() # restore invariance
dispatch_recv(...)
...# allocation, initialized to zeros
send_counts = torch.zeros(WORLD_SIZE)
# call the kernel multiple times
for _ in range(10):
dispatch_send(..., send_counts)
send_counts.zero_() # restore invariance
dispatch_recv(...)
...为了避免为 send_counts.zero_() 使用单独的内核(或 cudaMemsetAsync()),我们可以将其与下一个内核 dispatch-recv 融合。由于这个缓冲区很小,使用第 1 个线程块中的一些线程就足够了。
// STAGE: dispatch-recv
// reset send_counts buffer used in dispatch-send
// since zero_() is very expensive
if (bid == 0 && tid < WORLD_SIZE)
send_counts[tid] = 0;// STAGE: dispatch-recv
// reset send_counts buffer used in dispatch-send
// since zero_() is very expensive
if (bid == 0 && tid < WORLD_SIZE)
send_counts[tid] = 0;由于我已经在进行开销减少,我还将大部分代码移至 C++,包括对称堆的切片。因此,submission_v7b.py 专注于消除开销,实现了 303μs。
优化变长工作分配¶
内核内性能分析¶
我从队友那里学到的最酷的技巧之一是内核内性能分析。CUDA 事件(以及 PyTorch Profiler)只能在内核级别进行性能分析 —— 衡量特定内核或一组内核需要多长时间。要理解代码级别的瓶颈,我们需要在内核内部进行性能分析。
对于 NVIDIA GPU,通常我会使用 Nsight Compute 的 Source 视图来检查哪行代码占用最多的 warp 停顿。我找不到 AMD 的等效工具,因此内核内性能分析技巧特别有用。
目标是生成一个 Chrome 跟踪,我可以用 https://ui.perfetto.dev/ 可视化。格式 非常简单——我们只需要特定事件的开始和结束时间戳,以及一些额外的元数据。要在 AMD GPU 的内核中获取时间戳,我借用了 Iris 的代码。
__device__
int64_t read_realtime() {
int64_t t;
asm volatile("s_waitcnt vmcnt(0)\n"
"s_memrealtime %0\n"
"s_waitcnt lgkmcnt(0)" : "=s"(t));
return t;
}__device__
int64_t read_realtime() {
int64_t t;
asm volatile("s_waitcnt vmcnt(0)\n"
"s_memrealtime %0\n"
"s_waitcnt lgkmcnt(0)" : "=s"(t));
return t;
}一旦我们有了时间戳,我们就可以将它们写入全局内存。棘手的是标注不同类型的事件,这些事件可能同时来自多个线程或线程块。我想出了一个简单的方案。
__device__
int profile_start(int64_t *profile) {
int i = atomicAdd(reinterpret_cast<int*>(profile), 1);
profile[1 + i * 4] = read_realtime();
return i;
}
__device__
void profile_stop(int64_t *profile, int i, int tag, int tid) {
profile[1 + i * 4 + 1] = read_realtime() - profile[1 + i * 4];
profile[1 + i * 4 + 2] = tag;
profile[1 + i * 4 + 3] = tid;
}
// usage
{
// obtain event ID
int e0_id;
if constexpr (DO_PROFILE) if (tid == 0) e0_id = profile_start(p2p_state.profile);
// code being recorded
...
// use the previous event ID to write down ending timestamp
if constexpr (DO_PROFILE) if (tid == 0) profile_stop(p2p_state.profile, e0_id, 0, bid);
}__device__
int profile_start(int64_t *profile) {
int i = atomicAdd(reinterpret_cast<int*>(profile), 1);
profile[1 + i * 4] = read_realtime();
return i;
}
__device__
void profile_stop(int64_t *profile, int i, int tag, int tid) {
profile[1 + i * 4 + 1] = read_realtime() - profile[1 + i * 4];
profile[1 + i * 4 + 2] = tag;
profile[1 + i * 4 + 3] = tid;
}
// usage
{
// obtain event ID
int e0_id;
if constexpr (DO_PROFILE) if (tid == 0) e0_id = profile_start(p2p_state.profile);
// code being recorded
...
// use the previous event ID to write down ending timestamp
if constexpr (DO_PROFILE) if (tid == 0) profile_stop(p2p_state.profile, e0_id, 0, bid);
}int64_t *profile 只是全局内存中的一个缓冲区。它的第一个元素 profile[0] 是到目前为止记录的事件数量,因此 atomicAdd() 返回要记录的新事件的索引。在第一个元素之后,每个事件占用 4 个元素:
- 起始时间戳
- 结束时间戳
- 数值标签
- ID
这种设计允许多个线程独立记录其事件,而无需提前规划布局。数值标签可以稍后使用名称列表查找。要添加新的事件名称,我们可以向此查找列表添加更多元素。
不均匀工作分配¶
通过内核内性能分析的能力,我们现在可以获得更细粒度的内核跟踪。我记录了每个 token 的发送和接收事件,对于 dispatch 和 combine 都是如此。我还将所有 GPU 的跟踪合并到一个文件中以便于可视化。
- Chrome 的
pid(进程 ID)映射到 GPU 秩,Chrome 的tid(线程 ID)映射到 GPU 线程块 ID。对于每个线程块,我只记录了第一个 warp。 - Chrome 跟踪格式和/或 UI Perfetto 存在一些怪癖。对于
pid=N,tid必须以N开头。为了正确显示数据,我必须将秩 N 的线程块 ID 增加N。因此,在下面的屏幕截图中,对于进程 4,您应该将线程 ID 减去 4 以获得原始线程块 ID。
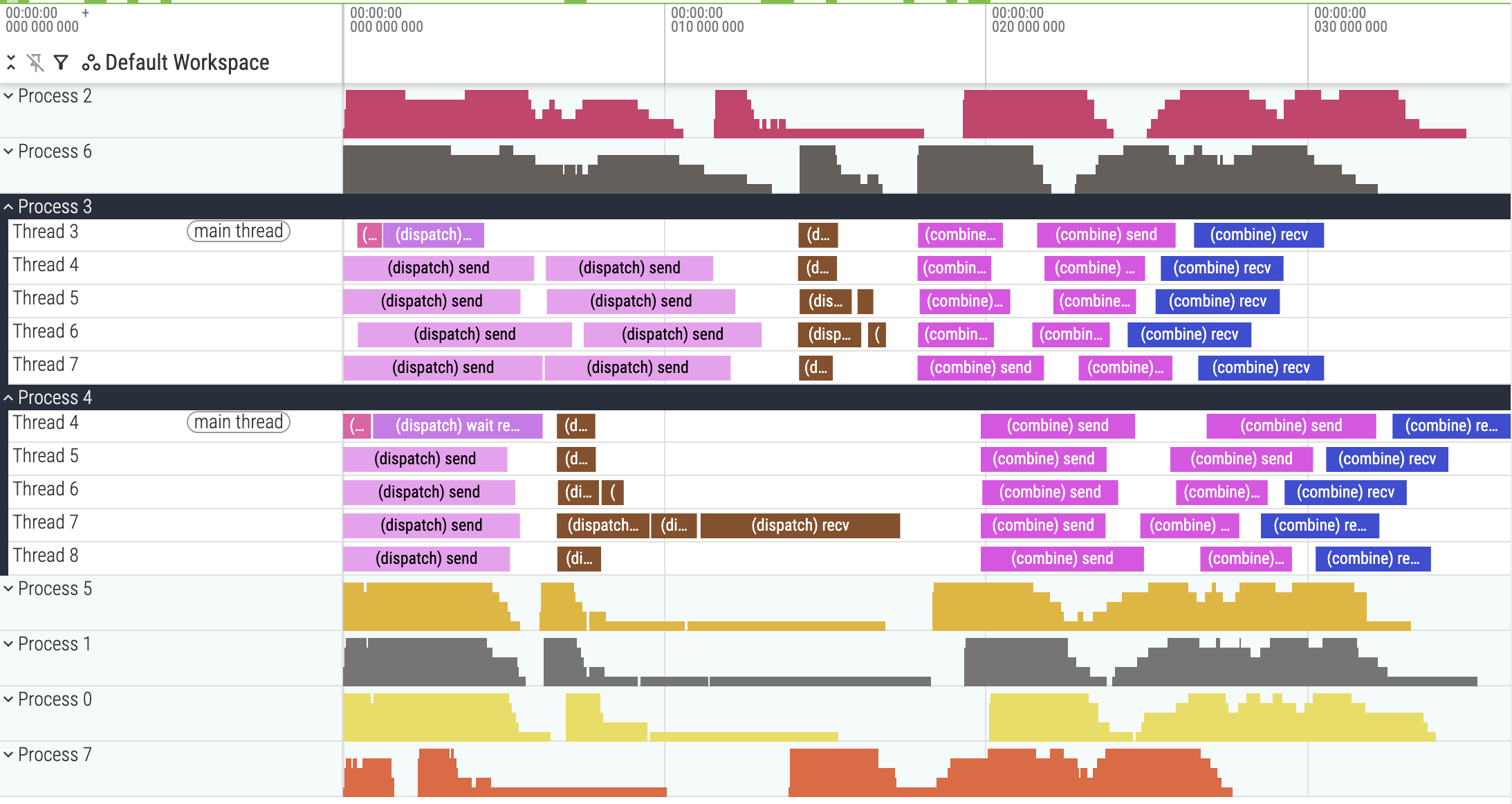
trace_v8.json.gz。v8 的内核内性能分析,显示 dispatch-recv 中线程块之间不均匀的工作分配。Process 4 Thread 4 表示 GPU4 的线程块 0。
在 dispatch-recv 内核中存在明显的不均匀工作分配。进程 4 线程 7,映射到 GPU4 线程块 3,必须接收 3 个 token,而大多数其他线程块只接收了 1 个 token。这是由于我在 dispatch-recv 中分配线程块工作的方式。
// each block is assigned a src_rank based on its bid (round-robin)
// hence, each src_rank is handled by (num_blocks / WORLD_SIZE) threadblocks
const int src_rank = bid % WORLD_SIZE;
const int recv_count = comm_recv_counts[src_rank];
// each warp handles 1 token
// divide by WORLD_SIZE due to src_rank assignment above
for (int comm_pos = (bid / WORLD_SIZE) * NUM_WARPS + warp_id;
comm_pos < recv_count;
comm_pos += (num_blocks / WORLD_SIZE) * NUM_WARPS) {
// spin-lock and token copy
...
}// each block is assigned a src_rank based on its bid (round-robin)
// hence, each src_rank is handled by (num_blocks / WORLD_SIZE) threadblocks
const int src_rank = bid % WORLD_SIZE;
const int recv_count = comm_recv_counts[src_rank];
// each warp handles 1 token
// divide by WORLD_SIZE due to src_rank assignment above
for (int comm_pos = (bid / WORLD_SIZE) * NUM_WARPS + warp_id;
comm_pos < recv_count;
comm_pos += (num_blocks / WORLD_SIZE) * NUM_WARPS) {
// spin-lock and token copy
...
}如果来自特定等级的令牌更多,分配给该等级的线程块需要比其余线程块做更多的工作。在上面的性能分析跟踪中,GPU4 线程块 3(进程 4 线程 7)正在接收来自 GPU3 的令牌,而 GPU3 发送的令牌比其他等级多。最终,这是变长序列的工作分配问题。
我知道 varlen 版本 Flash Attention 的额外输入包括序列偏移量(sequence offsets)(即累积长度)和最大序列长度。这与之前介绍的变长(varlen)torch._grouped_mm() 类似。我可以在不查看源代码的情况下大致猜测线程块(threadblock)的划分逻辑,但存在一个问题:我们需要来自其他秩(rank)的**累积和(cumulative sum)**的令牌计数,这需要整个网格(grid)范围内的同步。
或者真的需要吗?只有 8 个项目,所以**所有线程(for all threads)**独立进行累积和的成本并不高。
// RECV stage
// "flatten" the recv tokens from all other ranks -> ensure work is distributed across all threadblocks equally,
// even if recv tokens from other ranks are not even.
int idx = bid * NUM_WARPS + warp_id;
int start = 0; // start of current src_rank
for (int src_rank = 0; src_rank < WORLD_SIZE; src_rank++) {
int end = start + comm_recv_counts[src_rank]; // end of current src_rank
for (; idx < end; idx += num_blocks * NUM_WARPS) {
// spin-lock and copy token
...
}
start = end;
}// RECV stage
// "flatten" the recv tokens from all other ranks -> ensure work is distributed across all threadblocks equally,
// even if recv tokens from other ranks are not even.
int idx = bid * NUM_WARPS + warp_id;
int start = 0; // start of current src_rank
for (int src_rank = 0; src_rank < WORLD_SIZE; src_rank++) {
int end = start + comm_recv_counts[src_rank]; // end of current src_rank
for (; idx < end; idx += num_blocks * NUM_WARPS) {
// spin-lock and copy token
...
}
start = end;
}从概念上讲,上述内容等价于
for (int idx = bid * NUM_WARPS + warp_id;
idx < sum(comm_recv_counts);
idx += num_blocks * NUM_WARPS) {
...
}for (int idx = bid * NUM_WARPS + warp_id;
idx < sum(comm_recv_counts);
idx += num_blocks * NUM_WARPS) {
...
}它均匀地在线程块之间分配工作。存在一些开销,因为内层循环可能为空,但我认为对于这个问题来说非常小。
我也将相同的逻辑应用于 combine-send,因为它也处理来自 num_local_experts 序列的变长序列。这变成了 submission_v9.py,这是我的最终版本。端到端运行时间没有太大改善,仅达到 292μs。
不均匀工作停滞(Uneven work stalling)¶
尽管我们改进了工作分配,dispatch-recv 并没有变得快多少。
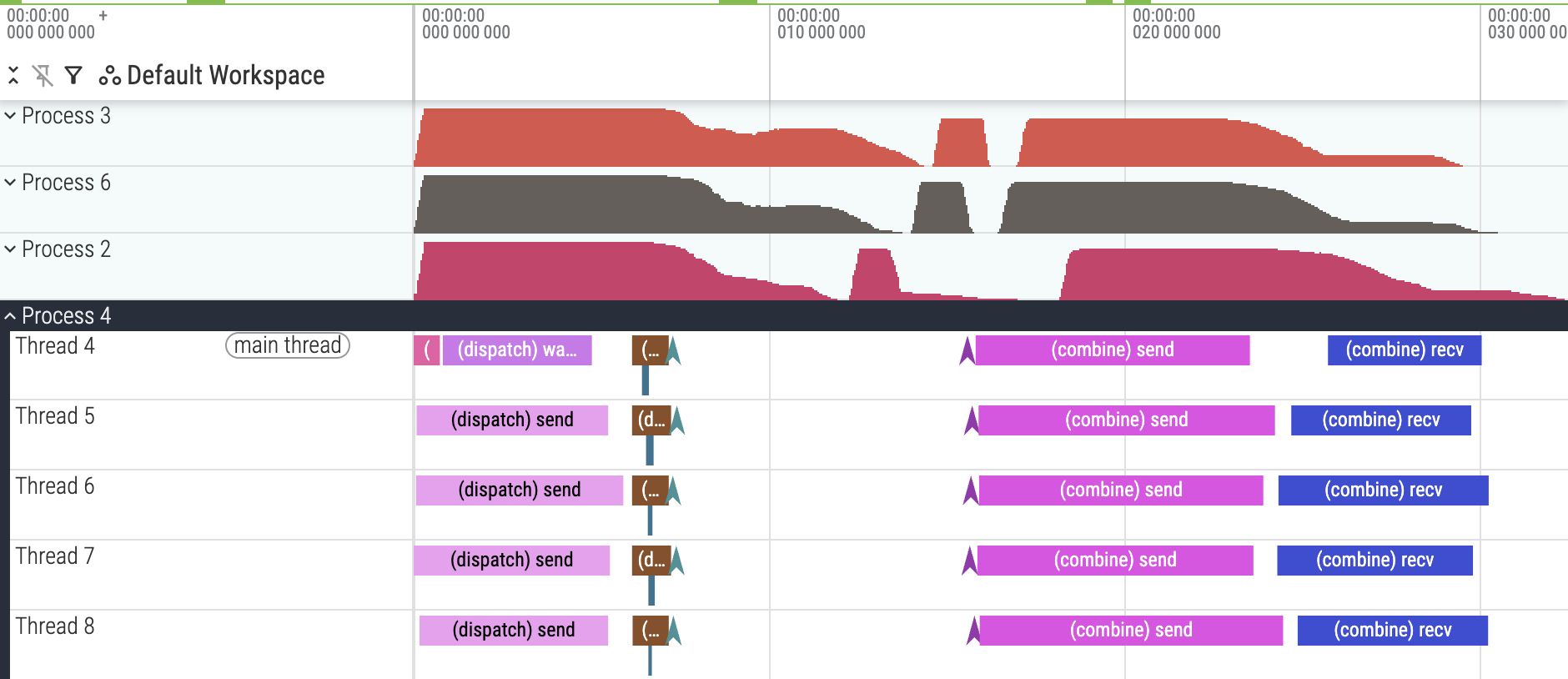
trace_v9.json.gz。v9 的内核内性能分析,显示 dispatch-recv 停滞(stall)。
起初我对 dispatch-recv 和 combine-send 之间的白色间隙感到困惑(为什么 combine-send 没有更早开始?),但检查后面的线程块揭示了答案。

trace_v9.json.gz。v9 的内核内性能分析,显示不均匀的 dispatch-recv 跨线程块的自旋锁(spin-lock)时间。
由于我们新的线程块工作分配,不清楚一个线程块正在处理哪个源秩(source rank)。上面 Chrome 跟踪中线程 180 和线程 181 之间的显著差异可能对应于源秩的增加。
- 我们可以通过向性能分析事件添加额外注释来验证这一点,但我没有实现它。
放大 Chrome 跟踪,你可以看到一些秩发送的数据比其他秩多。因此,具有异常缓慢自旋锁循环的线程块实际上是在等待来自那些秩的数据到达。
- 我强烈建议你从上面的链接下载 Chrome 跟踪,以便自己可视化和交互,因为我无法通过截图展示所有内容。
- 在这个竞赛中,每个秩的令牌数量并不相同,我认为这对于典型的 DP(数据并行)部署来说相当不寻常(由于负载平衡)。
尽管我可以识别问题,但我没有时间实现任何有用的改进。我相信像 Comet 中的流水线方法可能会有帮助:通过将数据分成 2 个(或更多)分区,我们可以在子集上运行完整的内核系列,而无需等待所有令牌完成执行。
结束语(Closing remarks)¶
以下是我跨版本的渐进改进总结。
| 版本(Version) | 代码(Code) | 排行榜运行时间(Leaderboard runtime) |
|---|---|---|
| 参考(Reference) | reference.py | 93540μs |
| 优化的纯 PyTorch(Optimized PyTorch-only) | submission_v2.py | 1311μs |
| P2P 对称内存(P2P symmetric memory) | submission_v5.py | 517μs |
| 融合分组 GEMM + 组合。调优内核(Fuse grouped GEMM + combine. Tuned kernel) | submission_v7.py | 345μs |
| 移除开销(Remove overheads) | submission_v7b.py | 303μs |
| 变长工作分配(Varlen work distribution) | submission_v9.py | 292μs |
迭代过程绝对不是单调的:想法没有成功,一些实现比之前的版本更慢。但我希望这个工作日志揭示了处理新内核时的逻辑过程。
不幸的是,我没有时间研究竞赛中的另外两个问题:gemm-rs 和 ag-gemm。我的队友在 benenzhu/gpu-mode-kernels 发布了他的解决方案。你绝对应该去看看!
最后,我要感谢以下人员,没有他们,这篇博客文章就不可能完成:
- 竞赛组织者 AMD 和 GPU MODE,给了我学习多 GPU 编程的机会。
- zhubenzhu,我意外的队友,与他交流了许多酷炫的想法和知识。每令牌标志设计和内核内性能分析技巧都来自他。
- Iris 的作者们创建了如此优雅的库。他们的 GPU MODE 讲座 是我对多 GPU 编程的第一次介绍。尽管我没有直接使用 Iris,但它对我理解对称内存和各种 AMD GPU 技巧至关重要。
- Yotta Labs 赞助了我们内核开发的计算资源。