📝 转载 / 引用来源: 作者 lmsys.org · 查看原文
摘要¶
我们很高兴地介绍 SGLang 高度优化的流水线并行(Pipeline Parallelism,PP)实现,专门设计用于应对超长上下文推理的挑战。通过整合 分块流水线并行(Chunked Pipeline Parallelism)、异步点对点通信(Asynchronous P2P Communication),以及简单而有效的 动态分块机制(Dynamic Chunking Mechanism),这种 PP 设计实现了行业领先的性能,同时确保与其他并行策略、PD 解耦(PD Disaggregation)和 HiCache 无缝兼容。在多节点部署中,使用此实现扩展到 PP4 TP8 时,当分块预填充大小设置为 12K,相比 TP8,DeepSeek-V3.1 在 H20 集群上的 预填充吞吐量达到 3.31 倍(Prefill Throughput for DeepSeek-V3.1),显著优于 TP32 方案的 2.54 倍,优势达 30.5%。这突显了 PP 在大规模跨节点扩展方面相对于纯 TP 的固有架构优势。此外,我们的实现还能实现高达 67.9% 的首令牌时间(TTFT)下降,同时保持 82.8% 的强扩展效率(strong scaling efficiency),为扩展万亿参数模型以处理超长上下文提供了一条高效、开源的路径。
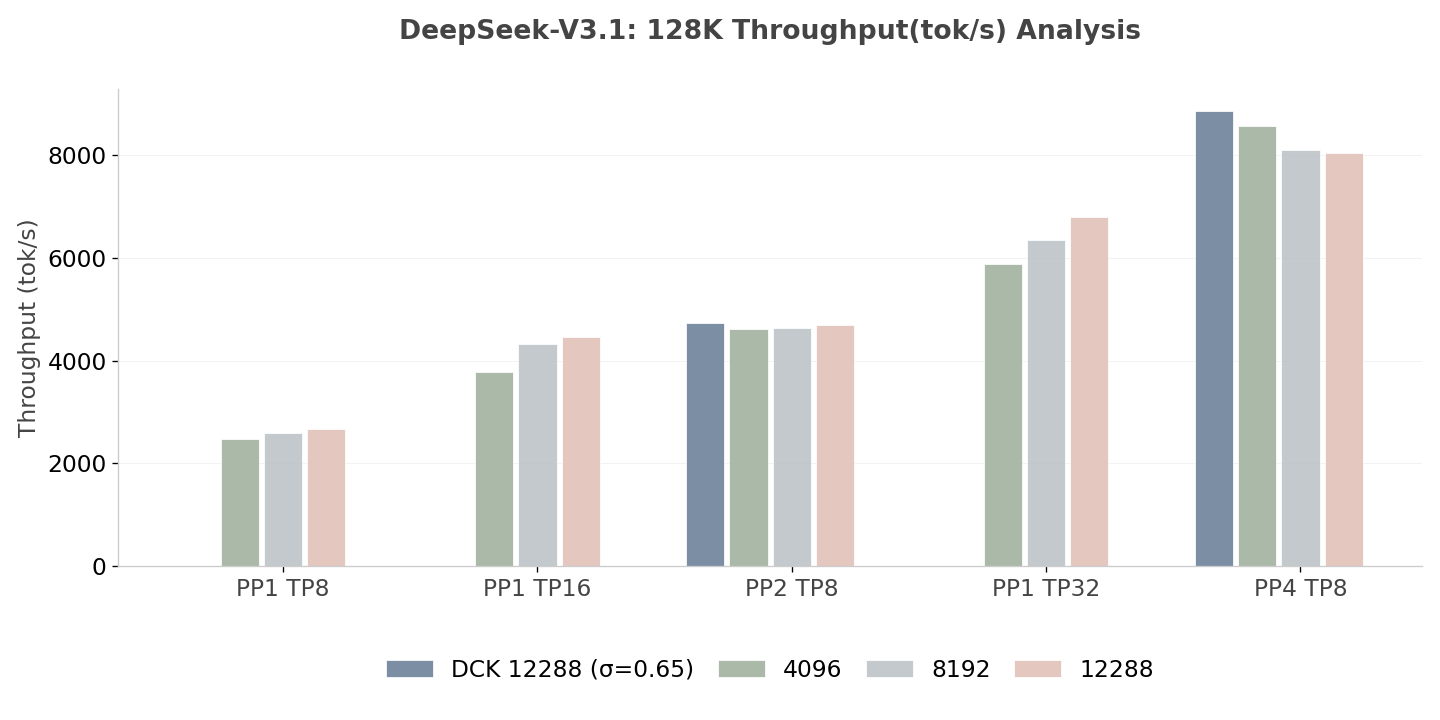
DeepSeek-V3.1 在 H20 上的预填充吞吐量(批量大小 = 1,越高越好)。 注:DCK 12288(σ = 0.65)表示启用动态分块,初始分块预填充大小设置为 12K,平滑因子设置为 0.65。
👉 查看 PP 路线图(PP Roadmap)。
引言(Introduction)¶
随着大语言模型(Large Language Models,LLMs)向万亿参数架构和“无限”上下文窗口扩展,底层服务基础设施必须向更细粒度、跨节点的并行化策略演进。虽然 KV 缓存技术有效减轻了冗余计算,但它们无法规避超长序列中因极大初始输入令牌长度(Input Token Length,ITL)而固有的高昂首令牌时间(Time to First Token,TTFT)。尽管张量并行(Tensor Parallelism,TP)仍然是节点内扩展的传统方法,但在多节点部署中经常遇到通信瓶颈。另一方面,尽管传统流水线并行(Pipeline Parallelism,PP)通过减少通信量来解决这一瓶颈,但在处理如此庞大的提示时,它仍会面临资源利用不足和气泡开销的问题。
受开源创新和学术研究的启发,SGLang 引入了一种高度优化的流水线并行实现,结合异步通信和动态分块预填充功能,有效最小化流水线气泡。通过整合这些技术,SGLang 重新定义了超长提示的处理方式——把长序列预填充的高昂延迟,转化为高吞吐量、可扩展的流式工作流。
实证基准测试表明,SGLang 的 PP 实现达到了行业领先的性能。在大规模部署中,它在扩展到 PP4 时,仍能为多种模型架构保持 80% 以上 的扩展效率(scaling efficiency);在 H20 上部署 Qwen3-235B-A22B-FP8 时,使用 PP8 还能为超长提示实现 高达 81% 的 TTFT 降低。
背景:为什么需要流水线并行?(Background: Why Pipeline Parallelism?)¶
为了验证流水线并行(Pipeline Parallelism,PP)对于长上下文预填充的必要性,必须将其与现有范式——特别是张量并行(Tensor Parallelism,TP)和上下文并行(Context Parallelism,CP)——进行评估。虽然 TP 和 CP 具有不同的优势,但对它们的通信量、气泡率和实现复杂性的理论与实证分析表明,PP 在多节点扩展中占据独特且最优的位置。以下分析概述了每种方法固有的具体权衡。
1. 通信量与可扩展性分析(Communication Volume and Scalability Analysis)¶
分布式推理扩展的主要瓶颈是设备间通信。随着模型深度和序列长度的增加,设备间传输的数据量会成为限制因素,尤其是在扩展到大规模、多节点部署时。
假设 代表批量大小(对于超长上下文推理通常为 1), 代表总序列长度, 代表隐藏状态维度, 代表总层数, 代表微批次数,激活精度为 FP8(1 字节)。基于此,我们分析了不同并行策略的通信量。
- TP: TP 将单个权重张量在单层内跨多个设备分割。因此,由于需要在注意力块(Attention Block)和 MLP 块(MLP Block)之后进行同步,TP 会产生高通信开销,通信量也会随层数线性增长。这种频繁的 全归约(All-Reduce) 同步使 TP 受带宽限制,限制了其在大型集群中的可扩展性。
(注:在基于环的实现中,每次 All-Reduce 涉及 的数据量;每层涉及 All-Reduce 操作,一次在注意力块之后,一次在 MLP 块之后。)
- CP: 类似地,CP 需要大量同步通信来跨设备聚合键值(Key-Value,KV)状态。通常,CP 在每一层使用 全收集(All-Gather),导致在带宽受限环境中产生显著的延迟惩罚。
(注:假设 CP 使用基于 Ring Attention 的方案。对于使用 GQA 的模型, 小于 ,因此 CP 的通信量更低。)
- PP: 相比之下,PP 表现出显著减少的通信足迹。数据仅在流水线阶段的 边界处 传输,使用 点对点(Point-to-Point,P2P) 原语而非集体操作。由于一个阶段通常包含多个层,通信频率由阶段数 决定,而非总层数 。关键的是,对于固定模型,当我们增加每个阶段的层数时,边界处的通信量保持恒定。
(注:在多节点部署中,当 时,与 TP 相比,PP 的总通信量可减少近一个数量级。)
2. 气泡率权衡¶
虽然 PP 优化了通信,但它引入了流水线气泡——设备等待数据依赖的空闲期。这带来了通信效率与设备利用率之间的权衡。
-
TP 和 CP: 这两种方法理论上都实现了零气泡率,因为所有设备同时计算同一张量或序列的不同部分。这最大化了计算强度,前提是通信不会阻塞计算。
-
PP: PP 不可避免地会产生气泡率,其大小由 PP 规模 与微批次数 的相互作用量化,气泡率可写为 。然而,对于工作负载较大的长上下文预填充场景,当 时,该比率会显著下降,使得效率损失与通信增益相比可忽略不计。在 性能影响 部分,我们将评估这一 PP 实现的 强扩展效率(即处理器数量增加而问题规模保持不变)。
值得注意的是,虽然 PP 在跨节点扩展方面具有明显优势——在这类场景中,通信带宽常成为主要瓶颈——但纯高程度 PP 配置通常并不推荐。这是因为对于固定工作负载 ,流水线气泡率会随 PP 大小 成比例增加。相反,更好的策略是利用无气泡并行方法,如 TP 或 CP,进行节点内扩展。由于节点内通信通常使用高带宽互连(如 NVLink),这些集体操作远不如跨节点传输那样容易成为性能瓶颈,因此系统可以最大化计算利用率而不产生额外流水线开销。
3. 实现复杂性与架构通用性¶
新功能的实现复杂性和架构通用性对于现代推理系统至关重要,尤其是对于开源项目。
- TP: TP 易于实现且广泛支持。然而,大规模 TP 配置本质上并不适用,因为量化块所需的粒度有时无法与 MoE FFN 权重施加的分区约束对齐。因此,即使不考虑通信量和开销,更大的 TP 在多节点扩展场景中也常因与量化这种关键且不可或缺的优化技术不兼容而无法使用。
- CP: CP 更复杂,需要对注意力机制进行特定且通常较为侵入式的修改(例如 Ring Attention)。这些更改必须针对每种注意力变体和特定模型定制,降低了通用性。
- PP: PP 代表中等复杂性。它需要对模型进行分区,但对层的内部机制保持不可知。这使得 PP 成为适用于所有模型架构的通用解决方案,无需为特定注意力变体重写内核级代码。在某种程度上,消除 PP 气泡比实现 PP 本身更困难。
| 指标 | 张量并行(TP) | 上下文并行(CP) | 流水线并行(PP) |
|---|---|---|---|
| 分割维度 | 隐藏状态() | 序列() | 层() |
| 通信模式 | AllReduce(每层) | AllGather(每层) | P2P(发送 / 接收) |
| 通信量 | 高 | 中 | 低 |
| 气泡率 | 0 | 0 | |
| 实现复杂性 | 低 | 高(注意力变体特定) | 中 |
| 架构通用性 | 高 | 低 | 高 |
总之,通用性与扩展效率之间的平衡,使 PP 不仅是一种替代方案,更是将长上下文预填充扩展到大规模多节点集群时的 必要组件,因为 TP 和 CP 会在那里遇到带宽上限。同时,CP 也有潜力补充 TP,以实现节点内无气泡扩展和加速。PP × CP 已在开发中(见 未来路线图),并将包含在本博客的第二部分。
挑战:“气泡”与“墙”¶
在传统流水线并行设置中,模型层跨 GPU 分区(阶段 1 到阶段 N)。当处理标准请求(例如小于 4K 个令牌)时,这通常工作良好。然而,当处理超过 128K 甚至 1M 个令牌 的提示时,会出现两个关键问题:
- **流水线气泡:**将提示作为整体批次处理会迫使下游 GPU 长时间空闲,形成巨大的“流水线气泡”,严重降低吞吐量。
- **内存墙:**在单次传递中处理 100 万令牌提示,需要存储和通信整个序列的中间隐藏状态,导致显著开销和峰值内存占用。
SGLang 流水线并行架构¶
SGLang 的流水线实现超越了标准的“顺序”方法。我们引入了多个高级功能,以最小化“气泡”(即 GPU 空闲时间)并最大化硬件利用率。
1. 分块流水线并行(CPP)¶
在单次前向传递中处理 100 万令牌提示会导致巨大气泡,因为后续阶段必须等待第一阶段完成。受 Mooncake、BladeLLM 和 TeraPipe 等系统的启发,SGLang 支持分块流水线并行(Chunked Pipeline Parallelism)。不同于将完整提示词输入流水线,SGLang 会将提示词划分为更小的“块”(例如 4K 或 6K 个令牌)。这些块像微批次一样流过流水线各阶段。通过将长提示词分解为小块,系统可以对预填充(prefill)阶段进行“流水线化”。一旦第一阶段完成对块 1 的隐藏状态计算并启动 PP 通信,它就会立刻转向处理块 2,而第二阶段则同时开始处理块 1。这将流水线启动延迟从与总序列长度成正比,降低到仅与第一个块的大小成正比。
从工程角度看,这一方法是应对超长上下文挑战的关键第一步。值得注意的是,SGLang 早在六个多月前就率先支持了此功能(#5724、#8846),突显了其长期以来对优化现实世界长上下文推理的承诺。
2. 更好的重叠:微批次与异步点对点通信¶
尽管结合流水线并行(Pipeline Parallelism)与分块预填充(Chunked Prefill)相比张量并行能显著减少通信量,但它常受流水线气泡(pipeline bubbles)困扰,即 GPU 在等待 CPU 元数据处理或网络传输时被阻塞。为消除此性能隐患,SGLang 实现了一个微批次事件循环(Micro-batching Event Loop),配合非阻塞的异步点对点(P2P)通信,以重叠 GPU 计算、CPU 元数据处理和 PP 通信。这确保当一个微批次在 GPU 上计算时,下一个微批次已在准备并有效就位,从而尽可能保持流水线饱和。代码可在 此处 查看。
实现的关键机制包括:
- **事件循环中的解耦同步 / 异步逻辑:**调度器在
async_send中使用_pp_send_pyobj_to_next_stage。它不会等待传输完成,而是返回一个P2PWork句柄。实际同步(P2PWork.work.wait())会推迟到调用_pp_commit_comm_work时进行,因此 CPU 可以在数据传输过程中执行其他工作——例如调度下一个批次或处理元数据。 - **多流执行:**除了作为同步流的主
default_stream外,SGLang 还利用专用的forward_stream和copy_stream,分别执行前向传递 GPU 计算和数据到主机(D2H)内存传输,以实现更好的重叠。当_pp_launch_batch在当前阶段的 GPU 上执行当前微批次时,CPU 会使用_pp_process_batch_result处理上一个微批次的结果。
3. 高级选项:动态分块¶
通过分块流水线并行(Chunked Pipeline Parallelism)和异步点对点(P2P)通信,SGLang 在 PP 规模增加到 4 时已实现超过 80% 的强扩展效率。然而,使用固定大小的分块预填充仍可能在流水线中产生气泡,而且随着 PP 度增加,这种低效性会变得更加明显。其主要原因在于,模型在相同大小的块上会表现出不均匀的执行延迟,这主要归因于自注意力(self-attention)的增量特性。随着前缀序列长度增长,每个块的处理时间会以非线性方式增加。这些时间错配会在流水线中传播,并在更高的 PP rank 上进一步放大效率损失。
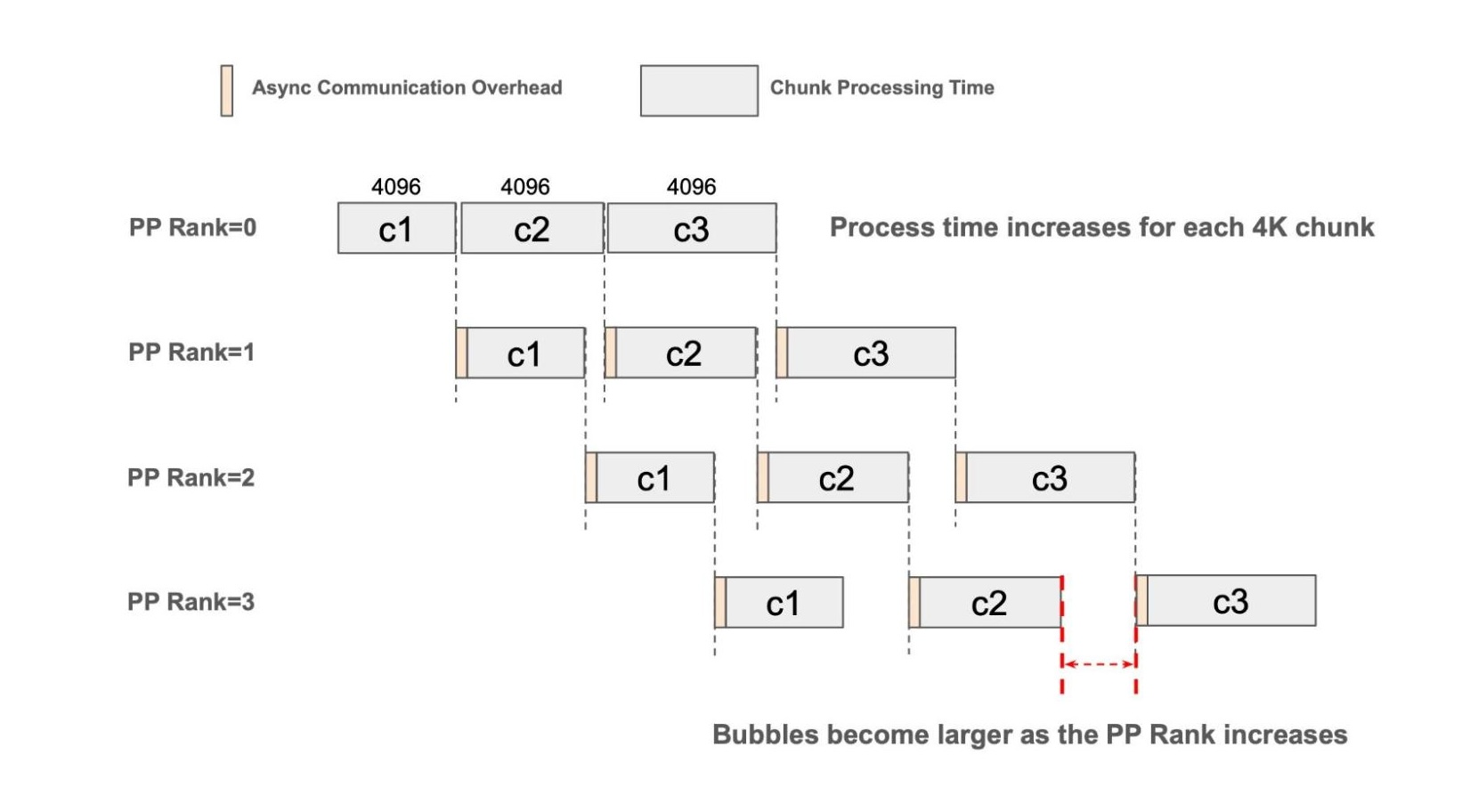
图 1:固定分块预填充大小的流水线示意图
我们使用较大的 PP 规模测试了不同模型,发现它们都符合这一结论。以下是一个典型案例的性能分析结果。
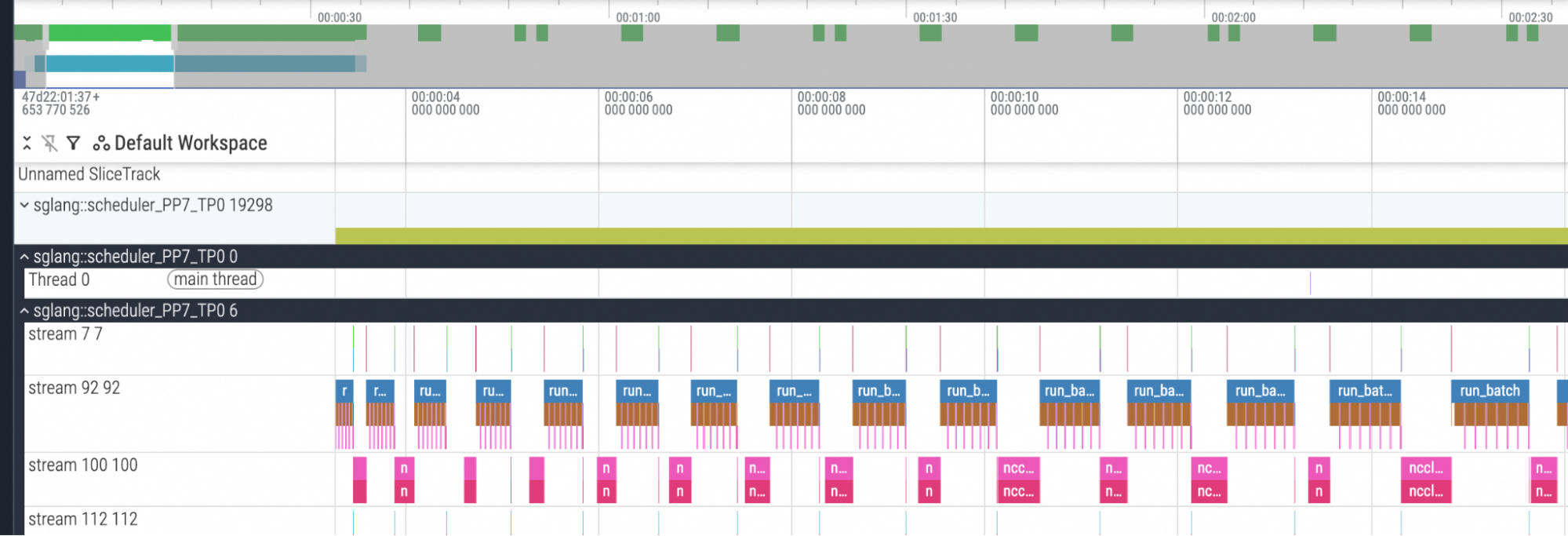
图 2:PP rank 7 在固定分块预填充大小下的性能分析结果
因此,如果 SGLang 在 CPP 中仍使用固定的分块预填充大小,流水线气泡率将高于理论预期,即 。
为解决此问题,SGLang 引入了动态分块机制,用于预测下一个块的最优大小,使其满足如下条件:。
其中, 表示前缀序列长度(Prefix Sequence Length), 表示下一个块大小(Next Chunk Size)。通过分析一系列具有不同 ITL 的请求,我们将累积运行时间建模为序列长度的二次函数。利用此模型,我们可以求解出任意给定前缀长度 对应的最优下一个块大小 。由于注意力(Attention)机制的计算 / 通信复杂度会随 增长,下一个块大小也会随着 增大而逐渐减小,以保持流水线各阶段间块执行时间的对齐。
基于这一方法,调度器可以在运行时预测并动态减小块大小,以最小化由阶段错位引起的气泡。需要注意的是,调度器不会直接使用原始预测值。为了便于高效的 KVCache 内存管理,并确保与硬件执行效率相匹配,该值会向下对齐到最接近 max(--page-size, 64) 倍数的位置。
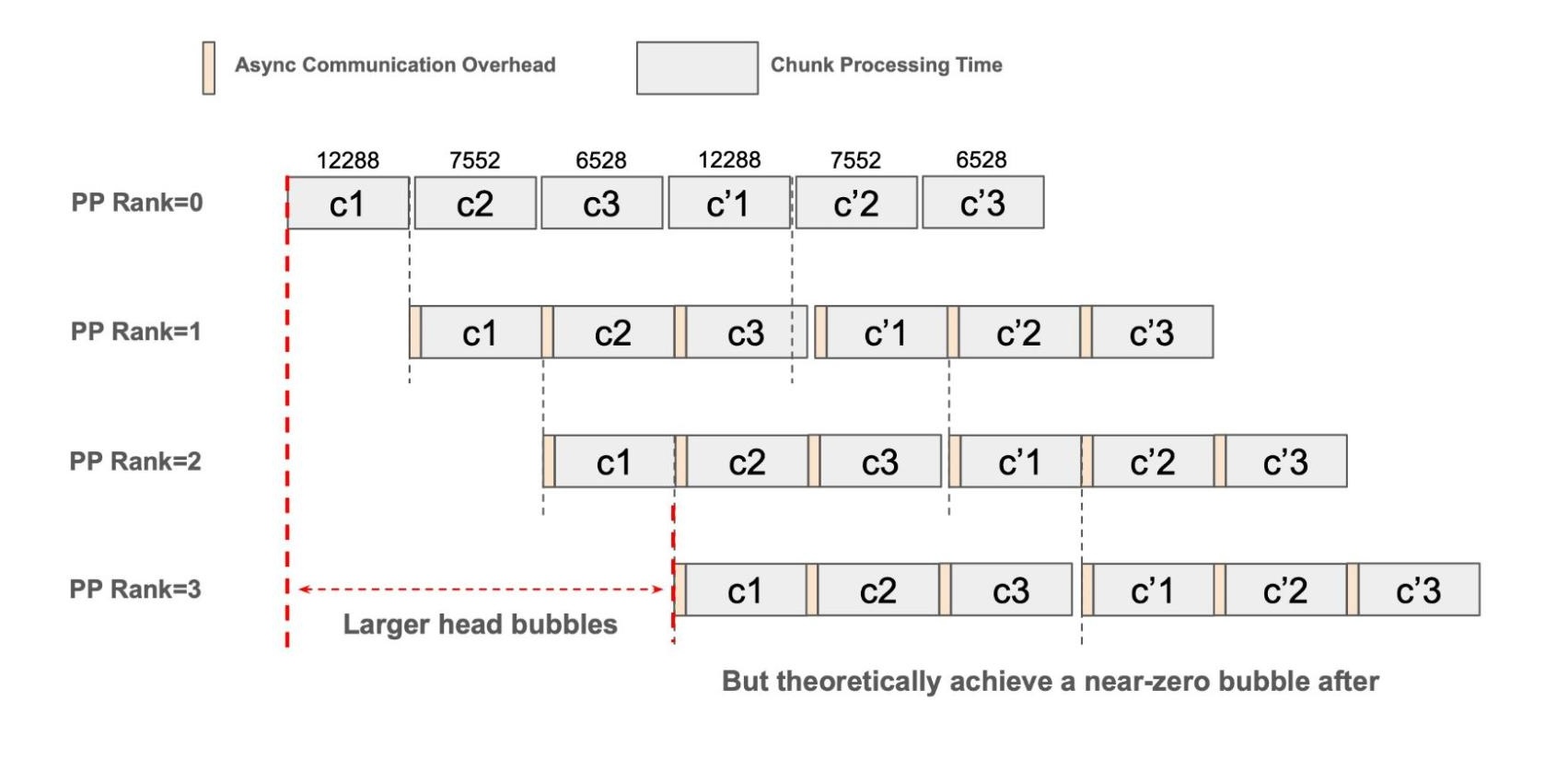
图 3:完美动态分块的流水线示意图
然而,由于硬件、模型和目标工作负载的差异,静态配置几乎不可能在所有场景下都达到最优。因此,切换到动态分块模式后,要实现峰值性能通常需要一定程度的超参数调优。此外,我们发现由于不同形状的内核性能变化,很难完美拟合该二次函数。因此,我们引入了环境变量 SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR,用于平滑动态分块算法的缩减,默认值为 0.75。它决定了预填充阶段块大小允许变化的幅度。较大的值会导致更激进的块大小缩减,可能提升性能,但也会增加总块数(末尾的块大小可能变得非常小,从而导致性能下降)。
动态分块预填充调优指南¶
- **步骤 1:迭代寻找目标 PP 大小的最优固定分块预填充大小。**针对不同目标 ITL,不同 PP 大小可能具有不同的最优分块预填充大小。因此,用户应根据可用扩展资源反复迭代,以获得基线。
- **步骤 2:选择动态分块的初始块大小。**将初始大小设置为最优固定分块预填充大小的 2 倍或 3 倍。这可以减少总块数,并防止“尾部分块”无法充分利用硬件。为了在极大 ITL 下保持效率,动态预测器还会自动确保后续分块至少为该初始大小的 1/4。此外,对于这类情况,也建议使用更大的初始分块大小(例如最优固定分块预填充大小的 4 倍)。
- **步骤 3:调整平滑因子。**该因子控制分块大小对二次性能拟合模型预测值的跟随程度。
- 1.0:严格遵循模型。
- **0.6 – 0.85(推荐):**在动态扩展与硬件稳定性之间通常能取得最佳平衡。实验表明,0.6 到 0.85 的范围通常能为动态分块带来最佳性能,如图 4 和图 5 所示。
- 0:禁用动态调整,恢复为传统的固定大小分块。
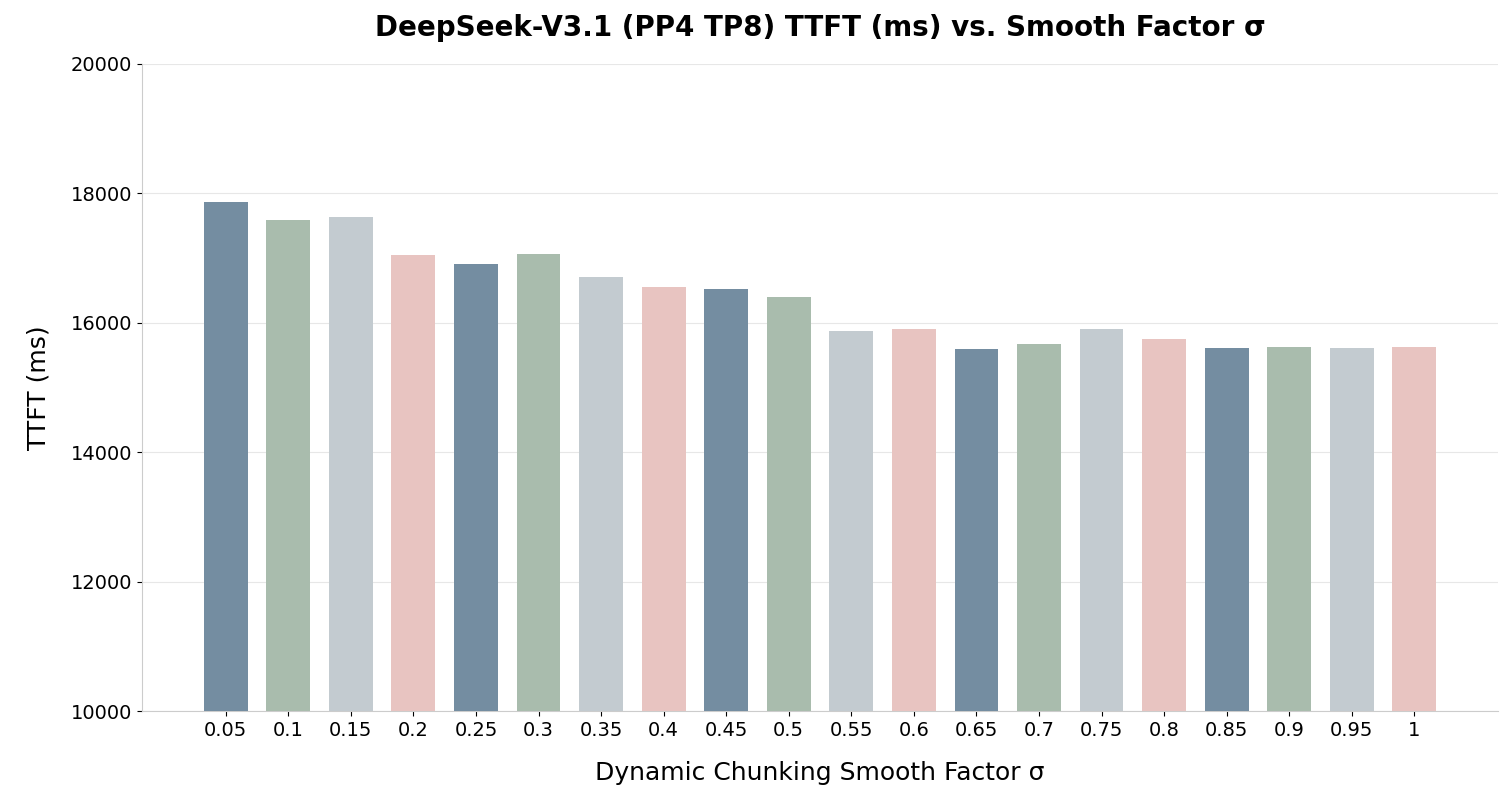
图 4:为 DeepSeek-V3.1 调整平滑因子的示例(数值越低越好)
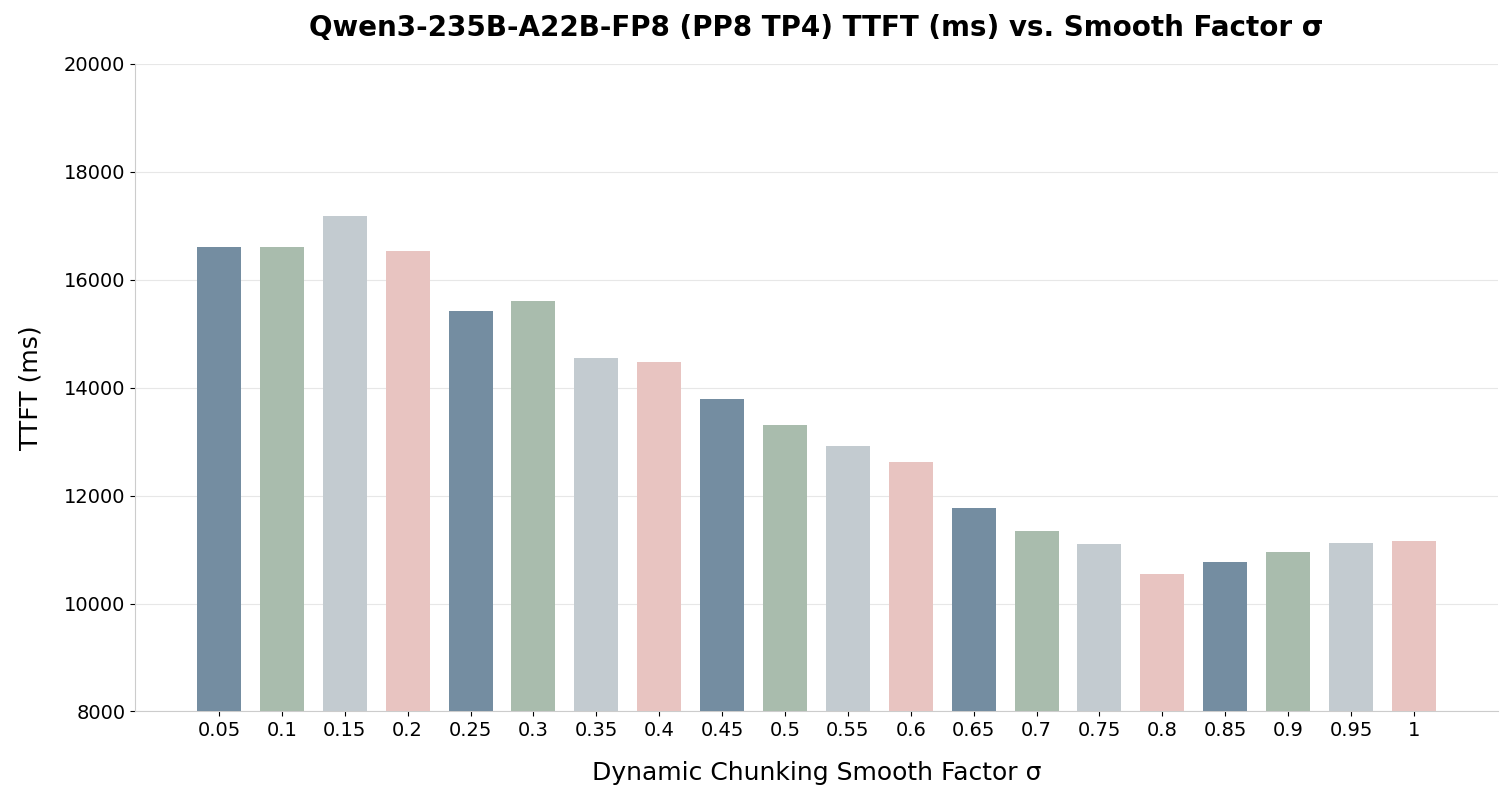
图 5:为 Qwen3-235B-A22B-FP8 调整平滑因子的示例(数值越低越好)
- **另一个小优化技巧:**当层无法在多个 rank 间均匀分配时,应将较大的分区放在较高的 PP rank 上。当较高的 PP rank 等待前一阶段结果时,这有助于提高 GPU 利用率,从而减少较高 PP rank 上的气泡。以 DeepSeek-V3.1 为例,
SGLANG_PP_LAYER_PARTITION=15,15,15,16通常比16,15,15,15表现更好。
为了验证这些组合策略的有效性,我们分析了使用动态分块的 DeepSeek-V3.1 执行情况。如下文 PP rank 3 的分析结果所示,与静态分块方法相比,流水线气泡显著减少,从而实现了更饱和的执行。
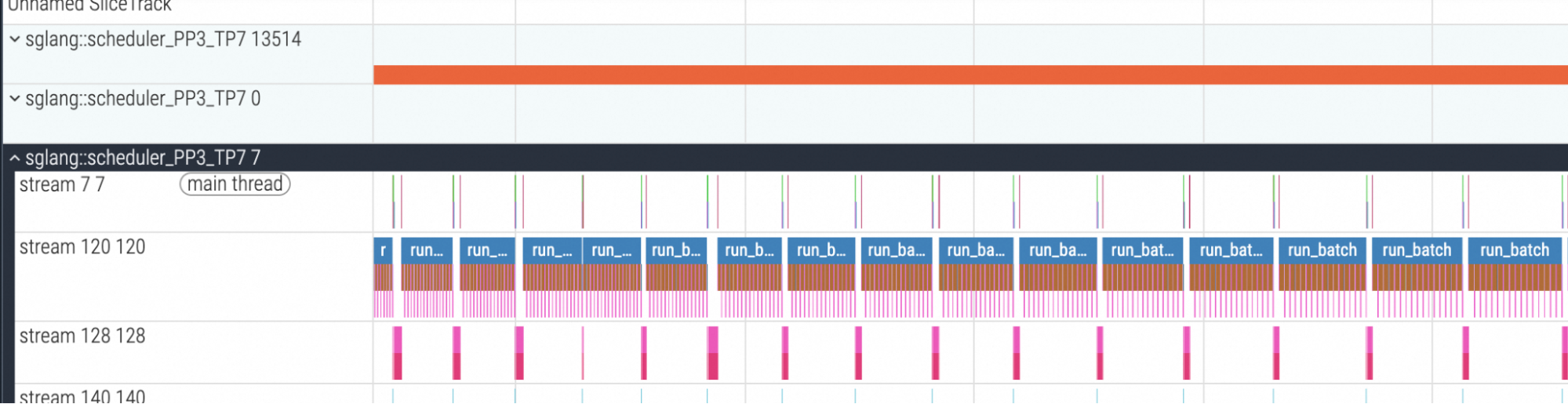
图 6:使用动态分块的 PP rank 3 分析结果(DeepSeek-V3.1)
4. 生产就绪:与 PD 解耦和 HiCache 的兼容性¶
SGLang 的一个独特优势,是它原生支持流水线设置中的 预填充 - 解码(PD)解耦。在解耦集群中,预填充节点可以使用高程度的 PP 来处理极长上下文提示,而解码节点则可以利用不同的并行策略(如高程度 TP)来最大化令牌生成速度。
- **逐块 KVCache 传输:**SGLang 支持 Mooncake 之类的传输引擎后端。当启用 PD 解耦时,它可以在一个分块完成后立即将该分块的 KVCache 从预填充节点传输到解码节点,而不是等待所有分块完成。此功能可大幅降低 KVCache 传输开销。
- **灵活的混合策略:**SGLang 允许用户在 PD 解耦中混合使用多种并行方式。你可以在一组预填充节点上为重型预填充任务运行 PP8 TP8,并为高吞吐量解码应用其他组合,例如 PP1 TP8、PP8 TP1 和 PP1 DP16 EP16,从而针对推理生命周期的不同阶段进行优化。这让用户可以用高度可定制的方式满足生产环境中的 TTFT 和 TPOT 目标。
- **内存效率:**通过跨设备分布模型权重,PP 降低了每张 GPU 的内存占用,允许更大的 KV 缓存和更高的并发性。因此,在某些情况下,它还可以用于扩展最大上下文长度。
当处理超过 128K 令牌的上下文时,SGLang 还支持将分块流水线并行与 HiCache 这一分布式分层 KV 缓存系统结合,以进一步降低多轮问答和智能体应用在超长初始 ITL 情况下的 TTFT:
- **语义前缀匹配:**SGLang 的 HiCache 使用基于基数树的层次结构,在分块级别匹配前缀。当长上下文请求到达时,SGLang 可以执行分层缓存查找。如果前缀令牌(在先前分块中处理过)已经缓存在 HiCache 的“存储”层(例如主机内存或本地磁盘)中,PP 流水线就可以完全跳过这些分块,从而大幅降低 TTFT。
性能影响¶
本节对 DeepSeek-V3.1 和 Qwen3-235B-A22B-FP8 模型的 PP 性能特征进行了严格的定量评估。分析重点放在 PP 大小、动态分块(DCK)以及硬件可扩展性之间的相互作用。
我们的实验平台是一个由 6 个 H20 节点(8 × 96 GB VRAM GPU)组成的小型集群。由于测试资源有限,未对 DeepSeek-V3.1 进行 PP 度为 8 的实验。此外,对于 DeepSeek-V3.1 的 PP 大小 = 1 配置,我们使用了一个独立的 H20 节点(8 × 141 GB VRAM GPU)来获得 128K 输入令牌长度下的基线性能,因为在 96 GB VRAM 版本上会发生 OOM。为了更好地验证流水线饱和时的吞吐性能,我们在吞吐测试中对 16 个连续请求进行了基准测试,并测量了平均值。
注意:我们使用记号 DCK 表示启用动态分块时的分块预填充大小设置,使用 σ 表示动态分块(dynamic chunking)的平滑因子。为了进行极长上下文实验,我们将上述模型的上下文长度覆盖为 100 万,仅用于性能分析。此外,我们尝试为 DeepSeek-V3.1 配置 TP32、为 Qwen3-235B-A22B-FP8 配置 TP8 进行实验,但遗憾的是,大 TP 配置本质上并不受支持,因为权重量化块无法被 FFN(MoE)层的权重整除(相关问题)。为了在多节点扩展场景中彻底比较 TP 和 PP 的差异,我们修改了 DeepSeek-V3.1 的模型实现文件(在 load_weights 中跳过部分权重加载)和 config.json(变通方案讨论),最终仅为性能验证目的让 TP32 得以运行。
输入令牌吞吐量与强扩展效率¶
吞吐量(Throughput)与 PP 大小的分析表明,两个模型系列都表现出很强的横向可扩展性,不过扩展效率的程度因配置而异。
- **PP vs. TP:**实验数据中的一个关键现象是,当张量并行(Tensor Parallelism,TP)扩展到 16 时,相较于混合并行方案(PP2 TP8),性能出现下降。尽管使用了相同的 GPU 总数,PP2 TP8 在吞吐量和延迟指标上始终优于 PP1 TP16。此外,对于所有分块大小配置,PP4 TP8 在吞吐量和延迟指标上也始终优于 PP1 TP32。值得注意的是,在固定分块大小为 12288 的情况下,这一设置在 PP4 TP8 的所有分块策略中表现最差。然而,PP4 TP8 的最差表现仍显著优于 PP1 TP32(后者的固定分块大小同样为 12288),优势幅度达到 18.4%;而在启用动态分块后,这一优势进一步扩大到 30.5%。这些结果突显了 PP 方法的内在优势。
- DCK 的卓越可扩展性: Qwen DCK 18K 配置表现出最高的可扩展性,在 PP8(32 个 GPU)时相比 PP1(4 个 GPU)实现了 6.14× 的加速因子。这一结果表明,分块大小的动态调整优化了计算强度与节点间通信延迟之间的平衡。
- 架构比较: DeepSeek 模型在达到 PP4 阈值之前,表现出与 Qwen 相当的可扩展轨迹。值得注意的是,DeepSeek DCK 12K(3.31×) 略微优于静态 4K 变体(3.20×),验证了动态分块(Dynamic Chunking)策略在提升吞吐量方面具备跨架构鲁棒性。
图 7:DeepSeek-V3.1 的吞吐量分析(越高越好)
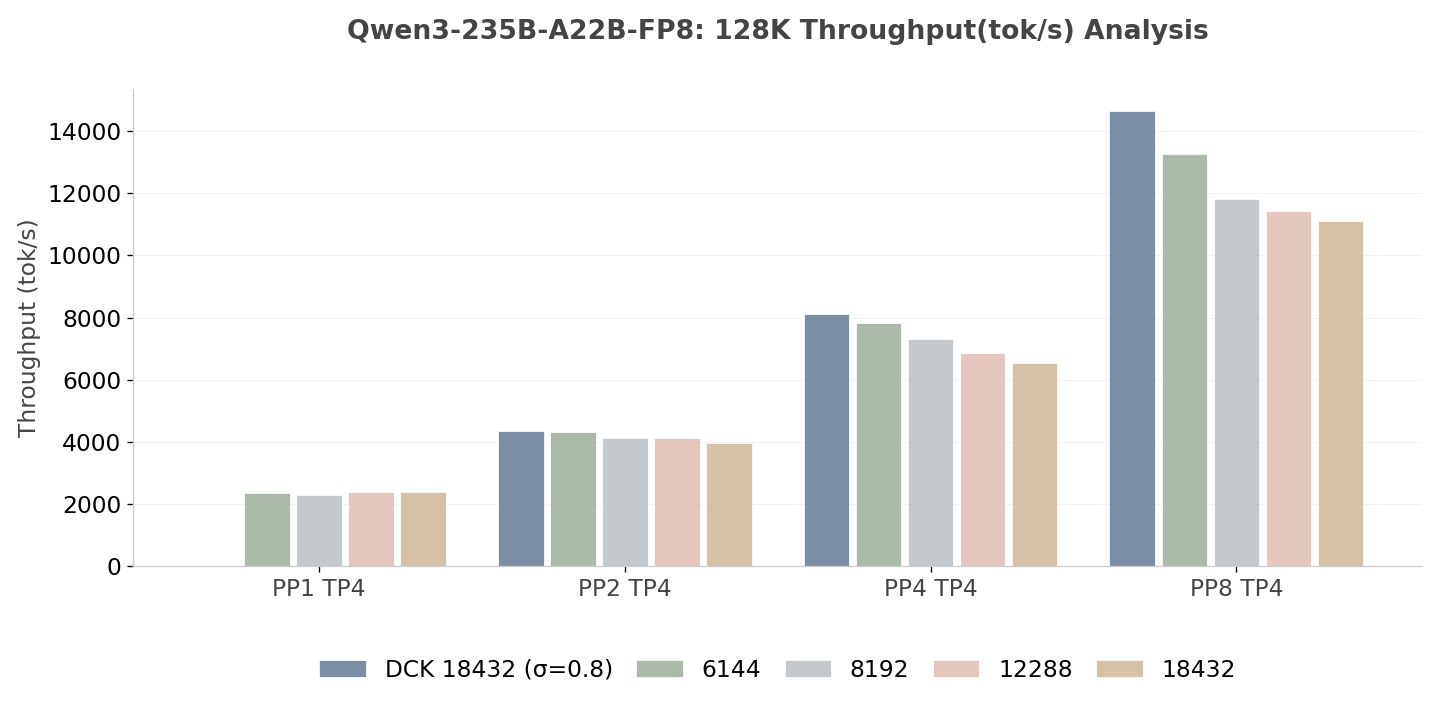
图 8:Qwen3-235B-A22B-FP8 的吞吐量分析(越高越好)
强扩展效率曲线说明了随着系统扩展,硬件利用率会逐步下降。对于强扩展效率分析,ITL 保持为 128K,而 持续增加,因此根据公式,气泡率下限必然会更高。所有配置在 PP 大小(GPU 数量)增加时都表现出效率的单调衰减。然而,Qwen DCK 18K 在 PP8 规模下仍保持 76.9% 的优异效率,而静态 6K 配置则降至 69.6%。这证实了更大、动态管理的分块对由流水线气泡引起的性能下降更具弹性。由于资源限制,DeepSeek-V3.1 仅评估到 PP 大小 = 4,仍保持 82.8% 的效率。根据当前斜率推断,DeepSeek 很可能会遵循与 Qwen 类似的效率轨迹,其中 DCK 预计将优于固定分块策略。
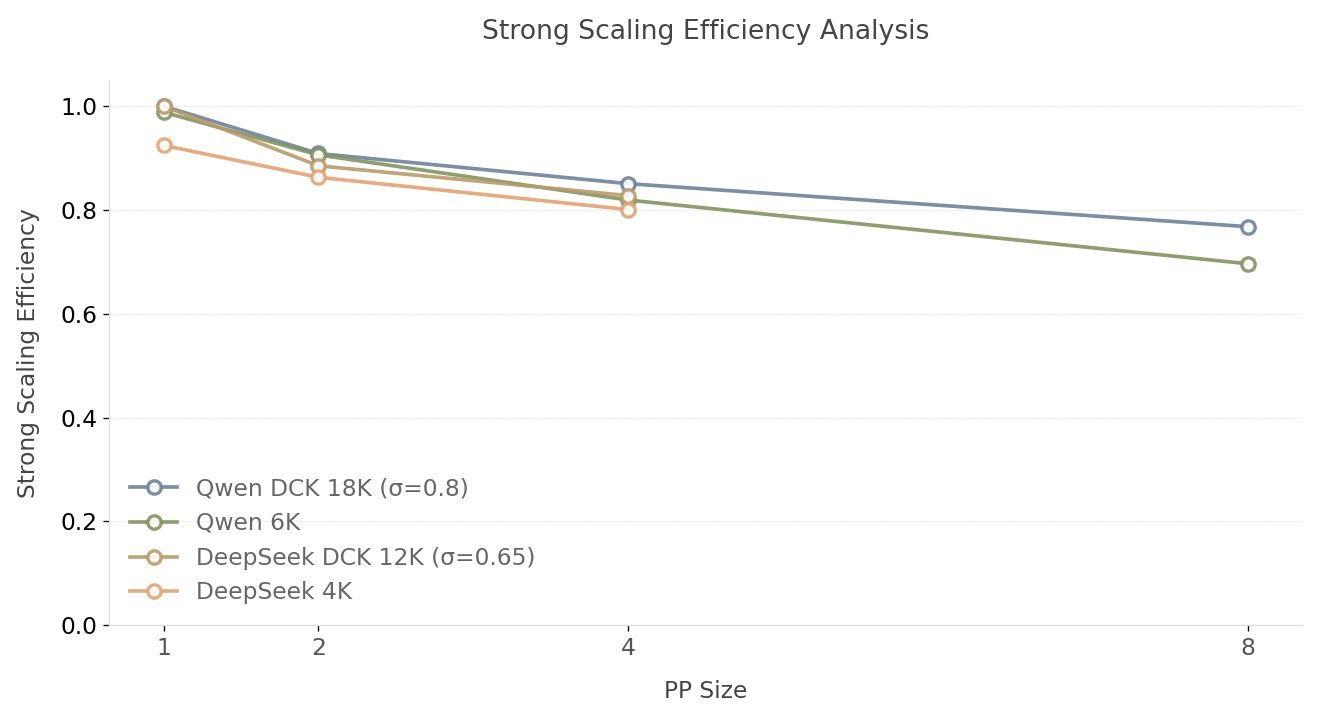
图 9:强扩展效率与 PP 大小分析(越高越好)
降低 TTFT 及向 100 万 ITL 扩展¶
从图 10 和图 11 中可以观察到,将 PP 大小从 PP1 增加到 PP4,能够在固定分块设置和动态分块两种情况下显著降低 TTFT,而动态分块在不同 PP 设置下表现更好。对于 Qwen3-235B-A22B-FP8,基线 TTFT 约为 55.5 s(PP1 TP4),在 PP8 TP4 配置下可降低到约 10.5 s,对应约 81.1% 的延迟改进。对于 DeepSeek-V3.1,基线 TTFT 约为 48.5 s(PP1 TP8),在 PP4 TP8 配置下可降低到约 15.5 s,对应约 67.9% 的延迟改进。这些结果表明,分块流水线并行(Chunked Pipeline Parallelism)对于降低 TTFT 非常有效。
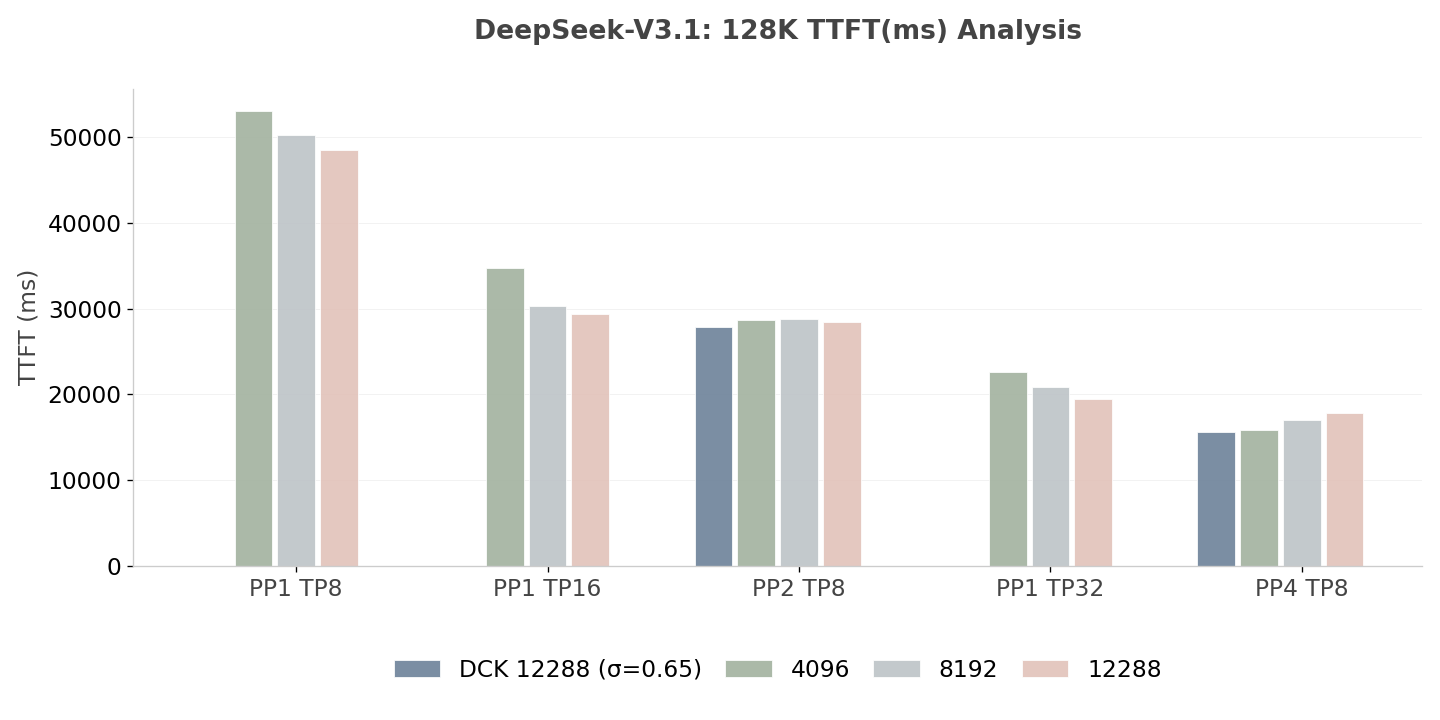
图 10:DeepSeek-V3.1 的 TTFT 分析(越低越好)
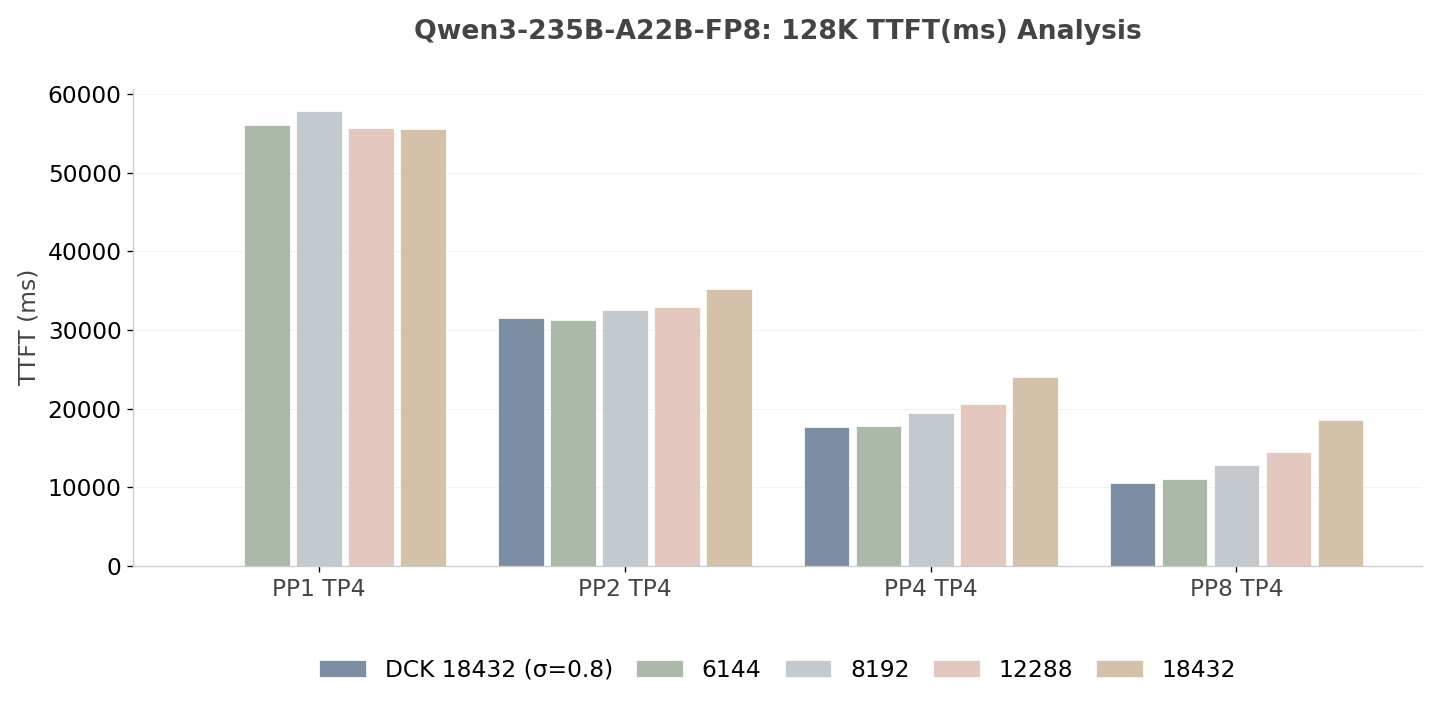
图 11:Qwen3-235B-A22B-FP8 的 TTFT 分析(越低越好)
为了展示 SGLang 配合这一优化后的分块流水线并行的可扩展性,我们针对 Qwen3-235B-A22B-FP8 在 PP8(32 个 NVIDIA H20 GPU)配置下,对不同输入令牌长度的 TTFT 进行了基准测试。如下表所示,该系统能够高效扩展以处理大规模上下文。即使在 100 万令牌的极端场景下,SGLang 在 NVIDIA H20 上仍保持了高稳定性和可接受的延迟,展示了其应对最苛刻长上下文应用的能力。
表 1:Qwen3-235B-A22B-FP8 在 H20 上 PP8 TP4 配置的 TTFT 与输入令牌长度对比
| 输入令牌长度 | 128K | 256K | 512K | 1M |
|---|---|---|---|---|
| TTFT(s) | 10.54 | 32.68 | 114.33 | 420.91 |
利用比 H20 具有更高计算能力和带宽的硬件,或者扩展到更多节点上的更大 PP 规模(例如 DeepSeek-V3.1 模型的 PP8 TP16),还可以进一步降低百万令牌上下文的 TTFT。我们也邀请社区在不同硬件配置上尝试这一新功能:欢迎分享你的性能发现并报告遇到的任何错误。若有问题,也可以在 PP 路线图 中继续交流。你的反馈对于帮助我们完善这些长上下文优化至关重要。此外,也请关注我们即将推出的 CP × PP 实现——DeepSeek-V3.2 的初始支持已在主分支可用。
入门指南¶
要利用这些功能,你只需配置 --pp-size 和 --chunked-prefill-size。如果要进一步启用动态分块方案,请使用 --enable-dynamic-chunking,并设置环境变量 SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR。
注意:所需的 SGLang 发布版本为 >= v0.5.7。
示例:
# Example: Serving DeepSeek-V3.1 with 128K Input Token Length (32 GPUs total)
# Using 8-way Tensor Parallelism and 4-way Pipeline Parallelism
# prefill node 0 (fixed chunked prefill size)
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.1 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 8 --pp-size 4 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 4096
# prefill node 0 (with dynamic chunking)
export SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR=0.65
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.1 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 8 --pp-size 4 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 12288 --enable-dynamic-chunking
# Example: Serving Qwen3-235B-A22B-FP8 with 128K Input Token Length (32 GPUs total)
# Using 4-way Tensor Parallelism and 8-way Pipeline Parallelism
# prefill node 0 (fixed chunked prefill size)
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-235B-A22B-FP8 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 4 --pp-size 8 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 6144
# prefill node 0 (with dynamic chunking)
export SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR=0.8
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-235B-A22B-FP8 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 4 --pp-size 8 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 18432 --enable-dynamic-chunking# Example: Serving DeepSeek-V3.1 with 128K Input Token Length (32 GPUs total)
# Using 8-way Tensor Parallelism and 4-way Pipeline Parallelism
# prefill node 0 (fixed chunked prefill size)
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.1 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 8 --pp-size 4 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 4096
# prefill node 0 (with dynamic chunking)
export SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR=0.65
python3 -m sglang.launch_server \
--model-path deepseek-ai/DeepSeek-V3.1 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 8 --pp-size 4 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 12288 --enable-dynamic-chunking
# Example: Serving Qwen3-235B-A22B-FP8 with 128K Input Token Length (32 GPUs total)
# Using 4-way Tensor Parallelism and 8-way Pipeline Parallelism
# prefill node 0 (fixed chunked prefill size)
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-235B-A22B-FP8 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 4 --pp-size 8 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 6144
# prefill node 0 (with dynamic chunking)
export SGLANG_DYNAMIC_CHUNKING_SMOOTH_FACTOR=0.8
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-235B-A22B-FP8 --trust-remote-code \
--nnodes 4 --node-rank 0 --tp 4 --pp-size 8 \
--port 30000 --dist-init-addr <MASTER_NODE_IP> \
--mem-fraction-static 0.8 --attention-backend fa3 \
--host 0.0.0.0 --watchdog-timeout 3600 \
--max-running-requests 128 --chunked-prefill-size 18432 --enable-dynamic-chunking未来路线图¶
我们正在持续完善 PP 栈。2026 年上半年的 PP 路线图包括以下重要任务:
- 与上下文并行(Context Parallelism)兼容,以进一步降低 TTFT。
- 解码侧的流水线并行(Pipeline Parallelism)。
- 性能优化与最佳实践调优。
- 动态分块更好的拟合与分块策略。
结论¶
SGLang 的流水线并行(Pipeline Parallelism)实现不仅仅是模型分割;它是长上下文时代对推理生命周期的一次全面重构。通过结合分块预填充、异步通信和动态分块,SGLang 为长上下文场景下服务并加速万亿参数模型提供了高效且开源的路径。