引言¶
在许多 PyTorch 应用中,将数据从 CPU 传输到 GPU 是基础操作。了解在设备之间移动数据最有效的工具和选项至关重要。本教程考察了 PyTorch 中用于设备间数据传输的两个关键方法:pin_memory() 和带有 non_blocking=True 选项的 to()。
你将学到什么¶
优化从 CPU 到 GPU 的张量传输可以通过异步传输和固定内存实现,但需要注意几点:
- 使用
tensor.pin_memory().to(device, non_blocking=True)的速度可能比直接tensor.to(device)慢一倍。 - 通常来说,
tensor.to(device, non_blocking=True)能有效提升传输速度。 - 对 CPU 张量执行
cpu_tensor.to("cuda", non_blocking=True).mean()可以正确运行,但尝试在 GPU 张量上调用cuda_tensor.to("cpu", non_blocking=True).mean()会得到错误的输出。
前言¶
本教程中报告的性能依赖于构建教程所用的系统。虽然结论在不同系统中都适用,但具体观察可能会因硬件差异而有所不同,尤其是旧硬件。本教程的主要目标是提供一个理解 CPU 至 GPU 数据传输的理论框架。然而任何设计决策应根据具体情况、基准吞吐量测量以及任务需求来决定。
import torch
assert torch.cuda.is_available(), "需要一块 CUDA 设备才能运行本教程"import torch
assert torch.cuda.is_available(), "需要一块 CUDA 设备才能运行本教程"本教程需要安装 tensordict。如果你的环境中还没有 tensordict,可以通过以下命令安装:
# 安装 tensordict
!pip3 install tensordict# 安装 tensordict
!pip3 install tensordict我们首先梳理这些概念背后的理论,然后再给出功能的实际测试示例。
背景¶
内存管理基础¶
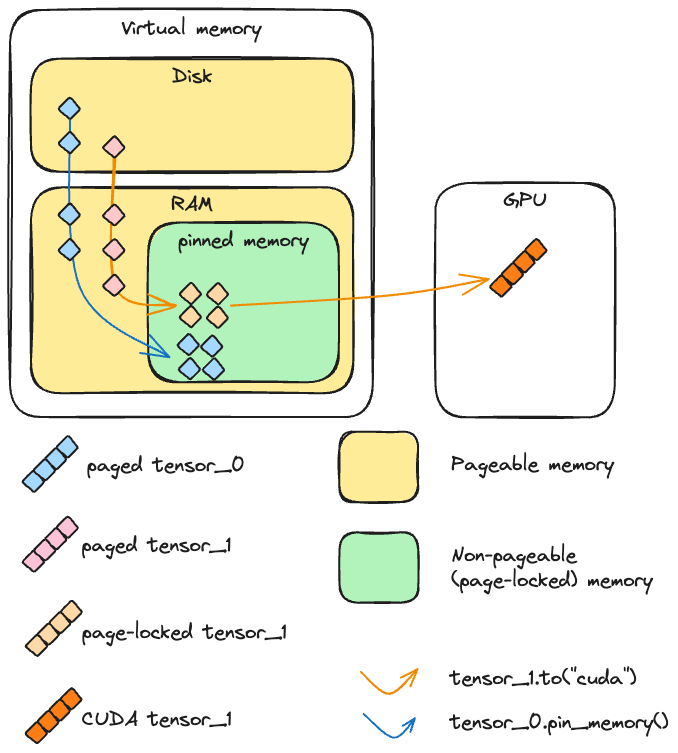
在 PyTorch 中创建 CPU 张量时,其内容需要存放在内存中。这里所说的内存是一个值得仔细理解的复杂概念。我们将由内存管理单元管理的两类内存区分开来:简化而言的 RAM,以及磁盘上的交换空间。磁盘空间与物理内存合起来构成虚拟内存,它抽象出可用资源的总和,使得可用空间看起来比单独的主存更大,从而营造出主存更大的假象。
在正常情况下,普通的 CPU 张量是可分页的,这意味着它被划分为称为“页面”的块,这些页面可以存在于虚拟内存的任何位置(无论是 RAM 还是磁盘)。如前所述,这让可用内存看起来比实际的主存更大。
当程序访问不在 RAM 中的页面时,会发生“缺页”异常,操作系统会将该页面调回 RAM(交换入);相应地,操作系统可能需要将另一页交换出去以为新页面腾出空间。
与可分页内存不同,固定(或锁页、不可分页)内存是一种不能被换出到磁盘的内存类型,它提供更快、更可预测的访问时间,但代价是容量比可分页内存(即主存)更有限。
固定内存与分页内存示意图
CUDA 与(不可)分页内存¶
要理解 CUDA 如何将张量从 CPU 复制到 CUDA,我们考虑上述两种情况:
- 若内存被锁页,设备可以直接访问主存中的这块内存。内存地址清晰可用,需要读取这些数据的函数可以明显加速。
- 若内存可分页,则在发送到 GPU 之前,所有页面都必须调入主存。这个操作可能耗时,而且相比锁页内存不够可预测。
更具体地说,当 CUDA 从 CPU 向 GPU 发送可分页数据时,它必须先创建该数据的一个锁页副本,然后才能进行传输。
带 non_blocking=True 时的异步与同步操作(CUDA cudaMemcpyAsync)¶
当从主机(如 CPU)到设备(如 GPU)执行复制时,CUDA 工具包提供了同步或异步的模式。
在实践中,调用 to() 时 PyTorch 总是会使用 cudaMemcpyAsync。如果 non_blocking=False(默认值),在每次 cudaMemcpyAsync 调用后都会调用 cudaStreamSynchronize,这使得对 to() 的调用在主线程上是阻塞的。如果 non_blocking=True,则不会触发同步,主机侧的主线程不会被阻塞。因此从主机的角度看,可以同时将多个张量发送到设备,因为线程无需等待一个传输完成再发起下一个。
一般而言,传输在设备端仍然是阻塞的(即使在主机端不是):当设备正在执行其他操作时,复制无法进行。不过在某些高级场景中,可以在 GPU 端同时执行复制与内核运算。如下示例将展示,要启用这种重叠需要满足以下三个条件:
- 设备必须至少有一个空闲的 DMA(直接内存访问)引擎。现代 GPU 架构例如 Volterra、Tesla 或 H100 等都拥有多个 DMA 引擎。
- 传输必须在一个非默认的 CUDA 流上完成。在 PyTorch 中,可以使用
Stream来操作 CUDA 流。- 源数据必须位于固定内存中。
随后教程运行了一个脚本来用 profiler 展示上述情况的时间线,这里不再赘述详细代码,重点是只有当源数据在固定内存且在单独的流上执行复制时,复制过程才能与主流上的 CUDA 运算重叠。
PyTorch 视角¶
pin_memory()¶
PyTorch 提供了通过 pin_memory() 方法或构造函数参数将张量放入锁页内存的功能。在初始化了 CUDA 的机器上,可以通过 pin_memory() 方法将 CPU 张量转换为锁页内存。需要注意的是,pin_memory() 会在主线程上阻塞:它会等待张量被复制到锁页内存之后才执行下一步操作。通过 zeros()、ones() 等构造函数可以直接在锁页内存中创建新张量。
我们可以查看将内存锁页或发送张量到 CUDA 的速度:
import torch
import gc
from torch.utils.benchmark import Timer
import matplotlib.pyplot as plt
def timer(cmd):
median = (
Timer(cmd, globals=globals())
.adaptive_autorange(min_run_time=1.0, max_run_time=20.0)
.median
* 1000
)
print(f"{cmd}:{median: 4.4f} ms")
return median
# 可分页内存中的张量
pageable_tensor = torch.randn(1_000_000)
# 锁页内存中的张量
pinned_tensor = torch.randn(1_000_000, pin_memory=True)
# 运行时间:
pageable_to_device = timer("pageable_tensor.to('cuda:0')")
pinned_to_device = timer("pinned_tensor.to('cuda:0')")
pin_mem = timer("pageable_tensor.pin_memory()")
pin_mem_to_device = timer("pageable_tensor.pin_memory().to('cuda:0')")
# 比例:
r1 = pinned_to_device / pageable_to_device
r2 = pin_mem_to_device / pageable_to_deviceimport torch
import gc
from torch.utils.benchmark import Timer
import matplotlib.pyplot as plt
def timer(cmd):
median = (
Timer(cmd, globals=globals())
.adaptive_autorange(min_run_time=1.0, max_run_time=20.0)
.median
* 1000
)
print(f"{cmd}:{median: 4.4f} ms")
return median
# 可分页内存中的张量
pageable_tensor = torch.randn(1_000_000)
# 锁页内存中的张量
pinned_tensor = torch.randn(1_000_000, pin_memory=True)
# 运行时间:
pageable_to_device = timer("pageable_tensor.to('cuda:0')")
pinned_to_device = timer("pinned_tensor.to('cuda:0')")
pin_mem = timer("pageable_tensor.pin_memory()")
pin_mem_to_device = timer("pageable_tensor.pin_memory().to('cuda:0')")
# 比例:
r1 = pinned_to_device / pageable_to_device
r2 = pin_mem_to_device / pageable_to_device这段代码展示了从可分页与锁页内存将张量传输到 GPU 的耗时。可以观察到,直接将锁页内存中的张量转移到 GPU 确实比可分页张量更快,因为在底层可分页张量必须先被复制到锁页内存才能传输。
然而,与一些普遍的看法相反,在可分页张量上先调用 pin_memory() 再 cast 到 GPU 通常不会带来显著加速,反而往往比直接传输更慢。这是合乎逻辑的,因为我们实际上是在要求 Python 执行一个 CUDA 在将数据从主机复制到设备之前无论如何都会执行的操作。
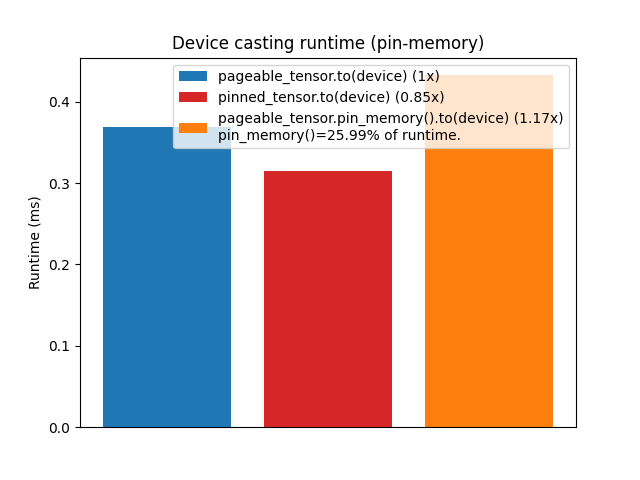
设备转换运行时间(pin-memory)
注:PyTorch 中
pin_memory的实现依赖于通过cudaHostAlloc在锁页内存中创建一个全新的存储,这在某些极端情况下可能比cudaMemcpy分块移动数据更快。这里的观察也可能因硬件、张量大小或可用内存等因素而异。
non_blocking=True¶
如前所述,许多 PyTorch 操作都可以通过 non_blocking 参数相对于主机异步执行。
为了更准确地评估使用 non_blocking 的收益,我们设计了稍微复杂一些的实验,比较在使用与不使用 non_blocking 时一次发送多个张量到 GPU 的速度:
# 简单循环,将所有张量复制到 cuda
def copy_to_device(*tensors):
result = []
for tensor in tensors:
result.append(tensor.to("cuda:0"))
return result
# 异步复制所有张量到 cuda
def copy_to_device_nonblocking(*tensors):
result = []
for tensor in tensors:
result.append(tensor.to("cuda:0", non_blocking=True))
# 需要同步
torch.cuda.synchronize()
return result
# 创建一组张量
tensors = [torch.randn(1000) for _ in range(1000)]# 简单循环,将所有张量复制到 cuda
def copy_to_device(*tensors):
result = []
for tensor in tensors:
result.append(tensor.to("cuda:0"))
return result
# 异步复制所有张量到 cuda
def copy_to_device_nonblocking(*tensors):
result = []
for tensor in tensors:
result.append(tensor.to("cuda:0", non_blocking=True))
# 需要同步
torch.cuda.synchronize()
return result
# 创建一组张量
tensors = [torch.randn(1000) for _ in range(1000)]实验结果表明,使用 non_blocking=True 明显更快,因为主机端可以一次性启动所有传输,只需在最后同步一次。收益程度取决于张量数量、大小以及硬件。
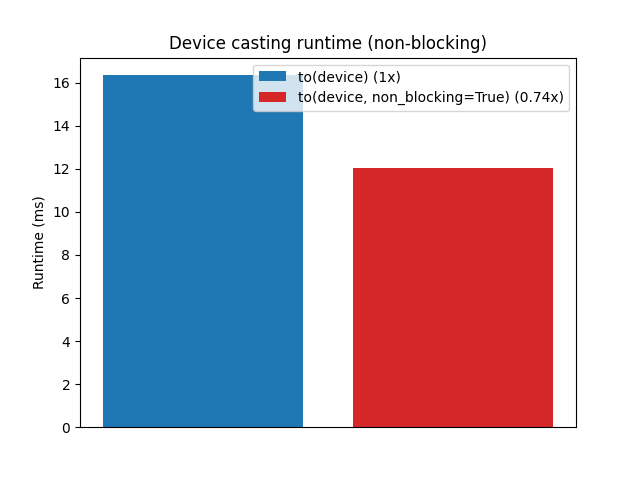
设备转换运行时间(非阻塞)
有趣的是,阻塞式 to("cuda") 实际上执行的也是同一个异步传输操作(cudaMemcpyAsync),只是每次复制后立即同步。
综合使用¶
现在我们知道,对于已经在锁页内存中的张量,数据传输到 GPU 会比从可分页内存更快;也知道异步传输比同步传输快。接下来我们基于这两种方法的组合进行基准测试。
首先定义一些新的函数,在每个张量上调用 pin_memory() 与 to(device):
def pin_copy_to_device(*tensors):
result = []
for tensor in tensors:
result.append(tensor.pin_memory().to("cuda:0"))
return result
def pin_copy_to_device_nonblocking(*tensors):
result = []
for tensor in tensors:
result.append(tensor.pin_memory().to("cuda:0", non_blocking=True))
torch.cuda.synchronize()
return resultdef pin_copy_to_device(*tensors):
result = []
for tensor in tensors:
result.append(tensor.pin_memory().to("cuda:0"))
return result
def pin_copy_to_device_nonblocking(*tensors):
result = []
for tensor in tensors:
result.append(tensor.pin_memory().to("cuda:0", non_blocking=True))
torch.cuda.synchronize()
return result对于一批较大的大张量来说,使用 pin_memory 的优势更加明显。下图展示了不同策略(仅从可分页内存传输、仅从锁页内存传输、先锁页再传输)在阻塞与非阻塞情况下的运行时间比较:
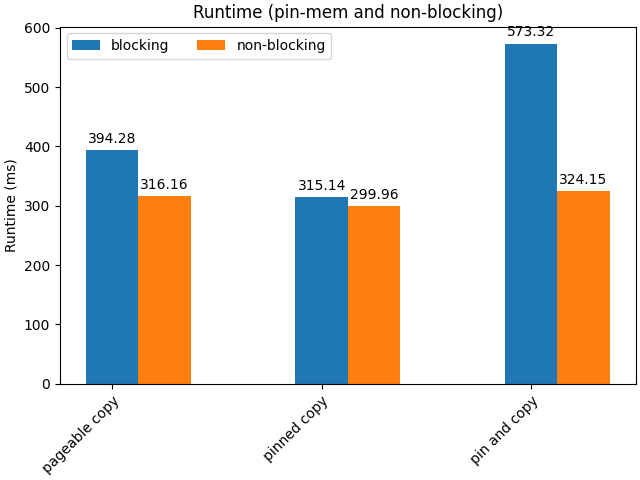
运行时间(pin-mem 与 non-blocking)
可以看到,锁页内存配合非阻塞传输通常最快;但如果在 Python 主线程中手动调用 pin_memory() 会引入额外的阻塞,因此会抵消使用 non_blocking=True 的优势。
其他传输方向(GPU → CPU、CPU → MPS)¶
前文假设从 CPU 到 GPU 的异步复制是安全的。这在源张量位于可分页内存时通常成立,因为 CUDA 会自动同步以确保读取的数据有效。
然而,在其他情况下不能做同样的假设:当张量位于锁页内存且在调用主机到设备传输后修改了原始副本时,GPU 上收到的数据可能会被破坏。同样,从 GPU 到 CPU,或者从 CPU/GPU 到 MPS 等非 CUDA 设备进行传输时,没有保证在不显式同步的情况下数据是完整的。
下面的例子演示,如果在传输后立即修改原始锁页张量,在 GPU 上读到的数据会被破坏:
DELAY = 100000000
i = -1
for i in range(100):
# 创建锁页张量
cpu_tensor = torch.ones(1024, 1024, pin_memory=True)
torch.cuda.synchronize()
# 发送张量到 CUDA
cuda_tensor = cpu_tensor.to("cuda", non_blocking=True)
torch.cuda._sleep(DELAY)
# 修改原始张量
cpu_tensor.zero_()
assert (cuda_tensor == 1).all()DELAY = 100000000
i = -1
for i in range(100):
# 创建锁页张量
cpu_tensor = torch.ones(1024, 1024, pin_memory=True)
torch.cuda.synchronize()
# 发送张量到 CUDA
cuda_tensor = cpu_tensor.to("cuda", non_blocking=True)
torch.cuda._sleep(DELAY)
# 修改原始张量
cpu_tensor.zero_()
assert (cuda_tensor == 1).all()使用可分页内存总是安全的,因为 CUDA 会在后台复制数据。异步从 GPU 转到 CPU 则无法保证正确,除非在访问数据之前显式调用 torch.cuda.synchronize()。总之,异步复制在目标是 CUDA 设备且源在可分页内存时安全,但对于其他方向,必须在访问数据前同步。
实践建议¶
根据前面的观察,我们可以总结一些建议:
- 一般来说,使用
non_blocking=True可以获得更好的吞吐量,无论原始张量是否处于锁页内存。 - 如果张量已在锁页内存中,传输速度会更快;但从 Python 主线程手动将张量锁页是一个阻塞操作,会抵消大部分
non_blocking=True的好处(因为 CUDA 在传输前无论如何都会进行锁页)。 - 因此,除非确定锁页内存带来显著收益,否则不必主动调用
pin_memory()。
那么 pin_memory() 有什么用呢?接下来讨论的附加考虑会进一步说明该方法如何加速数据传输。
附加考虑¶
PyTorch 提供了一个 DataLoader 类,其构造函数接受 pin_memory 参数。根据我们之前关于 pin_memory 的讨论,可能会疑惑:如果内存锁页本身是阻塞的,DataLoader 如何加速数据传输?
关键在于 DataLoader 使用单独的线程在后台将数据从可分页内存复制到锁页内存,从而避免阻塞主线程。
为了演示这一点,教程使用了 tensordict 库中的 TensorDict。调用 TensorDict.to() 默认会异步将数据发送到设备,随后再调用一次 torch.device.synchronize()。此外,TensorDict.to() 包含 non_blocking_pin 选项,该选项启动多线程执行 pin_memory(),然后再执行 to(device)。这一策略可以进一步加速数据传输。
例如,将许多大型张量从 CPU 传输到 GPU 的情形适合使用多线程 pin_memory():
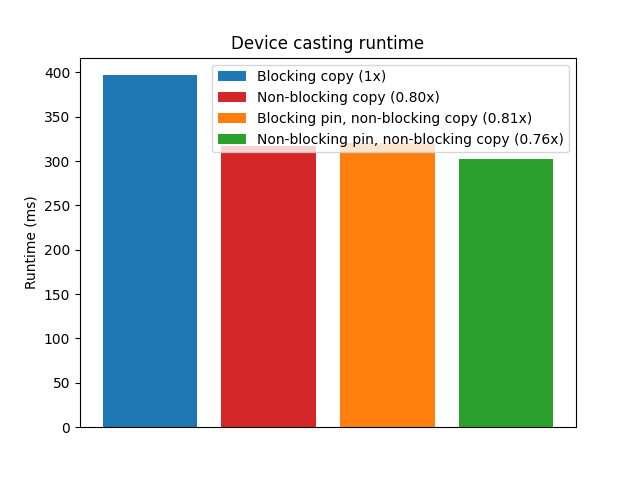
设备转换运行时间
在示例中,如果张量较小或数量较少,多线程带来的额外开销可能超过收益。类似地,预先在锁页内存中创建永久缓冲区并不能消除将数据复制到锁页内存所造成的瓶颈。
在实践中,没有一种通用方案适用于所有情况。使用多线程 pin_memory 与 non_blocking 的有效性取决于系统环境、操作系统、硬件及任务性质。以下是加快 CPU 与 GPU 之间数据传输或比较吞吐量时应检查的一些因素:
- 可用 CPU 核心数量:系统有多少可用 CPU 核心?是否与其他用户或进程共享?
- 核心利用率:CPU 核心是否被其他进程大量占用?应用程序是否在数据传输的同时执行其他密集运算?
- 内存利用率:当前可分页和锁页内存的使用量如何?是否有足够的剩余内存来分配额外的锁页内存而不影响系统性能?例如
pin_memory会消耗 RAM 并可能影响其他任务。 - CUDA 设备能力:GPU 是否支持多个 DMA 引擎以进行并发数据传输?所用 CUDA 设备有哪些能力与限制?
- 要发送的张量数量:一次操作中要传输多少个张量?
- 要发送的张量大小:传输的是几个大张量还是很多小张量?不同情形可能需要不同的传输方案。
- 系统架构:系统架构(例如总线速率、网络延迟)如何影响数据传输速度?
此外,大量或大尺寸张量驻留在锁页内存中会占用大量 RAM,减少用于其他重要操作(如分页)的可用内存,从而可能影响算法整体性能。
结论¶
在本教程中,我们探讨了在将张量从主机发送到设备时影响传输速度和内存管理的几个关键因素。我们了解到,使用 non_blocking=True 通常能加快数据传输,而在合适条件下使用 pin_memory() 也可以提高性能。不过,这些技术需要仔细设计和测试才能发挥作用。
请记住,对代码进行性能分析、监控内存使用情况对于优化资源使用和获得最佳性能至关重要。