📝 转载 / 引用来源: 作者 GiantPandaLLM · 查看原文
0x0. 前言¶
最近在优化 SGLang 对 Wan2.2 视频生成模型的支持时,发现了一个性能问题:在使用双 Transformer 架构时,第 1 步和第 19 步的推理速度比正常步骤慢了约 7 倍。经过深入分析,通过实现零开销的逐层权重卸载 (Layerwise Weight Offload) 技术,最终将整体推理速度提升了 60%(从 149.69 秒降至 94.22 秒)。需要说明的是这个技术的核心代码实现部分从 Skywork AI Infra 的视频模型优化中修改而来(链接)。
这个优化不仅带来了性能提升,也突破了 Wan2.2 模型的显存墙。比如我们现在可以在 24GB 显存的 4090 上运行 wan2.2 而不会 OOM,具有还不错的实用意义。此外这个优化也可以方便的扩展到其他模型上,比如 HunyuanVideo。本文将详细介绍问题的发现、分析和解决过程。
相关 PR:https://github.com/sgl-project/sglang/pull/15511
测试环境:8 卡 H100
0x1. 问题发现:为什么 Wan2.2 这么慢?¶
0x1.1 性能瓶颈定位¶
在对 Wan2.2 模型进行完整的 profiling 之后,发现了一个奇怪的现象:
- 第 1 步和第 19 步:耗时约 36 秒和 31 秒,异常缓慢
- 中间步骤(第 2-18 步):耗时约 3.2 秒,性能正常,完全达到了从 cp4 到 cp8 的 2 倍加速预期
- 其他步骤(第 20-27 步):耗时约 3.2 秒,性能正常
第 1 步和第 19 步的耗时相当于 7 个正常步骤,这显然是不可接受的。
main 分支的数据:
sglang generate --model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers --text-encoder-cpu-offload --pin-cpu-memory --num-gpus 8 --ulysses-degree 8 --attention-backend sage_attn --enable-torch-compile --prompt "A cat walks on the grass, realistic" --num-frames 81 --height 720 --width 1280 --num-inference-steps 27 --guidance-scale 3.5 --guidance-scale-2 4.0 --perf-dump-path /home/lmsys/bbuf/dump/wan_step_profile_cp8_main.json
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [02:28<00:00, 5.52s/it]
[12-19 08:37:22] [DenoisingStage] average time per step: 5.5156 seconds
[12-19 08:37:23] [DenoisingStage] finished in 149.6943 seconds
"denoise_steps_ms": [
35999.06893167645,
3261.483933776617,
3270.5406425520778,
3267.8588768467307,
3260.3964526206255,
3263.016454875469,
3268.026988953352,
3264.5184732973576,
3264.636719599366,
3267.1875776723027,
3268.562350422144,
3268.1023878976703,
3266.7769035324454,
3268.044295720756,
3264.268895611167,
3271.0087513551116,
3267.674465663731,
3266.1060262471437,
31282.590138725936,
3263.5639663785696,
3262.301029637456,
3262.3210102319717,
3261.833382770419,
3264.719443395734,
3265.314467251301,
3267.530156299472,
3261.9533529505134
],sglang generate --model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers --text-encoder-cpu-offload --pin-cpu-memory --num-gpus 8 --ulysses-degree 8 --attention-backend sage_attn --enable-torch-compile --prompt "A cat walks on the grass, realistic" --num-frames 81 --height 720 --width 1280 --num-inference-steps 27 --guidance-scale 3.5 --guidance-scale-2 4.0 --perf-dump-path /home/lmsys/bbuf/dump/wan_step_profile_cp8_main.json
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [02:28<00:00, 5.52s/it]
[12-19 08:37:22] [DenoisingStage] average time per step: 5.5156 seconds
[12-19 08:37:23] [DenoisingStage] finished in 149.6943 seconds
"denoise_steps_ms": [
35999.06893167645,
3261.483933776617,
3270.5406425520778,
3267.8588768467307,
3260.3964526206255,
3263.016454875469,
3268.026988953352,
3264.5184732973576,
3264.636719599366,
3267.1875776723027,
3268.562350422144,
3268.1023878976703,
3266.7769035324454,
3268.044295720756,
3264.268895611167,
3271.0087513551116,
3267.674465663731,
3266.1060262471437,
31282.590138725936,
3263.5639663785696,
3262.301029637456,
3262.3210102319717,
3261.833382770419,
3264.719443395734,
3265.314467251301,
3267.530156299472,
3261.9533529505134
],经过本文介绍的优化之后的数据:
sglang generate --model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers --text-encoder-cpu-offload --pin-cpu-memory --num-gpus 8 --ulysses-degree 8 --attention-backend sage_attn --enable-torch-compile --prompt "A cat walks on the grass, realistic" --num-frames 81 --height 720 --width 1280 --num-inference-steps 27 --guidance-scale 3.5 --guidance-scale-2 4.0 --dit-layerwise-offload true --perf-dump-path /home/lmsys/bbuf/dump/wan_step_profile_cp8_async_offload.json
100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [01:33<00:00, 3.46s/it]
[12-20 02:59:10] [DenoisingStage] average time per step: 3.4553 seconds
[12-20 02:59:10] [DenoisingStage] finished in 94.2283 seconds
"denoise_steps_ms": [
7717.6975486800075,
3275.042257271707,
3280.2467988803983,
3282.276245765388,
3292.9044039919972,
3286.5121429786086,
3273.5616639256477,
3271.6003246605396,
3275.5934856832027,
3291.9061705470085,
3293.934356421232,
3289.3909830600023,
3298.0582248419523,
3300.408118404448,
3305.0247132778168,
3299.3013756349683,
3302.0150866359472,
3299.040620215237,
3291.0401169210672,
3296.6199973598123,
3290.26335850358,
3302.190547809005,
3295.942653901875,
3297.3329443484545,
3297.713255509734,
3295.0284238904715,
3290.1963284239173
],sglang generate --model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers --text-encoder-cpu-offload --pin-cpu-memory --num-gpus 8 --ulysses-degree 8 --attention-backend sage_attn --enable-torch-compile --prompt "A cat walks on the grass, realistic" --num-frames 81 --height 720 --width 1280 --num-inference-steps 27 --guidance-scale 3.5 --guidance-scale-2 4.0 --dit-layerwise-offload true --perf-dump-path /home/lmsys/bbuf/dump/wan_step_profile_cp8_async_offload.json
100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 27/27 [01:33<00:00, 3.46s/it]
[12-20 02:59:10] [DenoisingStage] average time per step: 3.4553 seconds
[12-20 02:59:10] [DenoisingStage] finished in 94.2283 seconds
"denoise_steps_ms": [
7717.6975486800075,
3275.042257271707,
3280.2467988803983,
3282.276245765388,
3292.9044039919972,
3286.5121429786086,
3273.5616639256477,
3271.6003246605396,
3275.5934856832027,
3291.9061705470085,
3293.934356421232,
3289.3909830600023,
3298.0582248419523,
3300.408118404448,
3305.0247132778168,
3299.3013756349683,
3302.0150866359472,
3299.040620215237,
3291.0401169210672,
3296.6199973598123,
3290.26335850358,
3302.190547809005,
3295.942653901875,
3297.3329443484545,
3297.713255509734,
3295.0284238904715,
3290.1963284239173
],0x1.2 根因分析¶
通过深入分析代码和 profiling 结果,找到了问题的根本原因:
- Wan2.2 使用双 Transformer 架构:模型包含
transformer和transformer_2两个大型 Transformer 模块 - 启用了 dit_cpu_offload:为了节省 GPU 显存,模型权重在加载后被放置在 CPU 上
- 第 1 步的开销:在第一次推理时,需要将
transformer和transformer_2的权重从 CPU 拷贝到 GPU,导致第 1 步非常慢,并且第一步还有 torch compile、nccl 初始化等开销 - 第 19 步的开销:在第 19 步发生了 dual-stream 切换,需要将两个 Transformer 的权重卸载回 CPU,交换它们,然后再拷贝回 GPU
这种全模型级别的权重搬运导致了巨大的性能损失。
0x2. 解决方案:零开销逐层权重卸载¶
0x2.1 核心思想¶
传统的 dit_cpu_offload 是将整个模型的权重一次性在 CPU 和 GPU 之间搬运,这会导致:
- 大量的数据传输时间
- GPU 计算和数据传输无法 overlap
- 在 dual-stream 切换时需要重新搬运所有权重
零开销逐层权重卸载的核心思想是:
- 逐层管理:只在需要时将某一层的权重从 CPU 加载到 GPU
- 异步预取:使用独立的 CUDA Stream 提前预取下一层的权重
- 计算与传输 overlap:当前层在计算时,下一层的权重已经在异步加载
- 及时释放:当前层计算完成后,立即释放其 GPU 显存
- Pin Memory 优化:将 CPU 上的权重 pin 到物理内存,避免页面交换,这对于实现零开销至关重要
这样可以实现零额外开销:数据传输完全被计算隐藏,不会增加总体推理时间。
0x2.2 实现细节¶
LayerwiseOffloadManager 核心类¶
实现了一个轻量级的逐层 CPU 卸载管理器,核心功能包括:
class LayerwiseOffloadManager:
"""A lightweight layerwise CPU offload manager.
This utility offloads per-layer parameters/buffers from GPU to CPU, and
supports async H2D prefetch using a dedicated CUDA stream.
"""
def __init__(
self,
model: torch.nn.Module,
*,
module_list_attr: str, # 例如 "blocks"
num_layers: int,
enabled: bool,
pin_cpu_memory: bool = True,
auto_initialize: bool = False,
):
# 创建独立的CUDA Stream用于异步拷贝
self.copy_stream = torch.cuda.Stream() if self.enabled else None
# 存储CPU上的权重
self._cpu_weights: Dict[int, Dict[str, torch.Tensor]] = {}
# 跟踪哪些层在GPU上
self._gpu_layers: Dict[int, Set[str]] = {}class LayerwiseOffloadManager:
"""A lightweight layerwise CPU offload manager.
This utility offloads per-layer parameters/buffers from GPU to CPU, and
supports async H2D prefetch using a dedicated CUDA stream.
"""
def __init__(
self,
model: torch.nn.Module,
*,
module_list_attr: str, # 例如 "blocks"
num_layers: int,
enabled: bool,
pin_cpu_memory: bool = True,
auto_initialize: bool = False,
):
# 创建独立的CUDA Stream用于异步拷贝
self.copy_stream = torch.cuda.Stream() if self.enabled else None
# 存储CPU上的权重
self._cpu_weights: Dict[int, Dict[str, torch.Tensor]] = {}
# 跟踪哪些层在GPU上
self._gpu_layers: Dict[int, Set[str]] = {}初始化:将所有层权重卸载到 CPU¶
def initialize(self) -> None:
if not self.enabled:
return
# 遍历所有参数和buffer
for name, param in self._named_parameters.items():
layer_idx = self._match_layer_idx(name)
if layer_idx is None or layer_idx >= self.num_layers:
continue
# 卸载到CPU并pin memory
self._offload_tensor(name, param, layer_idx)
# 预取第0层
self.prefetch_layer(0, non_blocking=False)def initialize(self) -> None:
if not self.enabled:
return
# 遍历所有参数和buffer
for name, param in self._named_parameters.items():
layer_idx = self._match_layer_idx(name)
if layer_idx is None or layer_idx >= self.num_layers:
continue
# 卸载到CPU并pin memory
self._offload_tensor(name, param, layer_idx)
# 预取第0层
self.prefetch_layer(0, non_blocking=False)这里有个关键点是 _offload_tensor 方法中会将 CPU 上的 tensor 进行 pin memory 操作:
cpu_weight = tensor.detach().to("cpu")
if self.pin_cpu_memory:
cpu_weight = cpu_weight.pin_memory() # 锁定物理内存cpu_weight = tensor.detach().to("cpu")
if self.pin_cpu_memory:
cpu_weight = cpu_weight.pin_memory() # 锁定物理内存Pin memory 的作用是将内存页锁定在物理内存中,避免被操作系统 swap 到磁盘。这样做有两个好处:
- 异步拷贝(non_blocking=True)只对 pinned memory 有效,否则会退化为同步拷贝
- DMA(Direct Memory Access)可以直接访问 pinned memory,传输速度更快
在 Wan2.2 这种大模型场景下,如果不使用 pin memory,异步拷贝会失效,计算和传输就无法 overlap,也就谈不上零开销了。
异步预取:提前加载下一层¶
def prefetch_layer(self, layer_idx: int, non_blocking: bool = True) -> None:
if not self.enabled:
return
# 等待主stream完成当前计算
self.copy_stream.wait_stream(torch.cuda.current_stream())
# 在独立stream中异步拷贝权重
for name, cpu_weight in self._cpu_weights[layer_idx].items():
gpu_weight = torch.empty(
cpu_weight.shape,
dtype=self._cpu_dtypes[layer_idx][name],
device=self.device,
)
with torch.cuda.stream(self.copy_stream):
gpu_weight.copy_(cpu_weight, non_blocking=non_blocking)
target.data = gpu_weightdef prefetch_layer(self, layer_idx: int, non_blocking: bool = True) -> None:
if not self.enabled:
return
# 等待主stream完成当前计算
self.copy_stream.wait_stream(torch.cuda.current_stream())
# 在独立stream中异步拷贝权重
for name, cpu_weight in self._cpu_weights[layer_idx].items():
gpu_weight = torch.empty(
cpu_weight.shape,
dtype=self._cpu_dtypes[layer_idx][name],
device=self.device,
)
with torch.cuda.stream(self.copy_stream):
gpu_weight.copy_(cpu_weight, non_blocking=non_blocking)
target.data = gpu_weight层级作用域:优雅的使用方式¶
@contextmanager
def layer_scope(
self,
*,
prefetch_layer_idx: int | None,
release_layer_idx: int | None,
non_blocking: bool = True,
):
"""在进入时预取下一层,退出时等待拷贝完成并释放当前层"""
if self.enabled and prefetch_layer_idx is not None:
self.prefetch_layer(prefetch_layer_idx, non_blocking=non_blocking)
try:
yield
finally:
if self.enabled and self.copy_stream is not None:
# 等待异步拷贝完成
torch.cuda.current_stream().wait_stream(self.copy_stream)
if self.enabled and release_layer_idx is not None:
self.release_layer(release_layer_idx)@contextmanager
def layer_scope(
self,
*,
prefetch_layer_idx: int | None,
release_layer_idx: int | None,
non_blocking: bool = True,
):
"""在进入时预取下一层,退出时等待拷贝完成并释放当前层"""
if self.enabled and prefetch_layer_idx is not None:
self.prefetch_layer(prefetch_layer_idx, non_blocking=non_blocking)
try:
yield
finally:
if self.enabled and self.copy_stream is not None:
# 等待异步拷贝完成
torch.cuda.current_stream().wait_stream(self.copy_stream)
if self.enabled and release_layer_idx is not None:
self.release_layer(release_layer_idx)在模型 forward 中使用¶
在 Wan2.2 的 Transformer forward 中集成:
offload_mgr = getattr(self, "_layerwise_offload_manager", None)
if offload_mgr is not None and getattr(offload_mgr, "enabled", False):
for i, block in enumerate(self.blocks):
with offload_mgr.layer_scope(
prefetch_layer_idx=i + 1, # 预取下一层
release_layer_idx=i, # 释放当前层
non_blocking=True,
):
hidden_states = block(
hidden_states,
encoder_hidden_states,
timestep_proj,
freqs_cis,
)offload_mgr = getattr(self, "_layerwise_offload_manager", None)
if offload_mgr is not None and getattr(offload_mgr, "enabled", False):
for i, block in enumerate(self.blocks):
with offload_mgr.layer_scope(
prefetch_layer_idx=i + 1, # 预取下一层
release_layer_idx=i, # 释放当前层
non_blocking=True,
):
hidden_states = block(
hidden_states,
encoder_hidden_states,
timestep_proj,
freqs_cis,
)通过 layer_scope 上下文管理器:
- 在执行第 i 层时,第 i+1 层的权重已经在异步加载
- 第 i 层计算完成后,立即释放其显存
- 数据传输和计算完全 overlap,实现零开销
0x2.3 使用方式¶
在启动 SGLang 服务时,添加 --dit-layerwise-offload true 参数。下面是在 8 卡 H100 上的测试命令:
sglang generate \
--model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers \
--text-encoder-cpu-offload \
--pin-cpu-memory \
--num-gpus 8 \
--ulysses-degree 8 \
--attention-backend sage_attn \
--enable-torch-compile \
--dit-layerwise-offload true \
--prompt "A cat walks on the grass, realistic" \
--num-frames 81 \
--height 720 \
--width 1280 \
--num-inference-steps 27 \
--guidance-scale 3.5 \
--guidance-scale-2 4.0sglang generate \
--model-path Wan-AI/Wan2.2-T2V-A14B-Diffusers \
--text-encoder-cpu-offload \
--pin-cpu-memory \
--num-gpus 8 \
--ulysses-degree 8 \
--attention-backend sage_attn \
--enable-torch-compile \
--dit-layerwise-offload true \
--prompt "A cat walks on the grass, realistic" \
--num-frames 81 \
--height 720 \
--width 1280 \
--num-inference-steps 27 \
--guidance-scale 3.5 \
--guidance-scale-2 4.0注意:
--dit-layerwise-offload不能与dit_cpu_offload、use_fsdp_inference或cache-dit同时使用
0x3. 性能提升¶
0x3.1 主分支 vs PR 分支¶
主分支(使用 dit_cpu_offload):
[12-19 08:37:22] [DenoisingStage] average time per step: 5.5156 seconds
[12-19 08:37:23] [DenoisingStage] finished in 149.6943 seconds
"denoise_steps_ms": [
35999.07, // 第1步: 36秒!
3261.48, 3270.54, 3267.86, 3260.40, 3263.02, 3268.03, 3264.52,
3264.64, 3267.19, 3268.56, 3268.10, 3266.78, 3268.04, 3264.27,
3271.01, 3267.67, 3266.11,
31282.59, // 第19步: 31秒!
3263.56, 3262.30, 3262.32, 3261.83, 3264.72, 3265.31, 3267.53, 3261.95
][12-19 08:37:22] [DenoisingStage] average time per step: 5.5156 seconds
[12-19 08:37:23] [DenoisingStage] finished in 149.6943 seconds
"denoise_steps_ms": [
35999.07, // 第1步: 36秒!
3261.48, 3270.54, 3267.86, 3260.40, 3263.02, 3268.03, 3264.52,
3264.64, 3267.19, 3268.56, 3268.10, 3266.78, 3268.04, 3264.27,
3271.01, 3267.67, 3266.11,
31282.59, // 第19步: 31秒!
3263.56, 3262.30, 3262.32, 3261.83, 3264.72, 3265.31, 3267.53, 3261.95
]PR 分支(使用 dit_layerwise_offload):
[12-20 02:59:10] [DenoisingStage] average time per step: 3.4553 seconds
[12-20 02:59:10] [DenoisingStage] finished in 94.2283 seconds
"denoise_steps_ms": [
7717.70, // 第1步: 7.7秒,提升78%!
3275.04, 3280.25, 3282.28, 3292.90, 3286.51, 3273.56, 3271.60,
3275.59, 3291.91, 3293.93, 3289.39, 3298.06, 3300.41, 3305.02,
3299.30, 3302.02, 3299.04,
3291.04, // 第19步: 3.3秒,提升89%!
3296.62, 3290.26, 3302.19, 3295.94, 3297.33, 3297.71, 3295.03, 3290.20
][12-20 02:59:10] [DenoisingStage] average time per step: 3.4553 seconds
[12-20 02:59:10] [DenoisingStage] finished in 94.2283 seconds
"denoise_steps_ms": [
7717.70, // 第1步: 7.7秒,提升78%!
3275.04, 3280.25, 3282.28, 3292.90, 3286.51, 3273.56, 3271.60,
3275.59, 3291.91, 3293.93, 3289.39, 3298.06, 3300.41, 3305.02,
3299.30, 3302.02, 3299.04,
3291.04, // 第19步: 3.3秒,提升89%!
3296.62, 3290.26, 3302.19, 3295.94, 3297.33, 3297.71, 3295.03, 3290.20
]0x3.2 性能分析¶
从数据上看:
- 总体加速:149.69 秒 → 94.22 秒,提升 58%
- 第 1 步加速:36 秒 → 7.7 秒,提升 78%
- 第 19 步加速:31 秒 → 3.3 秒,提升 89%
- 中间步骤:保持在 3.2-3.3 秒,性能稳定
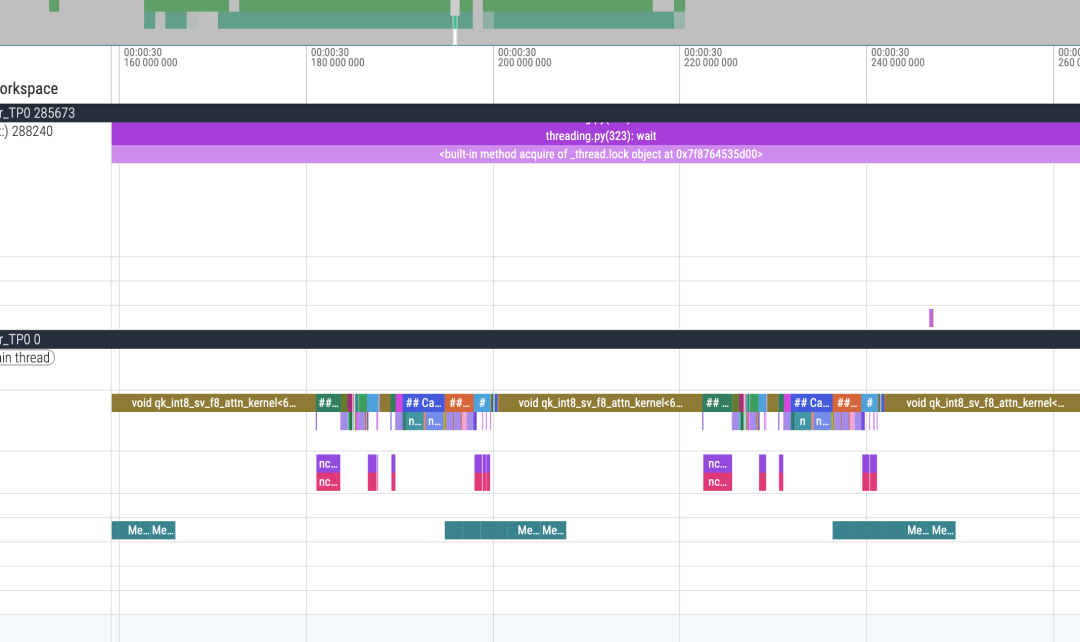
下面是 torch profiler 的 trace 截图,可以清楚地看到 memcpy 和 compute 完全 overlap,没有额外开销:
从 timeline 可以看到,H2D 的 memcpy 操作和 kernel 执行是完全重叠的,这就是零开销的体现。异步拷贝在独立的 stream 中进行,不会阻塞主 stream 的计算。
0x4. 额外优化:All2All 预热¶
即使解决了权重卸载的问题,我发现无论是否启用 torch compile,第 1 步的性能仍然比后续步骤慢约 7 倍。通过完整的 profiling 发现,这是因为 NCCL All2All 操作的初始化开销。
这个初始化开销不应该在 denoise 阶段,而应该提前处理。因此实现了专门针对 All2All 操作的预热逻辑。预热之后,不启用 compile 时第 1 步的时间几乎与后续步骤相同,启用 compile 时第 1 步的时间仅为后续步骤的约 2 倍(而不是 7 倍)。NCCL All2All 的初始化开销被提前消除,denoise 阶段的第 1 步不再有明显的延迟。
0x5. 总结¶
这个优化方案的关键技术点包括:逐层权重管理只在需要时加载特定层的权重,避免全模型搬运;使用独立 CUDA Stream 实现异步 H2D 传输,让当前层计算时下一层权重已在加载;使用 pinned memory 锁定物理内存,这是实现异步拷贝和零开销的前提条件;每层计算完成后立即释放 GPU 显存。
实现的亮点在于数据传输完全被计算隐藏,通过 layer_scope context manager 提供了简洁的 API,支持任意具有 blocks 属性的 DiT 模型,并且与 cache-dit 等特性互斥避免潜在错误。
这个技术特别适合大型 Diffusion 模型(如 Wan2.2)、显存受限的场景(可以让原本需要 80GB 显存的模型在 24GB 显存的 4090 上运行)、需要在 CPU 和 GPU 之间频繁搬运权重的场景,以及具有多层 Transformer 结构的模型。