引言
在大型语言模型和推理服务逐渐走向实际应用的过程中,推理框架的作用不再只是“能跑起来”,而是要在算力、吞吐、延迟之间找到最佳平衡。SGLang 作为近来备受关注的开源推理框架,不仅在功能上兼顾了交互式推理与批量处理,还在调度(Scheduler)层面做出了不少值得深入探讨的设计。
我最近一直在使用 SGLang 作为自己的大模型推理部署框架,在实际项目中频繁参考、学习它的源码实现,也逐渐对其架构有了更直观的理解。前段时间看到社区里有人解析 SGLang 的 scheduler 模块,如《SGLang Scheduler 技术变迁》,我觉得这是一个很好的关于sglang解析的切入点,于是也想尝试写一篇属于自己的分析。但相比于纯理论介绍,我更倾向于结合代码来讲,通过实际的源码细节去还原 scheduler 的工作流程、批处理策略以及资源调度逻辑,这样能更贴近开发者的阅读习惯,也方便在实际应用中做针对性的优化。
下面是关于sglang中的scheduler的流程图
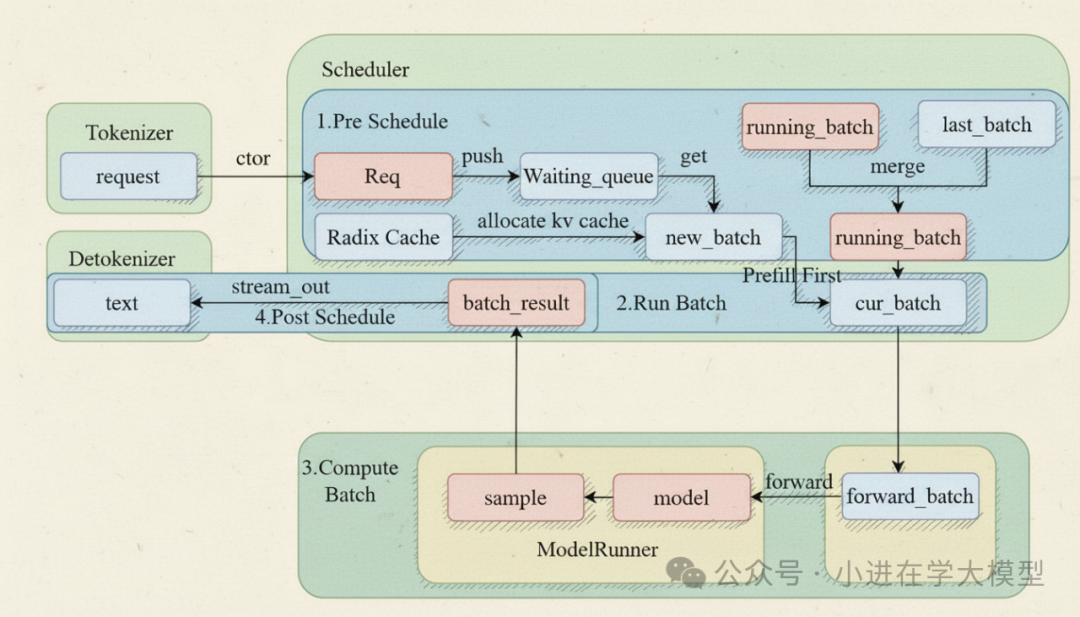
什么是scheduler?¶
这是一个 SGLang 框架中的核心调度器(Scheduler)脚本。SGLang 是一个为大型语言模型(LLM)设计的高性能推理引擎,而这个脚本正是其“大脑”,负责管理和调度所有进入系统的请求,以最高效的方式利用 GPU 资源。
可以把这个 Scheduler想象成一个繁忙机场的空中交通管制塔台。它需要决定哪些“飞机”(请求)可以“起飞”(进入预计算/Prefill 阶段),哪些可以“降落”(生成下一个token/Decode 阶段),同时要确保“跑道”(GPU)始终被高效利用,避免冲突和空闲。
1. 核心功能和目标¶
该脚本的核心功能是实现一个高性能的 LLM 推理调度器,其主要目标是:
-
1.高吞吐量 (High Throughput):通过连续批处理 (Continuous Batching) 等技术,最大化单位时间内模型处理的token数量。
-
2.低延迟 (Low Latency):尽快响应用户请求,特别是对于流式输出的场景。
-
3.高资源利用率 (High Resource Utilization):确保 GPU 尽可能处于满负荷工作状态,减少空闲时间。
-
4.灵活性和可扩展性 (Flexibility & Scalability):支持多种并行策略(TP, PP, DP)、模型架构(MoE)、高级功能(Speculative Decoding, LoRA, Constrained Generation)和部署模式(Disaggregation)。
2. 关键组件和设计模式¶
这个调度器由多个紧密协作的组件构成:
-
Scheduler 类:
-
核心控制器:是整个脚本的中心,初始化所有子组件,并运行主事件循环。
-
状态管理者:维护三个核心请求队列:
-
waiting_queue: 等待处理的新请求。
-
running_batch: 正在进行解码(逐词元生成)的请求批次。
-
grammar_queue: 正在等待语法(如 JSON Schema)解析的请求,解析完成后移入 waiting_queue。
-
请求分发器 (_request_dispatcher): 使用基于类型的分发器 (TypeBasedDispatcher) 设计模式。它根据收到的请求类型(如 TokenizedGenerateReqInput, FlushCacheReqInput 等),调用相应的处理函数。这使得代码结构清晰,易于扩展新类型的请求。
-
TpModelWorker / TpModelWorkerClient:
-
GPU 执行单元:这是实际在 GPU 上执行模型前向传播的“工人”。Scheduler 只是制定计划,TpModelWorker 负责执行。
-
TpModelWorkerClient 是一个特殊版本,用于支持CPU/GPU 计算重叠,允许调度器在 GPU 还在计算上一个批次时,就开始准备下一个批次的数据。
-
KV 缓存管理器 (RadixCache, HiRadixCache, ChunkCache):
-
核心优化:LLM 推理中,Key-Value (KV) Cache 占据了绝大多数 GPU 显存。高效管理 KV 缓存是性能的关键。
-
Radix Cache (前缀树缓存):SGLang 的一个标志性特性。它使用前缀树(Trie)来存储 KV 缓存,可以自动实现请求之间的前缀共享。例如,如果两个用户的提示有相同的前缀,这部分前缀的 KV 缓存只需计算和存储一次,极大地节省了计算量和显存。
-
HiRadixCache (分层基数树缓存):RadixCache 的进阶版,支持将部分不常用的缓存数据转移到 CPU 内存,进一步节省宝贵的 GPU 显存。
-
调度策略 (SchedulePolicy):
-
将调度决策逻辑(如基于 SRTF - 最短剩余时间优先的变种)从主调度器中分离出来,使得更换或调整调度算法更加容易。
-
ScheduleBatch:
-
一个数据类,代表了将要或正在被 GPU 处理的一批请求。它不仅仅是请求的列表,还包含了运行此次批处理所需的所有元数据,如 input_ids, req_pool_idx, seq_lens 等。
3. 核心工作流程:事件循环 (Event Loop)¶
脚本中定义了三种不同的事件循环,以适应不同的并行和优化策略:
-
event_loop_normal() (常规循环):
-
这是一个简单直接的串行循环:接收请求 -> 决定下一批次 -> 运行批次 -> 处理结果 -> 循环。
-
适用于不支持计算重叠或单 GPU 的简单场景。
-
event_loop_overlap() (重叠循环):
-
性能关键:这是默认启用的高性能模式。它实现了一个经典的流水线 (Pipeline) 来重叠 CPU 处理和 GPU 计算。
-
流程:
-
CPU 准备好批次 N 并将其异步地交给 GPU Worker 开始计算。
-
CPU 不等待 GPU 完成,立即开始准备下一批次 N+1。
-
在准备批次 N+1 的同时,GPU 可能完成了批次 N 的计算。
-
CPU 获取批次 N 的结果并进行后处理(如判断请求是否完成、流式返回结果等)。
-
这种方式有效隐藏了 CPU 准备数据、调度决策等造成的延迟,让 GPU 一直有活干。
-
event_loop_pp() (流水线并行循环):
-
专为流水线并行 (Pipeline Parallelism, PP) 设计。模型被切分到多个 GPU 上,形成一个流水线。
-
此循环管理着多个微批次 (micro-batches),确保数据在不同 PP 阶段的 GPU 之间顺畅流动,并正确地处理每个阶段的输入和输出。
4. 关键技术和高级特性分析¶
这个调度器集成了当前 LLM 推理领域的多种前沿技术:
-
连续批处理 (Continuous Batching):
-
体现在 get_next_batch_to_run 方法中。它不会等待一个批次中的所有请求都完成后才开始下一个批次。
-
Prefill-Decode 分离:它将请求处理分为两个阶段:
-
Prefill (预计算):处理用户输入的提示(prompt),计算其 KV 缓存。这通常是计算密集型的。
-
Decode (解码):在已有 KV 缓存的基础上,每步只生成一个新词元。这通常是访存密集型的。
-
调度器会动态地将新的 prefill 请求和正在 decode 的请求组合成一个新的批次,从而填满 GPU 的计算能力,避免了传统批处理 (static batching) 中因请求长度不一导致的 GPU 空闲。
-
分块预计算 (Chunked Prefill):
-
对于非常长的输入提示,一次性进行 prefill 会长时间占用 GPU,阻塞其他短请求。此功能可以将长提示分块处理,穿插执行其他请求的 decode 步骤,提高系统的公平性和响应速度。
-
投机性解码 (Speculative Decoding):
-
通过 draft_worker 和 spec_algorithm 相关代码实现。
-
它使用一个小的、快速的“草稿模型”来一次性生成多个候选词元,然后用大的“目标模型”一次性验证这些词元。如果验证通过,就相当于一次前向传播生成了多个词元,极大地加速了 decode 阶段。
-
计算资源解耦 (Disaggregation):
-
这是一个非常高级的特性,通过 SchedulerDisaggregation…Mixin 类和 disaggregation_mode 实现。
-
它允许将 prefill 计算和 decode 计算部署在不同的 GPU 集群上。因为 prefill 是计算密集型(适合计算卡),而 decode 是访存密集型(适合高带宽显存的卡),这种解耦可以根据工作负载的特性来配置硬件,实现极致的成本效益和性能。
-
约束生成 (Constrained Generation):
-
通过 grammar_backend 支持。它允许用户提供 JSON Schema 或正则表达式等语法约束,确保模型生成的输出严格符合指定格式,这在实际应用中非常有用。
-
动态 LoRA 加载/卸载:
-
load_lora_adapter 和 unload_lora_adapter 方法允许在服务运行时动态加载和卸载 LoRA 适配器,支持多租户或需要动态切换微调模型的场景。
-
在线权重更新:
-
update_weights_from_… 系列方法支持在不中断服务的情况下,更新模型的部分或全部权重,适用于模型持续学习或热修复的场景。
-
强大的监控与调试:
-
watchdog_thread: 一个看门狗线程,如果一次前向传播耗时过长,会认为系统卡死并主动退出,提高了系统的健壮性。
-
profile 方法: 内置了对 torch.profiler 的支持,可以方便地启动和停止性能分析,以诊断性能瓶颈。
-
详细的日志 (log_prefill_stats, log_decode_stats) 和指标收集 (metrics_collector)。
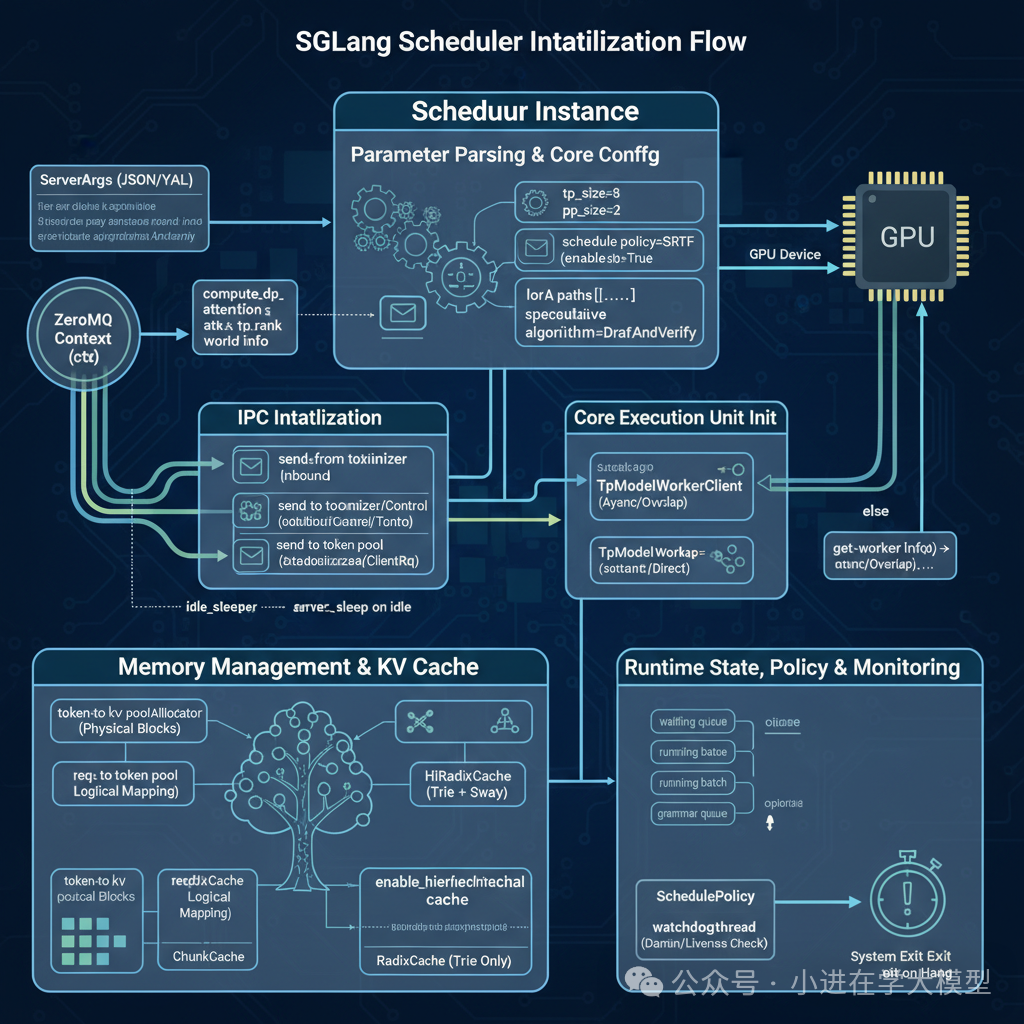
Scheduler初始化¶
下面我们分模块来详细解析它的每一步:
1. 参数解析与核心配置
self.server_args = server_argsself.tp_rank = tp_rankself.pp_rank = pp_rank# 省略一部分初始化代码self.attn_tp_rank, self.attn_tp_size, self.attn_dp_rank = ( compute_dp_attention_world_info(...))self.server_args = server_argsself.tp_rank = tp_rankself.pp_rank = pp_rank# 省略一部分初始化代码self.attn_tp_rank, self.attn_tp_size, self.attn_dp_rank = ( compute_dp_attention_world_info(...))-
目的: 将传入的 ServerArgs 对象中的配置项,持久化为 Scheduler 实例的属性。这使得在整个类的生命周期内,所有方法都能方便地访问这些配置。
-
关键配置:
-
tp_size, pp_size, dp_size: 定义了张量并行、流水线并行和数据并行的规模,这是分布式推理的基础。
-
schedule_policy: 决定了请求的优先级策略(例如,SRTF - 最短剩余时间优先)。
-
enable_overlap: 一个关键的性能开关,决定是否启用CPU处理和GPU计算的重叠。
-
lora_paths, max_loras_per_batch: LoRA 相关配置,支持多租户微调。
-
speculative_algorithm: 投机性解码的算法选择,是另一个重要的性能优化。
-
disaggregation_mode: 资源解耦模式,一个非常高级的部署选项。
-
compute_dp_attention_world_info: 这是一个精妙之处。对于某些特殊的模型或并行策略(如启用DP Attention),Attention层的并行方式可能与模型其他部分的TP(张量并行)方式不同。这个函数计算出专用于Attention模块的并行秩(rank)和大小(size),体现了系统对复杂并行方案的适应性。
2. 进程间通信 (IPC) 初始化
context = zmq.Context(2)# ...if self.pp_rank == 0 and self.attn_tp_rank == 0: self.recv_from_tokenizer = get_zmq_socket(...) self.send_to_tokenizer = get_zmq_socket(...) self.send_to_detokenizer = get_zmq_socket(...) self.recv_from_rpc = get_zmq_socket(...) if self.server_args.sleep_on_idle: self.idle_sleeper = IdleSleeper(...)else: # ... dummy objectscontext = zmq.Context(2)# ...if self.pp_rank == 0 and self.attn_tp_rank == 0: self.recv_from_tokenizer = get_zmq_socket(...) self.send_to_tokenizer = get_zmq_socket(...) self.send_to_detokenizer = get_zmq_socket(...) self.recv_from_rpc = get_zmq_socket(...) if self.server_args.sleep_on_idle: self.idle_sleeper = IdleSleeper(...)else: # ... dummy objects-
目的: 建立 Scheduler 与其他管理进程(如 TokenizerManager, DetokenizerManager, RPC客户端)之间的通信管道。
-
技术选型: 使用 ZeroMQ (ZMQ)。ZMQ是一个高性能的异步消息库,非常适合在底层构建复杂的、低延迟的分布式系统。
-
关键组件:
-
recv_from_tokenizer: 接收来自 TokenizerManager 的已编码请求的“收件箱”。
-
send_to_detokenizer: 将生成的 token ID 发送到 DetokenizerManager 进行解码和流式返回的“发件箱”
-
send_to_tokenizer: 主要作用是 “反馈请求状态” 和 “生命周期管理”。 具体来说,它是scheduler向tokenizermanager发送的控制信号或非文本结果,其主要用途包括:
-
通知请求结束 (Request Finished Signal): 当模型生成了结束符 (EOS) 或者达到了最大长度,调度器需要告诉 Tokenizer Manager 这个请求已经处理完毕。
-
发送非文本的元数据 (Metadata/Stats): 用于发送统计信息,比如本次请求消耗了多少个 Prompt Token,生成了多少个 Output Token,生成速度等。这些信息用于日志记录或计费,不需要经过 Detokenizer 处理。
-
错误处理 (Error Reporting): 如果在推理过程中发生错误(如显存溢出 OOM,输入过长等),调度器可以通过这个通道将错误信息回传给前端,以便前端向用户返回 HTTP 错误响应。
-
中止确认 (Abort Ack): 如果用户断开了连接,Tokenizer Manager 会通知 Scheduler “中止请求”。Scheduler 清理完内部状态后,可能通过此通道发送确认信号。
3. 核心执行单元初始化
if self.enable_overlap: TpWorkerClass = TpModelWorkerClientelse: TpWorkerClass = TpModelWorkerself.tp_worker = TpWorkerClass(...)(self.max_total_num_tokens, ...) = self.tp_worker.get_worker_info()if self.enable_overlap: TpWorkerClass = TpModelWorkerClientelse: TpWorkerClass = TpModelWorkerself.tp_worker = TpWorkerClass(...)(self.max_total_num_tokens, ...) = self.tp_worker.get_worker_info()创建 GPU Worker (tp_worker): 这是整个系统的“引擎”。
-
根据 enable_overlap 配置,选择不同的 Worker 类。TpModelWorkerClient 是支持计算/通信重叠的客户端,它与一个在独立线程中运行的 TpModelWorker 通信,这是实现高性能流水线的关键。
-
tp_worker 封装了模型加载、KV缓存分配、前向传播等所有与GPU直接相关的操作。调度器通过调用 tp_worker 的方法来下达计算指令。
配置同步: tp_worker.get_worker_info() 是一个至关重要的同步点。 Scheduler 不知道模型加载后确切的显存限制(如 max_total_num_tokens),这些信息由 tp_worker 在初始化时根据GPU显存和模型大小计算得出。Scheduler 必须从tp_worker获取这些权威信息,才能正确地进行调度和内存管理。
4.内存管理与 KV 缓存¶
self.init_memory_pool_and_cache()# Inside init_memory_pool_and_cache:self.req_to_token_pool, self.token_to_kv_pool_allocator = self.tp_worker.get_memory_pool()# ...if self.enable_hierarchical_cache: self.tree_cache = HiRadixCache(...)else: self.tree_cache = RadixCache(...)self.init_memory_pool_and_cache()# Inside init_memory_pool_and_cache:self.req_to_token_pool, self.token_to_kv_pool_allocator = self.tp_worker.get_memory_pool()# ...if self.enable_hierarchical_cache: self.tree_cache = HiRadixCache(...)else: self.tree_cache = RadixCache(...)-
目的: 建立SGLang性能的基石——高效的KV缓存管理系统。
-
关键组件:
-
token_to_kv_pool_allocator: 这是物理KV缓存块的分配器。它管理着一块巨大的、预先分配的GPU显存,并将其划分为固定大小的块(page_size)。
-
req_to_token_pool: 这是一个逻辑层,管理请求到物理内存块的映射。
-
tree_cache(核心): 这是SGLang的明星特性。
-
RadixCache: 使用基数树(Trie)来组织KV缓存。当新请求的输入与已缓存的序列有共同前缀时,可以直接复用该前缀的KV缓存,无需重新计算。这极大地提升了处理相似请求或多轮对话的效率。
-
HiRadixCache: RadixCache 的升级版,支持分层缓存。当GPU显存不足时,它可以将部分“冷”数据(不常用的KV缓存)交换到CPU内存,从而支持更长的上下文或更多的并发请求。
-
ChunkCache: 一个相对简单的、非基数树的缓存,用于禁用RadixCache或特定场景。
5.运行时状态、策略与监控
self.waiting_queue: List[Req] = []self.running_batch: ScheduleBatch = ScheduleBatch(...)# ...self.policy = SchedulePolicy(...)# ...t = threading.Thread(target=self.watchdog_thread, daemon=True)t.start()self.waiting_queue: List[Req] = []self.running_batch: ScheduleBatch = ScheduleBatch(...)# ...self.policy = SchedulePolicy(...)# ...t = threading.Thread(target=self.watchdog_thread, daemon=True)t.start()-
目的: 初始化调度器在事件循环中需要的所有动态数据结构和辅助工具。
-
组件:
-
状态队列: waiting_queue (等待处理的请求)、running_batch (正在解码的批次)、grammar_queue (等待语法解析的请求) 是连续批处理算法的核心数据结构。
-
SchedulePolicy: 将调度逻辑(决定下一个运行谁)从主循环中解耦出来。init 函数根据配置创建相应的策略实例。
-
watchdog_thread: 启动一个后台“看门狗”线程。它会周期性地检查主循环是否卡住。如果一次前向传播耗时过长,它会认为系统已死锁,并强制退出进程。这大大提高了生产环境下的系统健壮性。
4. 关键技术和高级特性分析¶
这个调度器集成了当前 LLM 推理领域的多种前沿技术:
-
连续批处理 (Continuous Batching):
-
体现在 get_next_batch_to_run 方法中。它不会等待一个批次中的所有请求都完成后才开始下一个批次。
-
Prefill-Decode 分离:它将请求处理分为两个阶段:
-
Prefill (预填充):处理用户输入的提示(prompt),计算其 KV 缓存。这通常是计算密集型的。
-
Decode (解码):在已有 KV 缓存的基础上,每步只生成一个新词元。这通常是访存密集型的。
-
调度器会动态地将新的 prefill 请求和正在 decode 的请求组合成一个新的批次,从而填满 GPU 的计算能力,避免了传统批处理 (static batching) 中因请求长度不一导致的 GPU 空闲。
-
分块预计算 (Chunked Prefill):
-
对于非常长的输入提示,一次性进行 prefill 会长时间占用 GPU,阻塞其他短请求。此功能可以将长提示分块处理,穿插执行其他请求的 decode 步骤,提高系统的公平性和响应速度。
-
投机性解码 (Speculative Decoding):
-
通过 draft_worker 和 spec_algorithm 相关代码实现。
-
它使用一个小的、快速的“草稿模型”来一次性生成多个候选词元,然后用大的“目标模型”一次性验证这些词元。如果验证通过,就相当于一次前向传播生成了多个词元,极大地加速了 decode 阶段。
-
计算资源解耦 (Disaggregation):
-
这是一个非常高级的特性,通过 SchedulerDisaggregation…Mixin 类和 disaggregation_mode 实现。
-
它允许将 prefill 计算和 decode 计算部署在不同的 GPU 集群上。因为 prefill 是计算密集型(适合计算卡),而 decode 是访存密集型(适合高带宽显存的卡),这种解耦可以根据工作负载的特性来配置硬件,实现极致的成本效益和性能。
-
约束生成 (Constrained Generation):
-
通过 grammar_backend 支持。它允许用户提供 JSON Schema 或正则表达式等语法约束,确保模型生成的输出严格符合指定格式,这在实际应用中非常有用。
-
动态 LoRA 加载/卸载:
-
load_lora_adapter 和 unload_lora_adapter 方法允许在服务运行时动态加载和卸载 LoRA 适配器,支持多租户或需要动态切换微调模型的场景。
-
在线权重更新:
-
update_weights_from_… 系列方法支持在不中断服务的情况下,更新模型的部分或全部权重,适用于模型持续学习或热修复的场景。
-
强大的监控与调试:
-
watchdog_thread: 一个看门狗线程,如果一次前向传播耗时过长,会认为系统卡死并主动退出,提高了系统的健壮性。
-
profile 方法: 内置了对 torch.profiler 的支持,可以方便地启动和停止性能分析,以诊断性能瓶颈。
-
详细的日志 (log_prefill_stats, log_decode_stats) 和指标收集 (metrics_collector)。
事件循环(Event Loop)- 整个系统的“心跳”
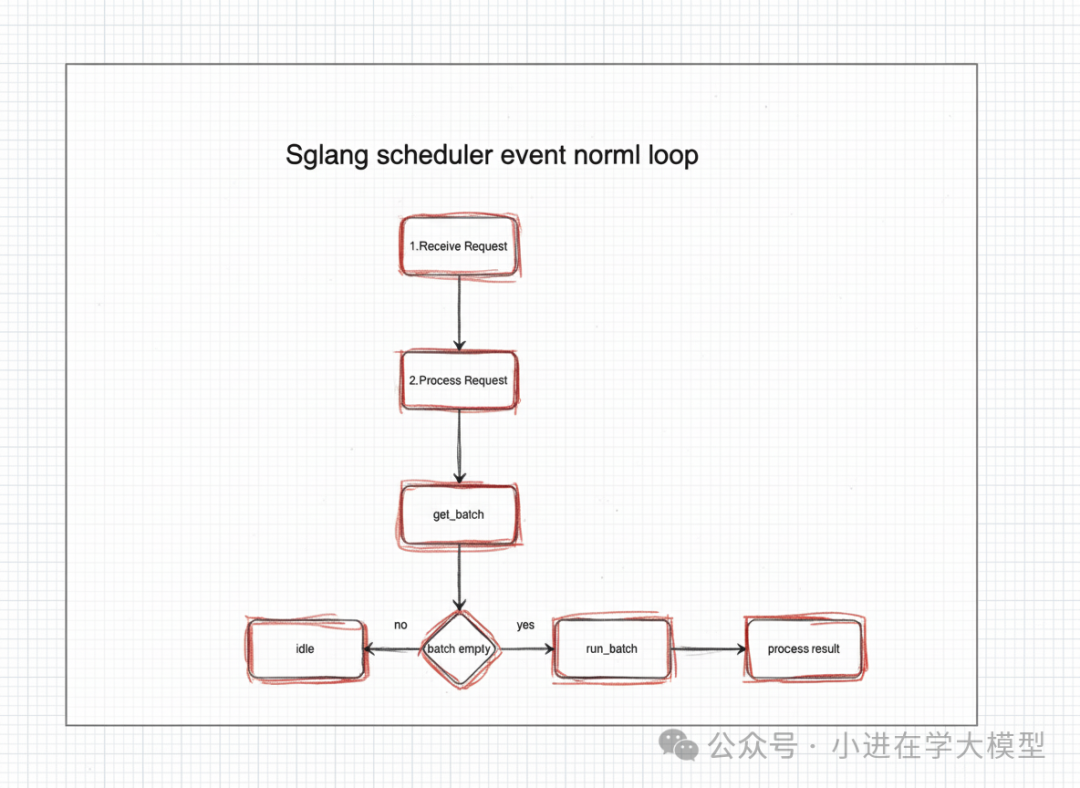
1. 事件循环的基本结构¶
整个调度器运行在一个无限循环中。代码中有三个主要的事件循环,根据配置选择其一:
-
event_loop_normal(): 标准的、非重叠的调度循环。
-
event_loop_overlap(): 优化的调度循环,它会重叠 CPU 处理(调度)和 GPU 计算(模型推理)。
-
event_loop_pp(): 针对流水线并行(Pipeline Parallelism)的特殊循环。
以最简单的 event_loop_normal 为例,它的核心逻辑是:
def event_loop_normal(self): """A normal scheduler loop.""" while True: # 1. 接收请求 recv_reqs = self.recv_requests() # 2. 处理输入请求 self.process_input_requests(recv_reqs) # 3. 决定下一批要运行的请求 batch = self.get_next_batch_to_run() self.cur_batch = batch if batch: # 4. 运行这批请求(模型生成) result = self.run_batch(batch) # 5. 处理生成结果 self.process_batch_result(batch, result) else: # 服务器空闲时的操作 self.maybe_sleep_on_idle() self.last_batch = batchdef event_loop_normal(self): """A normal scheduler loop.""" while True: # 1. 接收请求 recv_reqs = self.recv_requests() # 2. 处理输入请求 self.process_input_requests(recv_reqs) # 3. 决定下一批要运行的请求 batch = self.get_next_batch_to_run() self.cur_batch = batch if batch: # 4. 运行这批请求(模型生成) result = self.run_batch(batch) # 5. 处理生成结果 self.process_batch_result(batch, result) else: # 服务器空闲时的操作 self.maybe_sleep_on_idle() self.last_batch = batch获取请求数据 (recv_requests 和 process_input_requests)
-
recv_requests(self): 这是获取数据的第一个入口。
-
它使用 zmq.PULL 或 zmq.DEALER 从上游进程(通常是 TokenizerManager 或 RPC 接口)接收序列化后的请求对象。
-
在多卡(TP/PP)环境中,这个函数还负责在各个 GPU 进程之间广播请求数据,确保所有进程状态同步。
-
process_input_requests(self, recv_reqs: List):
-
它遍历接收到的所有请求。
-
通过一个名为 _request_dispatcher 的分发器,根据请求的类型(如 TokenizedGenerateReqInput, FlushCacheReqInput 等)调用相应的处理函数
调度决策与批处理 (get_next_batch_to_run)
-
get_next_batch_to_run(self) -> Optional[ScheduleBatch]: 这是调度算法的核心,是调度器的“大脑”。
-
它首先会处理上一批次中已经完成的请求。
-
然后,它会检查 self.waiting_queue 中是否有等待的请求。
-
它使用一个名为 PrefillAdder 的策略来决定可以从等待队列中挑选哪些请求加入到新的批次中。这个决策基于多种因素,如:
-
KV Cache 剩余空间
-
批处理大小限制
-
是否为分块预计算(chunked prefill)
-
前缀缓存(Radix Cache)命中情况
-
如果能形成一个新的批次,它会创建一个 ScheduleBatch 对象并返回。这个对象包含了所有要进行模型推理的请求及其元数据。
模型生成 (run_batch)
-
run_batch(self, batch: ScheduleBatch) -> …: 这是触发模型生成的直接入口。
-
它接收 get_next_batch_to_run 创建的 ScheduleBatch 对象。
-
关键调用: 它不会自己实现模型推理,而是将任务委托给 TpModelWorker(或其客户端 TpModelWorkerClient)。
-
它调用 self.tp_worker.forward_batch_generation(model_worker_batch)。tp_worker 负责管理模型权重、KV Cache,并真正在 GPU 上执行前向传播。
def run_batch( self, batch: ScheduleBatch) -> Union[GenerationBatchResult, EmbeddingBatchResult]: # ... if self.is_generation: # ... # 获取给模型工作进程的批次信息 model_worker_batch = batch.get_model_worker_batch() # 调用工作进程执行模型前向传播 logits_output, next_token_ids, can_run_cuda_graph = ( self.tp_worker.forward_batch_generation(model_worker_batch) ) # ... ret = GenerationBatchResult(...) # ... return retdef run_batch( self, batch: ScheduleBatch) -> Union[GenerationBatchResult, EmbeddingBatchResult]: # ... if self.is_generation: # ... # 获取给模型工作进程的批次信息 model_worker_batch = batch.get_model_worker_batch() # 调用工作进程执行模型前向传播 logits_output, next_token_ids, can_run_cuda_graph = ( self.tp_worker.forward_batch_generation(model_worker_batch) ) # ... ret = GenerationBatchResult(...) # ... return ret结果处理 (process_batch_result)
-
process_batch_result(self, batch, result, …):
-
-它获取 run_batch 返回的结果(包含 logits、新生成的 token ID 等)。
-
-根据结果更新每个 Req 对象的状态(比如将新 token 添加到已生成的序列中)。
-
-处理流式输出(streaming),将新生成的 token 发送回客户端。
-
-判断请求是否完成(例如,达到最大长度或生成了 EOS token)。
-
-释放已完成请求占用的资源。
事件循环的大概流程¶
-
-数据通过 recv_requests 进入系统。
-
-handle_generate_request 将其转化为内部格式并放入等待队列。
-
-get_next_batch_to_run 从队列中挑选请求,形成一个批次。
-
-run_batch 最终调用 self.tp_worker.forward_batch_generation 来执行GPU上的模型生成。
recv_requests 函数分析¶
这是一个在分布式环境中至关重要的函数,它的核心任务是接收来自外部的请求,并在不同的并行工作进程(TP/PP/DP ranks)之间同步这些请求,以确保所有相关进程都有一致的待处理任务视图。
1. 核心功能¶
recv_requests 函数的主要职责可以概括为两点:
-
接收 (Receive): 从 ZMQ 消息队列中接收新的用户请求。这些请求可以是生成任务(来自TokenizerManager),也可以是控制命令(如清空缓存、性能分析等,来自RpcManager)。
-
分发 (Distribute): 将接收到的请求广播或点对点传输给分布式系统中的其他工作进程,以确保状态同步。
2. 设计目标¶
在像 SGLang 这样的分布式推理系统中,模型可能被拆分到多个 GPU 上运行(张量并行、流水线并行等)。当一个新请求到来时,所有参与计算这个请求的 GPU 进程都必须知道这个请求的存在和其详细信息。
recv_requests 的设计目标就是成为这个信息同步的枢纽。它确保了:
-
单一入口点: 只有特定的一个进程(pp_rank=0, attn_tp_rank=0)负责从外部接收请求,避免了多个进程争抢或重复处理。
-
状态一致性: 通过广播机制,所有需要协同工作的进程(例如,一个张量并行组内的所有 ranks)都会收到完全相同的一批请求,从而可以协同地为这些请求分配资源和执行计算。
3. 代码分步解析¶
def recv_requests(self) -> List[Req]: """Receive results at tp_rank = 0 and broadcast it to all other TP ranks.""" # ========================================================================= # Step 1: 接收请求 (Request Reception) # 只有特定的进程会从外部接收请求。 # ========================================================================= # --- Case A: 流水线并行 (Pipeline Parallelism, PP) 的第一个阶段 --- if self.pp_rank == 0: # 在第一个PP阶段中,只有 leader worker (attn_tp_rank == 0) 从ZMQ套接字接收。 if self.attn_tp_rank == 0: recv_reqs = [] # 从 TokenizerManager 接收生成/嵌入请求 (非阻塞) while True: try: recv_req = self.recv_from_tokenizer.recv_pyobj(zmq.NOBLOCK) except zmq.ZMQError: break # 队列为空,退出循环 recv_reqs.append(recv_req) # 从 RpcManager 接收控制请求 (非阻塞) while True: try: recv_rpc = self.recv_from_rpc.recv_pyobj(zmq.NOBLOCK) except zmq.ZMQError: break # 队列为空,退出循环 recv_reqs.append(recv_rpc) else: # 同一个PP阶段但不是 leader 的其他TP rank,它们不直接接收,等待广播。 recv_reqs = None # --- Case B: 流水线并行的后续阶段 --- else: # 如果不是第一个PP阶段 (pp_rank > 0),请求不是从外部来, # 而是从上一个PP阶段的 worker 传递过来的。 if self.attn_tp_rank == 0: # ... point_to_point_pyobj 调用,从上一个PP rank接收请求对象 # 这实现了请求信息在流水线中的传递。 recv_reqs = point_to_point_pyobj(...) else: # 同样,非 leader 的TP rank 等待广播。 recv_reqs = None # ========================================================================= # Step 2: 分发/广播请求 (Request Distribution / Broadcast) # 将接收到的请求分发给组内的其他进程。 # ========================================================================= # --- Case 1: 启用了 DP-Attention 的复杂情况 --- if self.server_args.enable_dp_attention: # 这种模式下,需要区分“工作请求”和“控制请求”,因为它们可能需要广播到不同的进程组。 if self.attn_tp_rank == 0: # 将请求分为两类 work_reqs = [req for req in recv_reqs if isinstance(req, (TokenizedGenerateReqInput, TokenizedEmbeddingReqInput))] control_reqs = [req for req in recv_reqs if not isinstance(req, (TokenizedGenerateReqInput, TokenizedEmbeddingReqInput))] else: work_reqs = None control_reqs = None # 将“工作请求”广播给 Attention TP 组内的所有进程 if self.attn_tp_size != 1: work_reqs = broadcast_pyobj(work_reqs, ..., group=self.attn_tp_cpu_group) # 将“控制请求”广播给完整的 TP 组内的所有进程 if self.tp_size != 1: control_reqs = broadcast_pyobj(control_reqs, ..., group=self.tp_cpu_group) # 合并两类请求 recv_reqs = work_reqs + control_reqs # --- Case 2: 标准的张量并行 (TP) 情况 --- elif self.tp_size != 1: # 如果TP > 1,将 leader (tp_rank=0) 收到的所有请求广播给组内其他所有进程。 recv_reqs = broadcast_pyobj( recv_reqs, self.tp_group.rank, self.tp_cpu_group, src=self.tp_group.ranks[0], ) # --- Case 3: 单GPU,无并行 --- # 如果 tp_size == 1,则不需要任何广播,直接返回接收到的请求。 return recv_reqsdef recv_requests(self) -> List[Req]: """Receive results at tp_rank = 0 and broadcast it to all other TP ranks.""" # ========================================================================= # Step 1: 接收请求 (Request Reception) # 只有特定的进程会从外部接收请求。 # ========================================================================= # --- Case A: 流水线并行 (Pipeline Parallelism, PP) 的第一个阶段 --- if self.pp_rank == 0: # 在第一个PP阶段中,只有 leader worker (attn_tp_rank == 0) 从ZMQ套接字接收。 if self.attn_tp_rank == 0: recv_reqs = [] # 从 TokenizerManager 接收生成/嵌入请求 (非阻塞) while True: try: recv_req = self.recv_from_tokenizer.recv_pyobj(zmq.NOBLOCK) except zmq.ZMQError: break # 队列为空,退出循环 recv_reqs.append(recv_req) # 从 RpcManager 接收控制请求 (非阻塞) while True: try: recv_rpc = self.recv_from_rpc.recv_pyobj(zmq.NOBLOCK) except zmq.ZMQError: break # 队列为空,退出循环 recv_reqs.append(recv_rpc) else: # 同一个PP阶段但不是 leader 的其他TP rank,它们不直接接收,等待广播。 recv_reqs = None # --- Case B: 流水线并行的后续阶段 --- else: # 如果不是第一个PP阶段 (pp_rank > 0),请求不是从外部来, # 而是从上一个PP阶段的 worker 传递过来的。 if self.attn_tp_rank == 0: # ... point_to_point_pyobj 调用,从上一个PP rank接收请求对象 # 这实现了请求信息在流水线中的传递。 recv_reqs = point_to_point_pyobj(...) else: # 同样,非 leader 的TP rank 等待广播。 recv_reqs = None # ========================================================================= # Step 2: 分发/广播请求 (Request Distribution / Broadcast) # 将接收到的请求分发给组内的其他进程。 # ========================================================================= # --- Case 1: 启用了 DP-Attention 的复杂情况 --- if self.server_args.enable_dp_attention: # 这种模式下,需要区分“工作请求”和“控制请求”,因为它们可能需要广播到不同的进程组。 if self.attn_tp_rank == 0: # 将请求分为两类 work_reqs = [req for req in recv_reqs if isinstance(req, (TokenizedGenerateReqInput, TokenizedEmbeddingReqInput))] control_reqs = [req for req in recv_reqs if not isinstance(req, (TokenizedGenerateReqInput, TokenizedEmbeddingReqInput))] else: work_reqs = None control_reqs = None # 将“工作请求”广播给 Attention TP 组内的所有进程 if self.attn_tp_size != 1: work_reqs = broadcast_pyobj(work_reqs, ..., group=self.attn_tp_cpu_group) # 将“控制请求”广播给完整的 TP 组内的所有进程 if self.tp_size != 1: control_reqs = broadcast_pyobj(control_reqs, ..., group=self.tp_cpu_group) # 合并两类请求 recv_reqs = work_reqs + control_reqs # --- Case 2: 标准的张量并行 (TP) 情况 --- elif self.tp_size != 1: # 如果TP > 1,将 leader (tp_rank=0) 收到的所有请求广播给组内其他所有进程。 recv_reqs = broadcast_pyobj( recv_reqs, self.tp_group.rank, self.tp_cpu_group, src=self.tp_group.ranks[0], ) # --- Case 3: 单GPU,无并行 --- # 如果 tp_size == 1,则不需要任何广播,直接返回接收到的请求。 return recv_reqs-
pp_rank(Pipeline Parallelism Rank): 流水线并行的阶段编号。pp_rank=0 是第一个阶段,负责接收外部请求。后续阶段从前一个阶段接收中间结果和请求信息。
-
tp_rank(Tensor Parallelism Rank): 张量并行的编号。一个TP组内的所有进程协同完成一个层的计算。
-
attn_tp_rank: 这是一个更细粒度的TP rank,专门用于Attention计算。在启用DP-Attention时,它的并行组可能和模型的其他部分(如MLP)不同。attn_tp_rank=0 通常是Attention组的领导者。
-
zmq.NOBLOCK: 非阻塞模式。recv_pyobj 会立即尝试接收数据,如果队列为空,它会立即抛出 zmq.ZMQError 异常而不是等待。这确保了调度循环不会因为没有请求而卡住。
-
broadcast_pyobj: 这是一个SGLang的辅助函数,它封装了torch.distributed的广播操作(如broadcast_object_list),用于在分布式组内高效地广播Python对象列表。
-
DP-Attention: 一种特殊的并行策略,其中Attention计算在数据并行(DP)维度上进行,而MLP计算在张量并行(TP)维度上进行。这导致了Attention和MLP可能属于不同的并行组,因此需要区分广播目标。
recv_requests 是 SGLang 调度器与外界和内部分布式进程沟通的桥梁。它通过一个分层、有条件的逻辑,优雅地处理了多种复杂的并行模式:
-
分层接收: 首先根据 PP rank 判断是从外部接收还是从上一个流水线阶段接收。
-
指定领导者: 在接收阶段,只有 attn_tp_rank=0 这个领导者进程实际执行I/O操作,避免了竞争。
-
条件广播: 接收后,根据系统是否启用 DP-Attention 以及 TP size,选择合适的广播策略和广播组,将请求同步给所有需要它的伙伴进程。
get_next_batch_to_run,调度决策与批处理
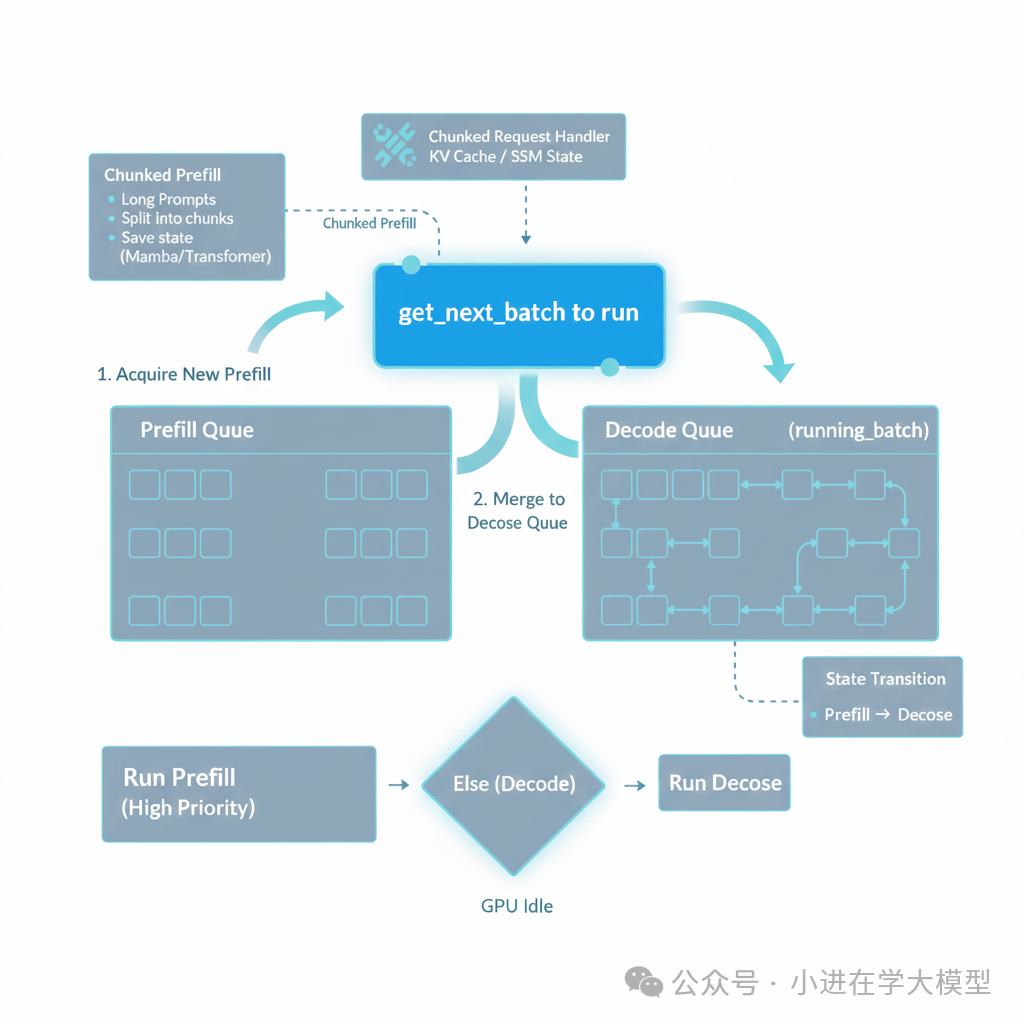
它的主要职责是决定下一个推理步骤(Step)应该执行什么任务。
它在“预填充(Prefill)”和“解码(Decode)”之间进行调度,同时处理复杂的显存管理、分块预填充(Chunked Prefill)以及分布式推理中的同步问题。
1. 核心功能概述¶
这个函数遵循Prefill 优先的调度策略(通常称为 FCFS 或按需调度),其逻辑流如下:
-
收尾与合并:处理上一步(last_batch)遗留的任务,将完成预填充的请求合并到解码队列(running_batch)中,并处理分块请求。
-
尝试获取新预填充:尝试从等待队列中构建一个新的预填充批次(new_batch)。
-
决策:
-
如果有新的预填充批次,直接返回它(优先执行 Prefill)。
-
如果没有新预填充,则执行解码步骤(运行 running_batch)。
2. 详细代码块分析¶
A. 处理分块请求 (Chunked Request) 与资源释放
chunked_req_to_exclude = set()if self.chunked_req: # 1. 暂时移出分块请求 chunked_req_to_exclude.add(self.chunked_req) self.tree_cache.cache_unfinished_req(self.chunked_req, chunked=True) # 2. 释放资源索引 (Req Pool Index) if self.tp_worker.model_runner.mambaish_config is not None: # 针对 Mamba/SSM 架构的特殊处理:保留内部状态 self.req_to_token_pool.free( self.chunked_req.req_pool_idx, free_mamba_cache=False ) else: self.req_to_token_pool.free(self.chunked_req.req_pool_idx)chunked_req_to_exclude = set()if self.chunked_req: # 1. 暂时移出分块请求 chunked_req_to_exclude.add(self.chunked_req) self.tree_cache.cache_unfinished_req(self.chunked_req, chunked=True) # 2. 释放资源索引 (Req Pool Index) if self.tp_worker.model_runner.mambaish_config is not None: # 针对 Mamba/SSM 架构的特殊处理:保留内部状态 self.req_to_token_pool.free( self.chunked_req.req_pool_idx, free_mamba_cache=False ) else: self.req_to_token_pool.free(self.chunked_req.req_pool_idx)-
背景:Chunked Prefill 是指当 Prompt 太长(超过显存限制或为了避免阻塞),将其拆分成多次前向传播。
-
逻辑:如果当前有一个正在处理的分块请求(self.chunked_req),它不能直接进入解码阶段。必须先把它“踢出”当前批次,保存其中间状态(KV Cache 或 SSM State),并释放其在当前批次中的占位符(req_pool_idx),以便下一轮重新调度它的下一个分块。
-
架构兼容性:代码显式检查了 mambaish_config,说明该框架不仅支持 Transformer,还支持 Mamba 等状态空间模型(SSM)。对于 Mamba,释放资源时不能清空其递归状态(State Cache)。
B. 批次合并 (Merge Logic)
if self.last_batch and self.last_batch.forward_mode.is_extend(): # ... (省略分块请求的额外过滤逻辑) ... # 1. 过滤已完成或被移出的请求 last_bs = self.last_batch.batch_size() self.last_batch.filter_batch( chunked_req_to_exclude=list(chunked_req_to_exclude) ) # 如果过滤后变小了,说明 Running Batch 可能有空位了 if self.last_batch.batch_size() < last_bs: self.running_batch.batch_is_full = False # 2. 将预填充完成的请求合并到解码队列 if not self.last_batch.is_empty() and not self.last_batch.is_prefill_only: if self.running_batch.is_empty(): self.running_batch = self.last_batch else: self.running_batch.merge_batch(self.last_batch)if self.last_batch and self.last_batch.forward_mode.is_extend(): # ... (省略分块请求的额外过滤逻辑) ... # 1. 过滤已完成或被移出的请求 last_bs = self.last_batch.batch_size() self.last_batch.filter_batch( chunked_req_to_exclude=list(chunked_req_to_exclude) ) # 如果过滤后变小了,说明 Running Batch 可能有空位了 if self.last_batch.batch_size() < last_bs: self.running_batch.batch_is_full = False # 2. 将预填充完成的请求合并到解码队列 if not self.last_batch.is_empty() and not self.last_batch.is_prefill_only: if self.running_batch.is_empty(): self.running_batch = self.last_batch else: self.running_batch.merge_batch(self.last_batch)-
状态流转:这是请求生命周期的关键一步:Prefill -> Decode。
-
self.last_batch 通常是刚刚跑完预填充的新请求。
-
self.running_batch 是正在进行逐个 Token 生成(解码)的老请求集合。
-
合并:代码将刚刚完成 Prefill 的请求(如果没结束且不是 prefill-only)合并进 running_batch,这样它们在下一个时间步就能开始生成 Token。
C. 获取新任务与同步处理
new_batch = self.get_new_batch_prefill()new_batch = self.get_new_batch_prefill()调度策略:调用 get_new_batch_prefill() 尝试获取新任务。这隐含了新任务优先的策略。
D. 最终决策 (Run Prefill or Decode?)
if new_batch is not None: # 优先级 1: 跑 Prefill ret = new_batchelse: # 优先级 2: 跑 Decode if not self.running_batch.is_empty(): self.running_batch = self.update_running_batch(self.running_batch) ret = self.running_batch if not self.running_batch.is_empty() else None else: # 无事可做 ret = Noneif new_batch is not None: # 优先级 1: 跑 Prefill ret = new_batchelse: # 优先级 2: 跑 Decode if not self.running_batch.is_empty(): self.running_batch = self.update_running_batch(self.running_batch) ret = self.running_batch if not self.running_batch.is_empty() else None else: # 无事可做 ret = None- 决策:
-
如果成功拿到了 new_batch(预填充),就返回它。这能最大化吞吐量。
-
如果没有新请求,就检查 running_batch(正在解码的任务)。调用 update_running_batch 来更新状态(例如剔除已生成结束符的请求)。
-
如果两边都空,返回 None(GPU 空闲)。
get_next_batch_to_run函数中self.last_batch.is_empty(),什么时候会是is_empty
在get_next_batch_to_run 这个函数的上下文中,self.last_batch.is_empty() 为 True 主要发生在 “上一轮跑了预填充(Prefill),但批次里的请求都被过滤掉了” 的情况。
最常见的原因只有两个:
- 1.原因是“分块预填充” (Chunked Prefill) 被移出了
这是代码逻辑中最直接导致这种情况的原因。
场景:你发了一个超级长的 Prompt(比如 10k token),显存一次装不下,或者为了不阻塞系统,系统决定把这个 Prompt 切成两半跑。 过程: 上一轮调度(Step T-1)跑了前半截(Chunk 1)。last_batch 里包含了这个请求。 进入当前函数(Step T)。 代码前面有一段逻辑:
chunked_req_to_exclude = set()if self.chunked_req: # 发现这是一个还没完全跑完 Prompt 的分块请求 chunked_req_to_exclude.add(self.chunked_req)# ...# 核心动作:把分块请求从 last_batch 里剔除self.last_batch.filter_batch( chunked_req_to_exclude=list(chunked_req_to_exclude))chunked_req_to_exclude = set()if self.chunked_req: # 发现这是一个还没完全跑完 Prompt 的分块请求 chunked_req_to_exclude.add(self.chunked_req)# ...# 核心动作:把分块请求从 last_batch 里剔除self.last_batch.filter_batch( chunked_req_to_exclude=list(chunked_req_to_exclude))结果:如果上一轮的批次里 只包含 这一个分块请求,经过 filter_batch 剔除后,self.last_batch 就变成了一个空壳(对象还在,但里面的请求列表空了)。
为什么这么做:
1.因为这个请求还没完成,不能进入 Decode 阶段(running_batch),所以不能执行 merge 操作。
- 请求中途被取消 (Request Abort) 场景:上一轮正在跑 Prefill 的时候,用户突然断开了连接,或者前端发来了 abort 信号。 过程: 在 filter_batch 这一步,系统会检查请求的状态。 如果发现请求已经被标记为 FINISHED_ABORT,它会被从批次中移除。 结果:如果这个批次里的所有请求都很倒霉地被取消了,那么 filter_batch 之后,self.last_batch 也会变为空。
总结
self.last_batch.is_empty() 为 True 的意思是: “上一轮确实干活了(跑了 Prefill),但是干完活、经过筛选后发现,没有任何一个请求有资格进入下一阶段(Decode)。”
这时候系统就会跳过 merge_batch(合并)步骤,避免把空数据加到运行队列里。
get_next_batch_to_run函数中merge_batch的作用是什么¶
这段代码的作用是实现 连续批处理 (Continuous Batching) 的核心步骤:将“新来的”请求和“正在跑的”请求合并到一起。
它的功能是将刚刚完成预填充(Prefill)阶段的请求,正式转移到解码(Decode)队列中。
具体拆解如下:
1. 场景背景¶
-
self.last_batch(新请求):刚刚跑完prefill一批请求。它们现在的状态是:已经理解了上下文了,准备好生成第一个字了。
-
self.running_batch(老请求):当前显存里正在逐字decode生成的请求列表。比如有的生成了 10 个字,有的生成了 50 个字。
2. 逻辑分支解释¶
情况 A:if self.running_batch.is_empty():¶
-
含义:当前gpu上没有正在做解码任务的请求(之前的都跑完了,或者系统刚启动)。
-
动作:self.running_batch = self.last_batch
-
解释:直接上位。这批新来的请求直接变身为当前的“运行队列”。
情况 B:else: (即 merge_batch)¶
-
含义:当前gpu上还有正在做decode解码任务的请求。
-
动作:self.running_batch.merge_batch(self.last_batch)
-
解释:这是性能优化的关键。系统不会等待老请求全部跑完才接新客,而是将新请求的 KV Cache 和元数据合并到老请求的数据结构中。
-
结果:在下一个 GPU 运行步骤(Step)中,系统会同时计算:
-
给老请求生成第 N+1 个字。
-
给新请求生成第 1 个字。
-
比喻:拼车。
-
公交车(GPU)上已经坐了一些乘客(老请求)正在去往目的地。
-
车开到下一站,又上来一批新乘客(新请求)。
-
司机(调度器)不会把老乘客赶下去,也不会等老乘客都下车了才让新乘客上。而是让新乘客挤一挤坐下,然后大家一起随车前进。
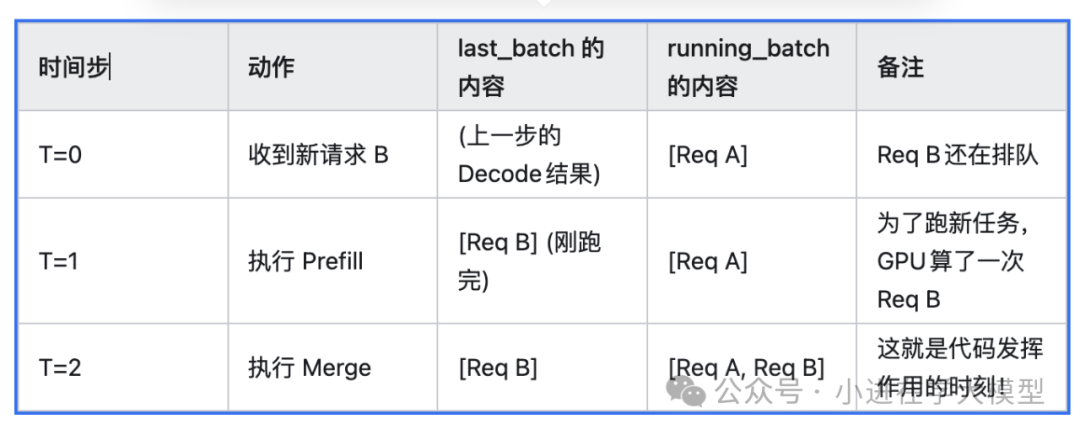
get_next_batch_to_run的整体流程¶
last_batch 本质上是 “上一个时间步(Step)刚刚在 GPU 上跑完的那个批次”。
它特指:刚刚完成Prefill的新请求批次。
下面我用一个生动的例子,带你走一遍 新请求从进来到进入running_batch 的全流程。
场景设定¶
-
当前状态:
-
GPU:正在忙。
-
Running Batch (正在跑的):里面有一个老请求 Req A(用户问:“讲个笑话”),已经生成了 5 个字。
-
Wait Queue (等候区):空的。
流程演示:新请求 Req B 来了¶
假设 Req B 是:“1+1等于几?”
1. 时间步 T=0:请求到达¶
-
用户发送 Req B。
-
Req B 经过 Tokenizer 处理,变成了 token IDs。
-
Req B 被放入 wait_queue(等候区)。
-
此时,running_batch 还在跑 Req A。
2. 时间步 T=1:调度器决定跑 Prefill¶
-
调度器(Scheduler)开始工作。
-
它发现 wait_queue 里有新请求 Req B。
-
决策:根据“新任务优先”原则,调度器决定暂停 Req A 的解码,先让 GPU 做 Req B 的预填充。
-
执行:GPU 运行 Req B 的 Prefill(计算 Prompt 的 KV Cache)。
-
执行结束:这个刚刚跑完的 Req B 批次,被赋值给 self.last_batch。
-
此时 last_batch 的状态:包含 Req B,状态为“Prefill 完成”,准备好生成第一个字。
-
last_batch.forward_mode 是 EXTEND (预填充模式)。
3. 时间步 T=2:回到 get_next_batch_to_run¶
-
状态检查:
-
self.last_batch 是谁?是 Req B。
-
self.running_batch 是谁?是 Req A (虽然刚才暂停了一下,但它还在队列里)。
-
text
# 1. 检查 last_batch 是否存在且刚跑完 Prefillif self.last_batch and self.last_batch.forward_mode.is_extend(): # ... (省略过滤逻辑) ... # 2. 检查 Running Batch 是否为空 if self.running_batch.is_empty(): # 这里 Running Batch 不为空,因为里面有 Req A self.running_batch = self.last_batch else: # 3. 命中这里!合并! # 把 Req B (last_batch) 合并进 Req A (running_batch) self.running_batch.merge_batch(self.last_batch)# 1. 检查 last_batch 是否存在且刚跑完 Prefillif self.last_batch and self.last_batch.forward_mode.is_extend(): # ... (省略过滤逻辑) ... # 2. 检查 Running Batch 是否为空 if self.running_batch.is_empty(): # 这里 Running Batch 不为空,因为里面有 Req A self.running_batch = self.last_batch else: # 3. 命中这里!合并! # 把 Req B (last_batch) 合并进 Req A (running_batch) self.running_batch.merge_batch(self.last_batch)
合并后的结果:self.running_batch 现在包含了 [Req A, Req B]。
4. 时间步 T=2 (后续):执行 Decode¶
-
函数继续往下走。
-
new_batch 为空(因为 Req B 已经被处理并合并了,队列里没新的了)。
-
最终返回:返回合并后的 self.running_batch。
-
GPU 执行:
-
对 Req A:生成第 6 个字。
-
对 Req B:生成第 1 个字。
get_new_batch_prefill 的作用是什么¶
它的主要任务是遍历等待队列(waiting_queue),尝试将请求一个个塞入当前的预填充批次(adder)中。在塞入之前,它设立了重重关卡(检查点),只有全部通过的请求才能被调度执行。
以下是详细的逐层分析:
1. 核心循环结构
for req in self.waiting_queue:for req in self.waiting_queue:遍历顺序:按照队列顺序遍历。通常 waiting_queue 在进入此循环前已经被 self.policy 排序过(例如按 FCFS 先来先到,或优先级排序)。
2. 第一道关卡:LoRA 资源限制
if self.enable_lora and not self.tp_worker.can_run_lora_batch( lora_set | set([req.lora_id for req in adder.can_run_list]) | set([req.lora_id])): self.running_batch.batch_is_full = True breakif self.enable_lora and not self.tp_worker.can_run_lora_batch( lora_set | set([req.lora_id for req in adder.can_run_list]) | set([req.lora_id])): self.running_batch.batch_is_full = True break-
目的:检查显存中的 LoRA 模型适配器数量是否超标。
-
逻辑:它计算了三个集合的并集:
-
lora_set:已经在 GPU 上运行的 Decode 请求使用的 LoRA。
-
adder.can_run_list:本轮刚刚选中、准备上车的 Prefill 请求使用的 LoRA。
-
req.lora_id:当前正在考察的这个请求的 LoRA。
- 结果:如果这三者加起来超过了 Worker 支持的最大 LoRA 数量(例如 GPU 显存只能存 4 个不同的 LoRA),则停止调度,标记批次已满并跳出循环。
3. 第二道关卡:并发数量限制 (Slot Limit)
running_bs = len(self.running_batch.reqs)if len(adder.can_run_list) >= self.get_num_allocatable_reqs(running_bs): self.running_batch.batch_is_full = Truerunning_bs = len(self.running_batch.reqs)if len(adder.can_run_list) >= self.get_num_allocatable_reqs(running_bs): self.running_batch.batch_is_full = True-
目的:防止请求数量过多,超过系统的最大并发处理能力。
-
逻辑:
-
获取当前 Decode 阶段的请求数 running_bs。
-
计算还能容纳多少新请求 (get_num_allocatable_reqs)。
-
如果新选中的请求数 (len(adder.can_run_list)) 已经填满了剩余槽位,则标记 batch_is_full = True。
-
注意:这里没有立即 break。为什么?为了给下面的“抢占逻辑”留机会。
4. 第三道关卡:满员处理与抢占 (Preemption)
if self.running_batch.batch_is_full: if not self.try_preemption: break if not adder.preempt_to_schedule(req, self.server_args): breakif self.running_batch.batch_is_full: if not self.try_preemption: break if not adder.preempt_to_schedule(req, self.server_args): break-
触发条件:上面的并发检查将 batch_is_full 设为了 True。
-
分支 1:不抢占 (not self.try_preemption)
-
直接 break。既然满了,就不再看了,结束调度。
-
分支 2:尝试抢占
-
调用 adder.preempt_to_schedule(req, …)。
-
逻辑:询问“当前这个 req 的优先级是否比 adder.can_run_list 里的某个人更高?”
-
如果是,踢掉一个低优先级的,让当前 req 进来(虽然代码里没写踢掉的过程,通常是在 preempt_to_schedule 内部标记或返回 True 表示可行)。
-
如果不行(当前请求优先级不够高),则 break,调度结束。
核心动作:尝试添加请求 (Memory Allocation)
req.init_next_round_input(self.tree_cache)res = adder.add_one_req( req, has_chunked_req=(self.chunked_req is not None), truncation_align_size=self.truncation_align_size,)req.init_next_round_input(self.tree_cache)res = adder.add_one_req( req, has_chunked_req=(self.chunked_req is not None), truncation_align_size=self.truncation_align_size,)-
动作:调用 adder.add_one_req。这是最“重”的一步。
-
内部逻辑:adder 会模拟将该请求加入后,Token 数量是否超标?显存(KV Cache)是否足够?
-
Chunked 标记:传入 has_chunked_req,告诉计算器是否需要预留分块请求的资源。
结果处理与退出
if res != AddReqResult.CONTINUE: if res == AddReqResult.NO_TOKEN: if self.enable_hierarchical_cache: # 复杂的 full 逻辑... self.running_batch.batch_is_full = len(adder.can_run_list) > 0 ... else: self.running_batch.batch_is_full = True breakif res != AddReqResult.CONTINUE: if res == AddReqResult.NO_TOKEN: if self.enable_hierarchical_cache: # 复杂的 full 逻辑... self.running_batch.batch_is_full = len(adder.can_run_list) > 0 ... else: self.running_batch.batch_is_full = True break-
AddReqResult.CONTINUE:成功加入!进入下一次循环。
-
AddReqResult.NO_TOKEN:显存或 Token 配额不足。
-
这表示物理资源真的耗尽了。
-
设置 batch_is_full = True。
-
break 跳出循环。
-
HiCache 的特判:
-
如果启用了 HiCache,定义“满”的逻辑稍微宽松一点,防止因为缓存碎片导致的死锁(确保至少有一个任务在跑)。
总结:这个循环的决策流¶
-
LoRA 兼容吗? (不兼容 -> 停)
-
并发槽位还有吗? (没有 -> 看是否抢占 -> 抢不过 -> 停)
-
缓存数据取好了吗? (没好 -> 跳过看下一个,不停)
-
显存/Token 够不够? (adder.add_one_req)
-
够 -> 加入,继续。
-
不够 -> 停。