本文介绍了如何优化 slime 框架中的权重同步机制,将 QWen3-30B-A3B 模型的权重更新时间从 60 秒优化到 7 秒。
1. 什么是 slime?¶
slime 是一个强化学习大规模训练框架,提供以下核心能力:
- 多功能 – 拥有完全可定制的 rollout 接口和灵活的训练设置(同卡或分离、同步或异步、RL 或 SFT)。
- 高性能 - 原生集成 Megatron 和 SGLang 进行训练和推理。
- 易维护 - 轻量级代码库,并可从 Megatron 预训练平滑过渡到 SGLang 部署。
- 大规模验证 - 最近发布的 zai-org/GLM-4.5 (355B) 和 zai-org/GLM-4.5-Air (106B) 都是通过 slime 做的 RL 训练。
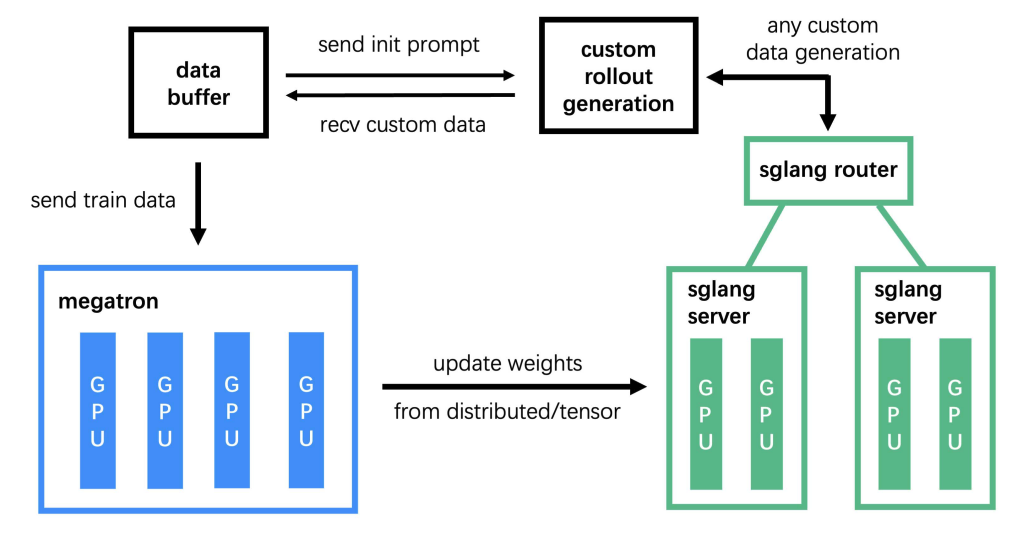
slime 主要由三个核心模块组成:
- 训练模块(Megatron) – 处理主要的训练过程,从数据缓冲区读取数据,并在训练后与 rollout 模块同步参数
- Rollout 模块(SGLang + Router) – 生成新数据,包括奖励和 sampling 后的输出结果,并将其写入数据缓冲区
- 数据 Buffer 模块 – 作为桥接模块,管理 prompt 初始化、自定义数据和 rollout 生成策略。
2. 什么是权重同步?¶
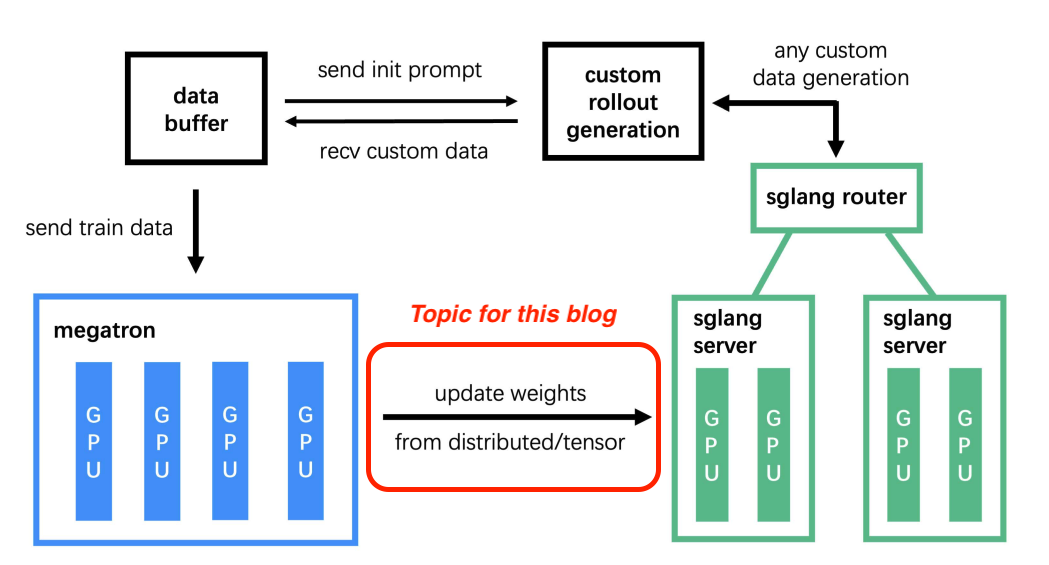
在 LLM 强化学习中,权重同步是指将更新好的训练端的模型权重同步到推理端的过程,以确保推理工作节点始终使用最新的模型参数。
为什么需要权重同步?¶
在 LLM 的强化学习(如 PPO、GRPO 等)中:
- 训练引擎在每个
optimizer.step()后更新策略模型权重。 - 推理引擎生成 rollout、采样动作,但它需要使用最新的策略模型权重以与训练保持一致。
- 这两个组件通常分别运行在不同的进程和不同的框架(如 Megatron/FSDP vs. SGLang/vLLM),因此需要显式同步。
注意:这篇文章专门关注同卡 (Colocate) 模式,我们在整个权重更新过程中使用
update_weights_from_tensorAPI。在分离 (Disaggregate) 模式下,slime 使用update_weights_from_distributedAPI,通常通过 NVLink/InfiniBand 互连传输权重。
3. 权重同步在 slime 中如何工作?¶
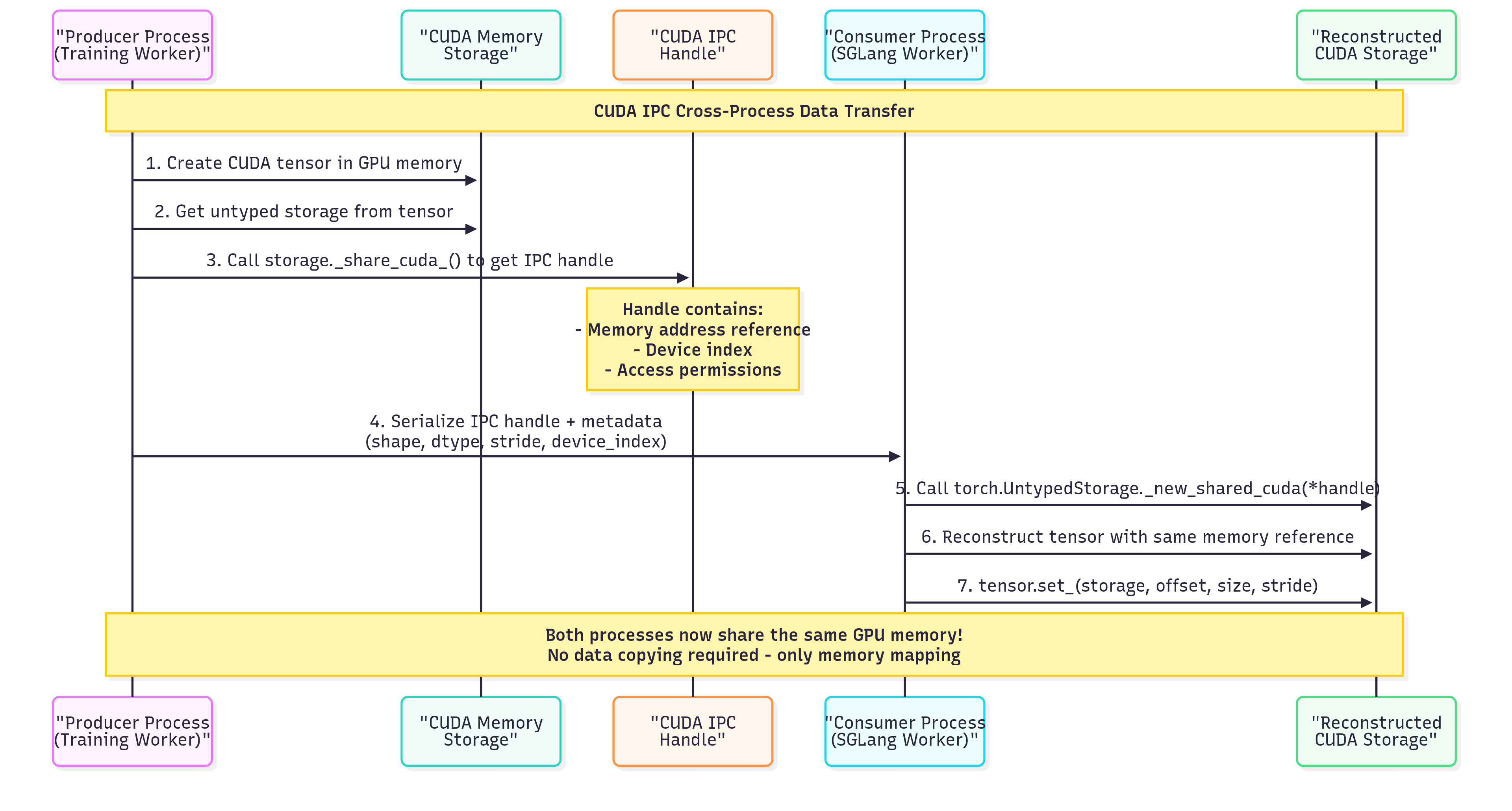
在 slime 的同卡 (Colocate) 模式下,Megatron 的工作进程和 SGLang 的工作进程共同位于相同的物理 GPU 上。为了实现零拷贝权重传输,Megatron 不发送数据本身,而是通过将 Tensor 序列化成 CudaIpcHandlers 再将其发送给 SGLang 的工作进程,而 SGLang 可以直接通过这些 CudaIpcHandlers 来访问权重数据进行映射,这样可以极大地提高传输效率。
以下是详细的 5 步工作流程:
- 收集分布式 Tensor:从 Megatron 训练进程中的 PP/TP/EP/ETP 等级的分布式工作节点收集,并 gather 成完整的 Tensor。代码
- 序列化为 CUDA IPC:将 Tensor 转换为 CudaIpcHandlers 并将其聚合成一个个大约为 512MB 的 bucket tensor 中。代码
- API 通信:通过
update_weights_from_tensorAPI 将序列化好的 CudaIpcHandlers 发送到 SGLang Server。代码 - 分发到工作节点:SGLang Server 将 CudaIpcHandlers 分发到 SGLang 在各个 GPU Rank 上启动好的 TP Worker 进程。代码
- 重构和加载:TP Worker 将 CudaIpcHandlers 反序列化并进行映射,指向 Megatron 之前聚合好的同一片 GPU 地址,从而将 Megatron 的权重加载到 SGLang 中。代码
为什么采用基于服务器的架构?¶
- 保证训推一致。因为线上任务使用 server based 架构,所以 RL 这里使用完全相同的配置,可以避免模型上线或评测时的指标不匹配,并充分复用 sglang 对 server 做的测试和性能优化。
- 减少用户自定义 rollout 时的心智负担。通过 server based + router 架构,让编写 rollout 就像调用常规线上服务,同时可以将 router address 对外暴露,让外部的 agent 环境调用 slime 内部的 sglang server,实现纯异步训练。
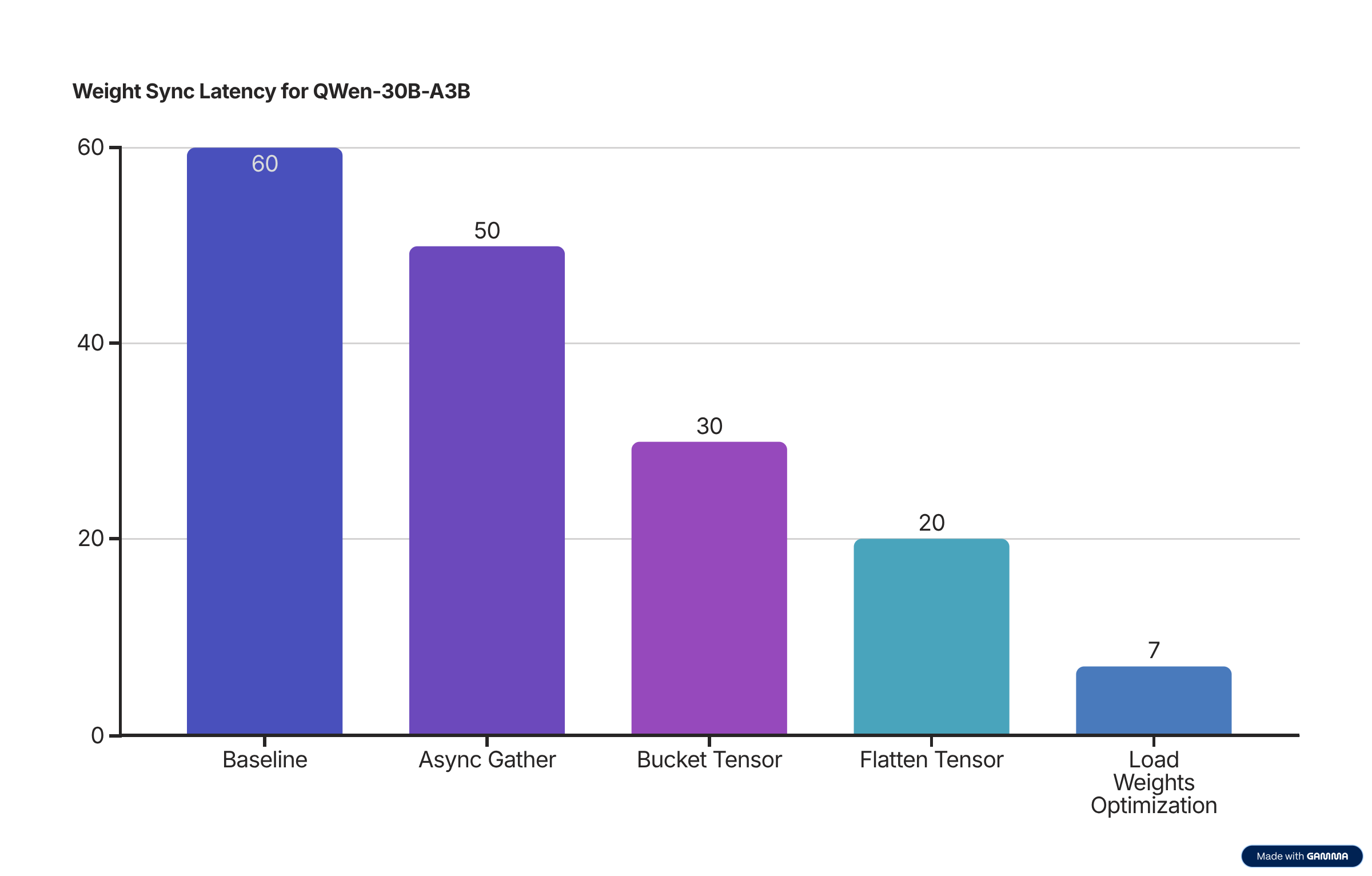
4. 我们的工作:将 QWen3-30B-A3B 模型的权重更新时间从 60 秒优化到 7 秒¶
注意:上图是根据这个 Github Issue 里的所有 PR 做完之后往回捋出来的,以便更容易理解逻辑,实际上,我们没有按照上图所示的改进顺序进行,因为实际工作场景中自然是按照从易到难实现,而不是根据物理传输过程中的顺序。
4.0 GPU 上的跨进程数据传输:CUDA IPC Handler¶
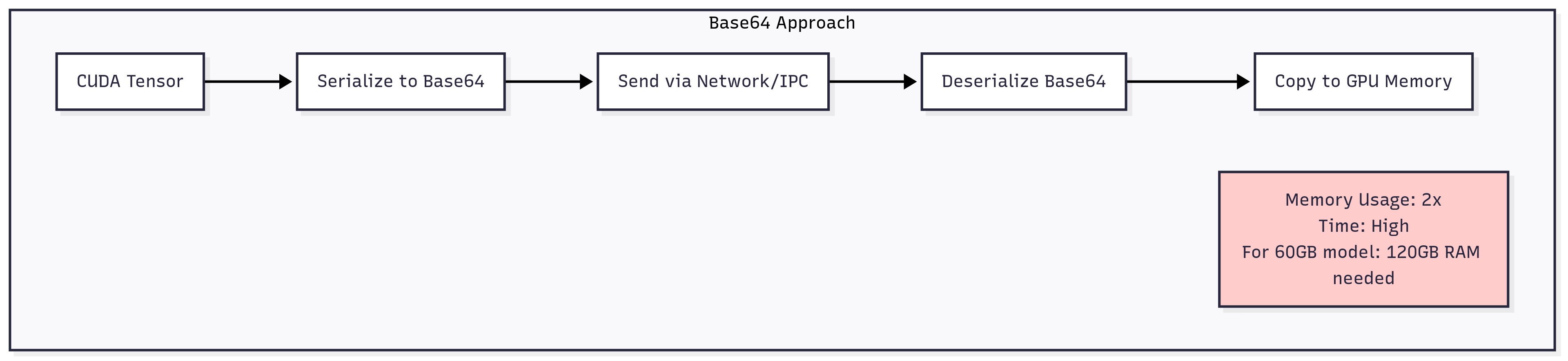
在进程间传输大型模型权重时,我们肯定想要避免将整个模型序列化成 Base64 这种方式然后传输,尤其在同卡情况下,这样传输效率太低,内存和延迟都会爆炸。
不太现实的传统方法¶
利用 CUDA IPC Handler 同卡零拷贝传输¶
主要优势:¶
- 零拷贝传输:通过内存映射来传输数据,避免在进程间传送大量的数据
- 最小 CPU 内存开销:CUDA IPC Handler 非常小 vs 序列化数据的 GB 级别
这其实只是我们的 baseline 实现,虽然比直接传数据要快得多,但仍然花了 60 秒,显然有很多优化空间。
4.1 优化 Megatron Worker 中 Tensor 聚合过程:从 60 秒到 50 秒¶
第一个瓶颈来自于聚合分散在不同 Megatron Worker 中的 Tensor,在此之前先浅浅介绍一下不同的并行策略 (TP/PP/EP) 下的聚合通信方式。这里简单介绍一下,对于后续的优化会有帮助。
按并行类型划分的通信策略¶
| 并行方式 | 通信方式 | 原因 |
|---|---|---|
| 张量并行 (TP) | all_gather | 每个 rank 有部分 Tensor → 收集所有部分以重构完整 Tensor |
| 流水线并行 (PP) | broadcast | 源 rank 有完整层 → 分发到其他 PP Rank |
| 专家并行 (EP) | broadcast | 源 rank 有完整专家 → 分发到其他专家组 |
我们采取的优化很简单,就是采用异步收集 Tensor 来打满带宽,在下面的例子中,我们以 TP Tensor 的 all_gather 为例。
解决方案:异步 Tensor 收集/广播¶
def async_tensor_gathering():
# 阶段 1:同时启动所有异步操作
handles = []
for param in tensor_parallel_params:
handle = dist.all_gather(
param_partitions, param.data,
group=tp_group, async_op=True # 关键:非阻塞
)
handles.append(handle)
# 阶段 2:等待所有操作完成
for handle in handles:
handle.wait() # 通过批量等待最大化并行性
# 阶段 3:所有通信完成后处理所有结果
gathered_params = []
for info, direct_param, handle, param_partitions, partition_dim in gather_tasks:
param = torch.cat(param_partitions, dim=partition_dim)
gathered_params.append(param)
return gathered_paramsdef async_tensor_gathering():
# 阶段 1:同时启动所有异步操作
handles = []
for param in tensor_parallel_params:
handle = dist.all_gather(
param_partitions, param.data,
group=tp_group, async_op=True # 关键:非阻塞
)
handles.append(handle)
# 阶段 2:等待所有操作完成
for handle in handles:
handle.wait() # 通过批量等待最大化并行性
# 阶段 3:所有通信完成后处理所有结果
gathered_params = []
for info, direct_param, handle, param_partitions, partition_dim in gather_tasks:
param = torch.cat(param_partitions, dim=partition_dim)
gathered_params.append(param)
return gathered_params性能影响:¶
- 之前:顺序收集 → 60 秒
- 之后:并行异步 Tensor 收集 → 50 秒
代码参考:slime/backends/megatron_utils/update_weight_utils.py
相关 PR:https://github.com/THUDM/slime/pull/135
4.2 通过 Tensor 分桶优化 SGLang 服务器调用:从 50 秒到 30 秒¶
下一个瓶颈是对 SGLang 服务器的 API 调用数量。在基础实现里,我们对每个 Tensor 进行单独的 HTTP 请求造成了显著的开销。这在 Dense Model 里问题不是很大,因为相对来说 Tensor 的数量较少,而 MOE Model 经常会有上万个 Tensor 需要传播,因此这个问题比较严重。
问题:太多小的 API 调用¶
# 低效:每个 Tensor 一个 API 调用
for name, tensor in named_tensors.items():
response = requests.post(
f"http://{server_host}/update_weights_from_tensor",
json={"tensor_name": name, "tensor_data": serialize(tensor)}
)# 低效:每个 Tensor 一个 API 调用
for name, tensor in named_tensors.items():
response = requests.post(
f"http://{server_host}/update_weights_from_tensor",
json={"tensor_name": name, "tensor_data": serialize(tensor)}
)解决方案:Tensor 分桶¶
优化方案是在传输前将参数智能地分组为最优大小的 bucket。以下是 slime 的样例代码:
def get_param_info_buckets(args, model) -> list[list[ParamInfo]]:
param_infos = get_param_infos(args, model)
param_info_buckets = [[]]
buffer_size = 0
for info in param_infos:
param_size = info.size * tp_size
# 当超过大小限制时创建新桶
if buffer_size + param_size > args.update_weight_buffer_size:
param_info_buckets.append([])
buffer_size = 0
param_info_buckets[-1].append(info)
buffer_size += param_size
return param_info_buckets
self.param_info_buckets = get_param_info_buckets(args, model)
# 发送桶而不是单个 Tensor
for param_infos in tqdm(self.param_info_buckets, disable=rank != 0, desc="Update weights"):
self._update_bucket_weights_from_tensor(param_infos)def get_param_info_buckets(args, model) -> list[list[ParamInfo]]:
param_infos = get_param_infos(args, model)
param_info_buckets = [[]]
buffer_size = 0
for info in param_infos:
param_size = info.size * tp_size
# 当超过大小限制时创建新桶
if buffer_size + param_size > args.update_weight_buffer_size:
param_info_buckets.append([])
buffer_size = 0
param_info_buckets[-1].append(info)
buffer_size += param_size
return param_info_buckets
self.param_info_buckets = get_param_info_buckets(args, model)
# 发送桶而不是单个 Tensor
for param_infos in tqdm(self.param_info_buckets, disable=rank != 0, desc="Update weights"):
self._update_bucket_weights_from_tensor(param_infos)注意:通过多次实验,我们发现 512MB 是在内存和延迟之间平衡的最佳 bucket 大小。当然这个参数可以直接在 slime 的参数中调整,我们试过 1GB,2GB 的速度也不错,用户可以自己稍微尝试一下。
性能影响:¶
- 之前:上万个单独 API 调用 → 50 秒
- 之后:几百个 API 调用 → 30 秒
- 改进:通过最小化 HTTP 开销减少 40%
4.3 合并多个 Tensor 成一个 Tensor:减少 CUDA IPC 开销:从 30 秒到 20 秒¶
即使有了 Tensor 分桶,我们仍然面临一个重要瓶颈:CUDA IPC Handler Open/Close 开销。每个 Tensor 都需要自己的 IPC Handler 创建和清理,导致上万个频繁的操作。目前这个过程过于频繁,已经成为整个同步过程中的瓶颈。
问题:太多 CUDA IPC 操作¶
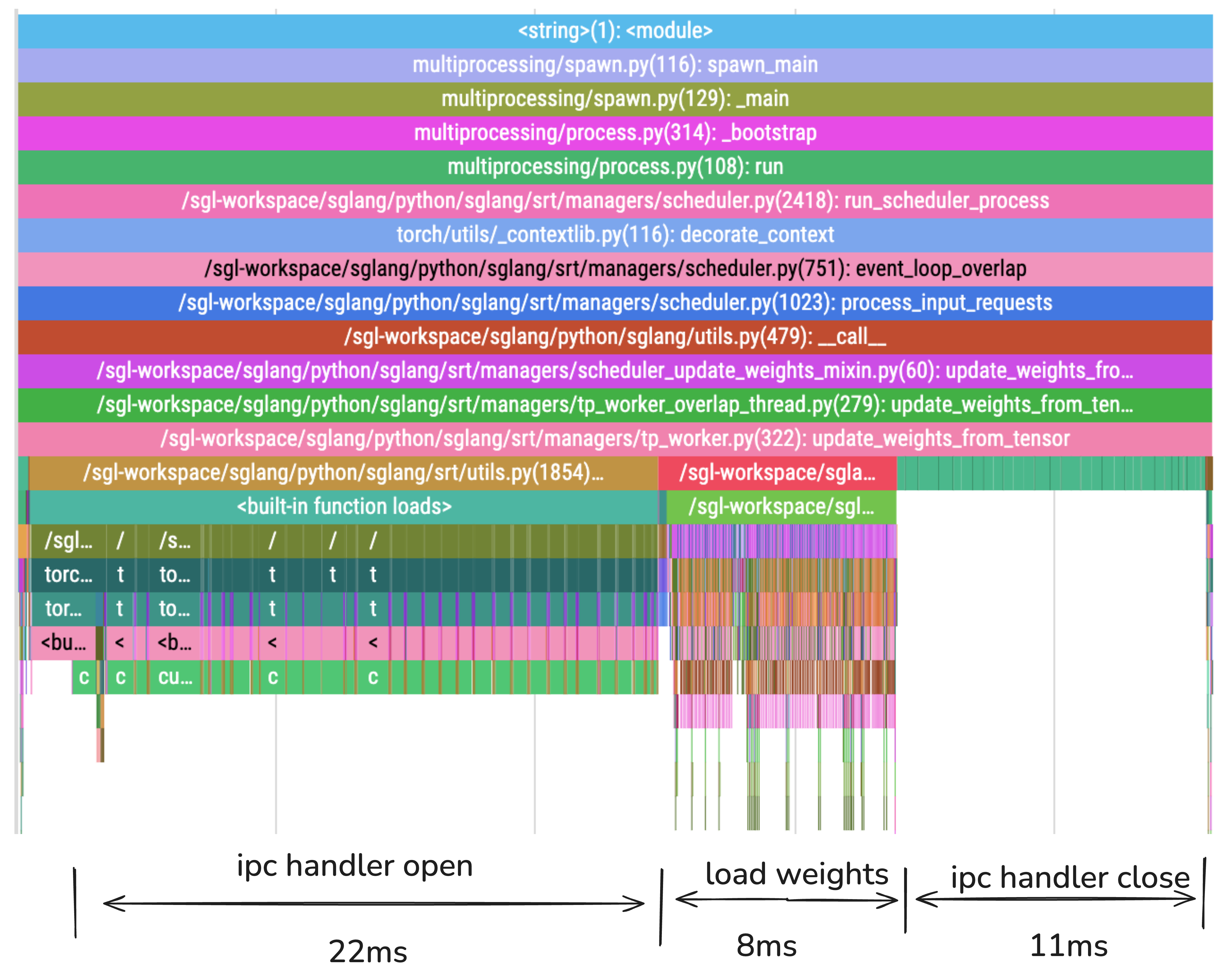
性能分析¶
上面的 flame chart 揭示了我们权重同步过程中的真正瓶颈。以下是详细分解:
| 阶段 | 持续时间 | 百分比 | 主要活动 |
|---|---|---|---|
| IPC 句柄打开 | 22ms | 54% | CUDA IPC 句柄创建和内存映射 |
| 加载权重 | 8ms | 19% | 实际权重加载和 Tensor 重构 |
| IPC 句柄关闭 | 11ms | 27% | CUDA IPC 清理和资源释放 |
| 总计 | 41ms | 100% | SGLang 中完整的权重更新周期 |
关键发现:81% 的时间花费在 CUDA IPC 操作(打开+关闭)上,而只有 19% 用于实际权重加载。这解释了为什么合并多个 Tensor 可以提供如此显著的改进。
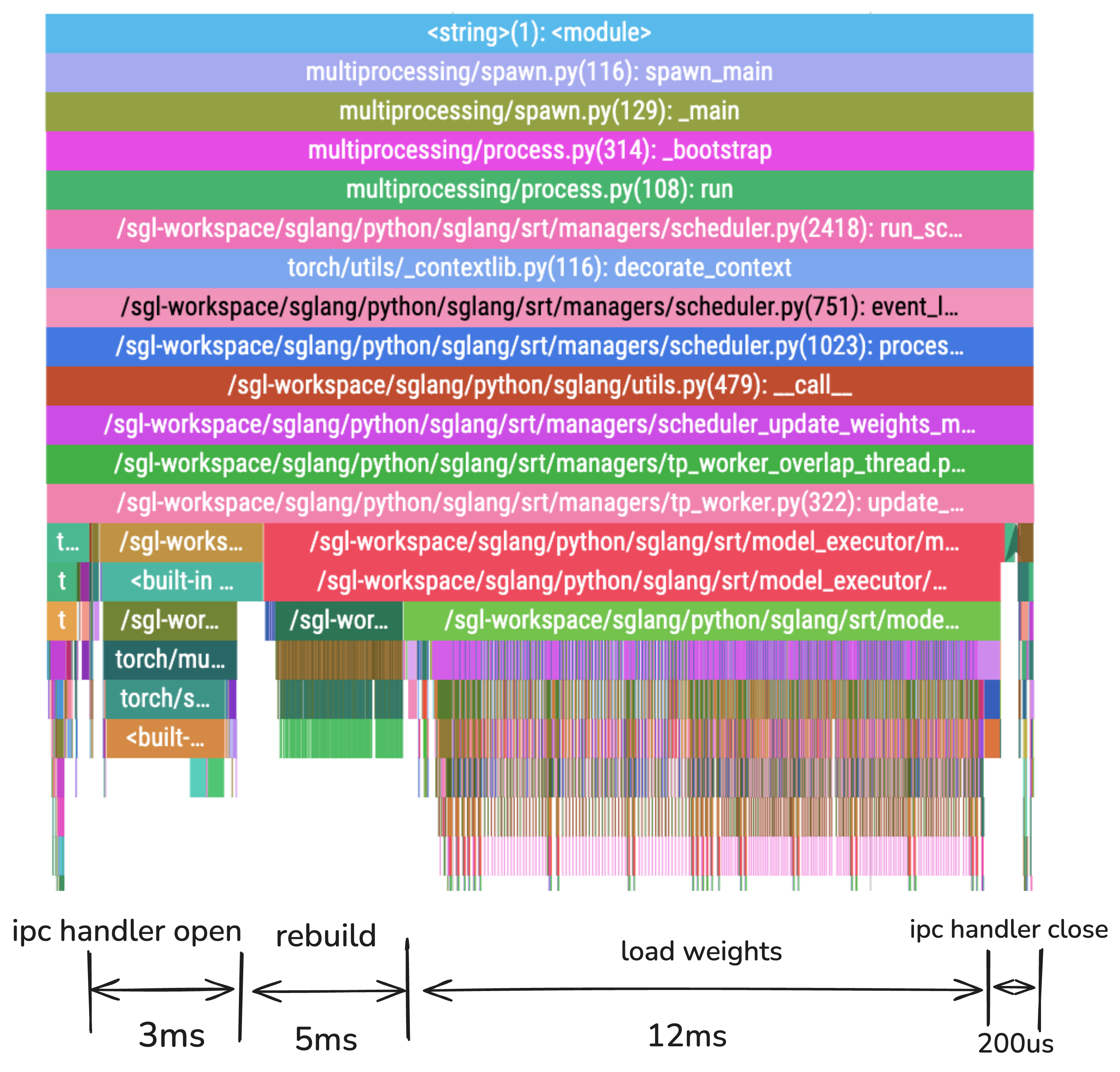
扁平化 Tensor 后的性能¶
| 阶段 | 持续时间 | 百分比 | 改进 |
|---|---|---|---|
| IPC 句柄打开 | 3ms | 15% | 快 86% |
| 重建 | 5ms | 25% | Tensor 重构的新阶段 |
| 加载权重 | 12ms | 60% | 轻微变化 |
| IPC 句柄关闭 | 200μs | 1% | 快 98% |
| 总计 | 20ms | 100% | 相比合并前减少了 51% |
关键成就:通过合并多个 Tensor,我们将 IPC 操作从总时间的 81% 减少到 16%,而权重加载在 60% 时成为主导阶段 - 这正是我们想要的!
有关如何实现合并多个 Tensor 等技术细节,请参考以下 PR:
相关 PR:
4.4 加载权重优化:最终性能提升:从 20 秒到 7 秒¶
在优化 IPC 开销后,我们还发现了权重加载过程本身的其他瓶颈,特别是对于 MoE 模型。
关键优化:¶
1. 参数字典缓存
# 之前:每次权重更新时昂贵的模型遍历
params_dict = dict(self.named_parameters())
# 之后:缓存参数字典
if not hasattr(self, "_cached_params_dict"):
self._cached_params_dict = dict(self.named_parameters())
params_dict = self._cached_params_dict# 之前:每次权重更新时昂贵的模型遍历
params_dict = dict(self.named_parameters())
# 之后:缓存参数字典
if not hasattr(self, "_cached_params_dict"):
self._cached_params_dict = dict(self.named_parameters())
params_dict = self._cached_params_dict2. 重复的 Expert Map GPU Device Sync 优化
# 避免专家映射的重复 GPU 到 CPU 同步
if self.expert_map_cpu is not None and self.expert_map_gpu is None:
# 将专家映射移动到 GPU 一次并缓存
self.expert_map_gpu = self.expert_map_cpu.to(device="cuda")# 避免专家映射的重复 GPU 到 CPU 同步
if self.expert_map_cpu is not None and self.expert_map_gpu is None:
# 将专家映射移动到 GPU 一次并缓存
self.expert_map_gpu = self.expert_map_cpu.to(device="cuda")3. 重复的 CUDA Device 查询优化
# 缓存 CUDA 设备查询以避免重复的昂贵调用
@lru_cache(maxsize=8)
def get_device(device_id: Optional[int] = None) -> str:
# 缓存的设备查找消除了重复的 torch.cuda.is_available() 调用# 缓存 CUDA 设备查询以避免重复的昂贵调用
@lru_cache(maxsize=8)
def get_device(device_id: Optional[int] = None) -> str:
# 缓存的设备查找消除了重复的 torch.cuda.is_available() 调用性能影响:¶
- 之前:各种权重加载瓶颈 → 20 秒
- 之后:优化的参数缓存和设备处理 → 7 秒
- 改进:最终权重加载时间减少 65%
相关 PR:
5. 未来优化¶
目前 slime 可以做到 7 秒完成训推一体下 Qwen3 30B-A3B 模型 bf16 权重的参数同步。100 秒完成 GLM4.5 355B-A32B 的 fp8 blockwise 量化 + 参数更新。
但还有不少的优化空间,欢迎社区的小伙伴联系我们一起继续优化。下面是一些可能的优化方向:
- 异步收集和发送:Megatron Worker 的收集和 SGLang Worker 的加载实际上可以异步,理论上最高能加快 1 倍的速度。
- 异步权重加载:非阻塞模型权重更新
- 零冗余布局:预计算推理引擎内存布局并进行零冗余拷贝,比如 megatron rank 0 只传送 sglang rank 0 实际需要的权重,目前还是有很大的冗余的。
6. 致谢¶
- slime 团队:https://github.com/THUDM/slime
- SGLang 团队:https://github.com/sgl-project/sglang