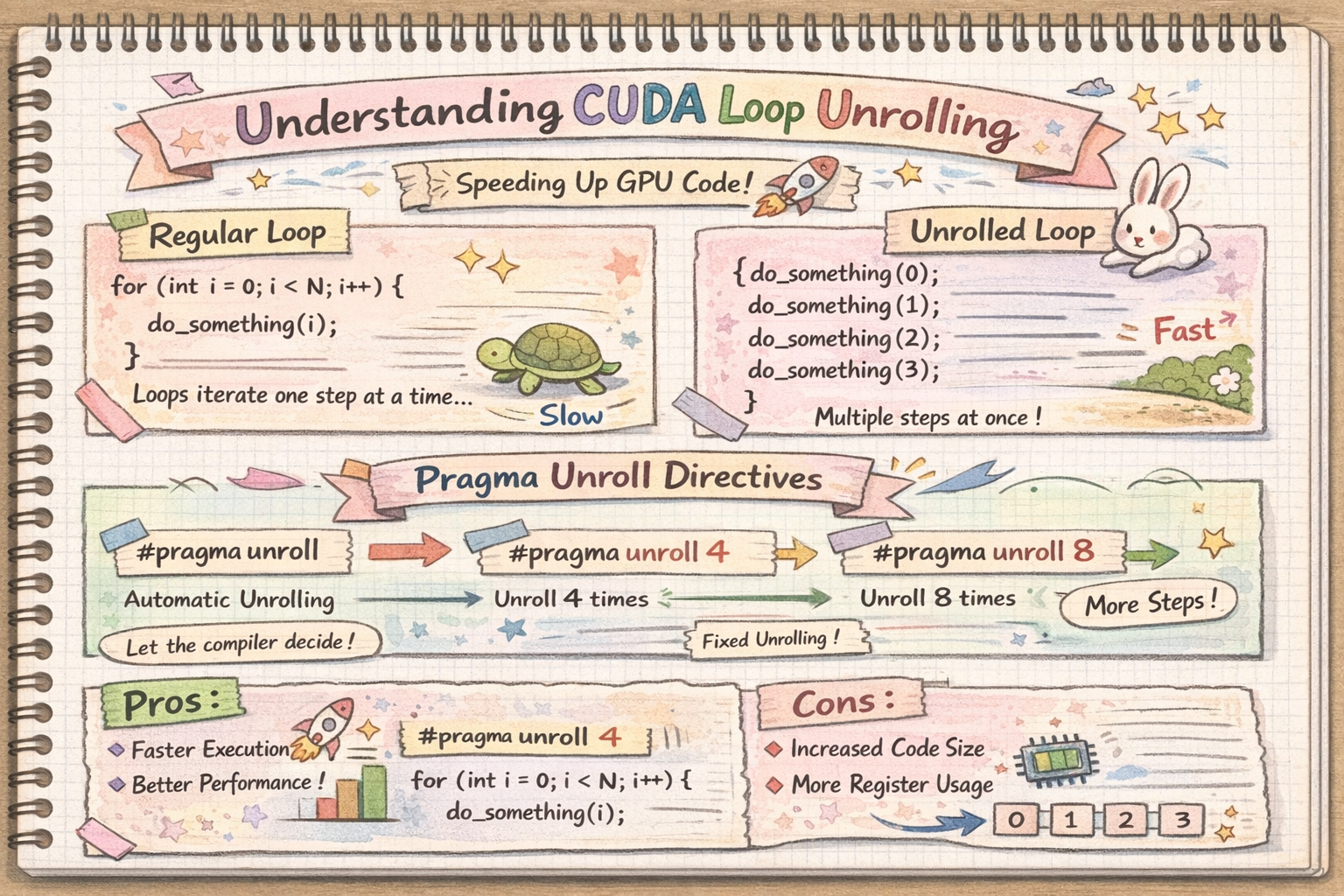
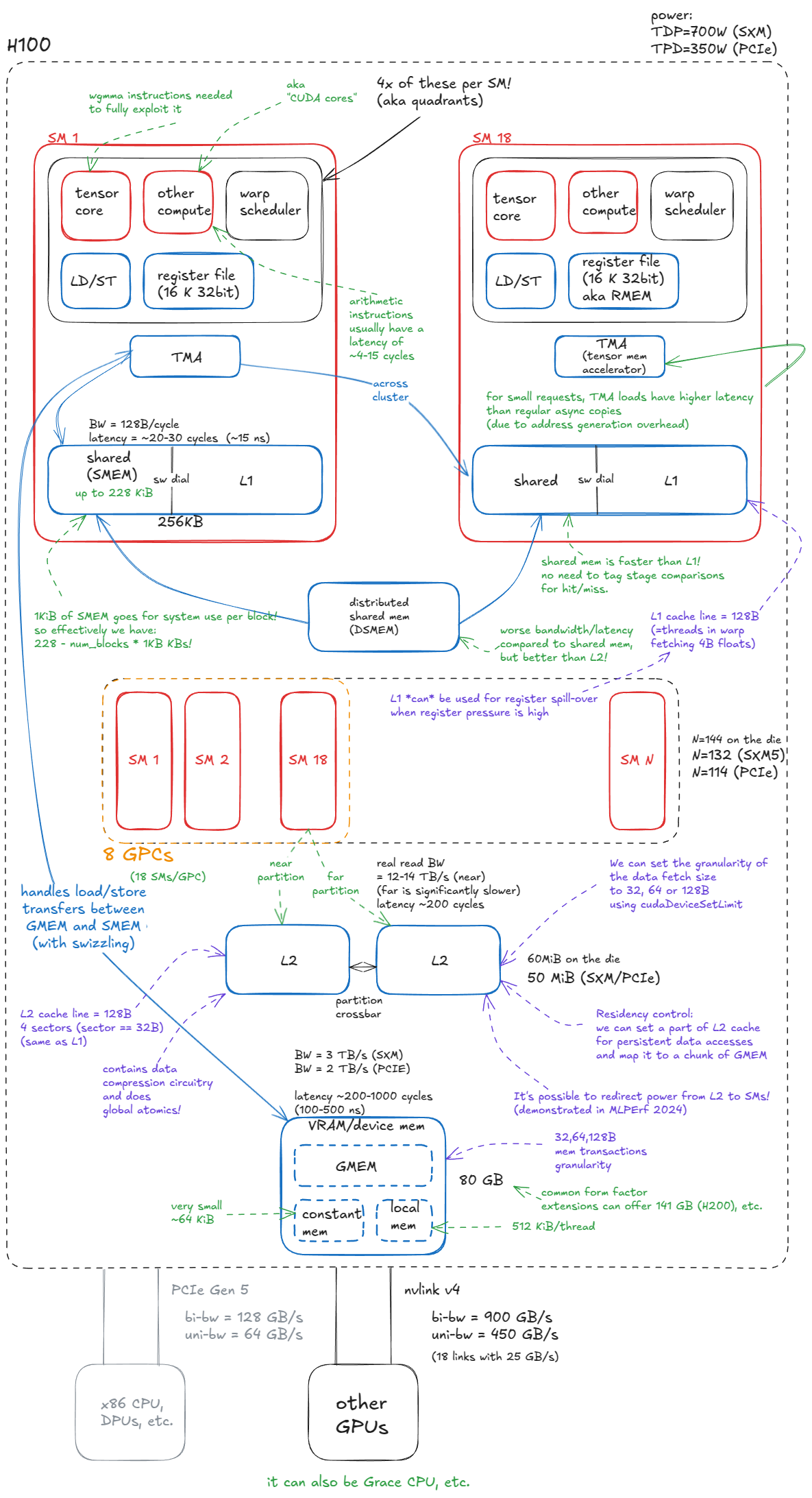
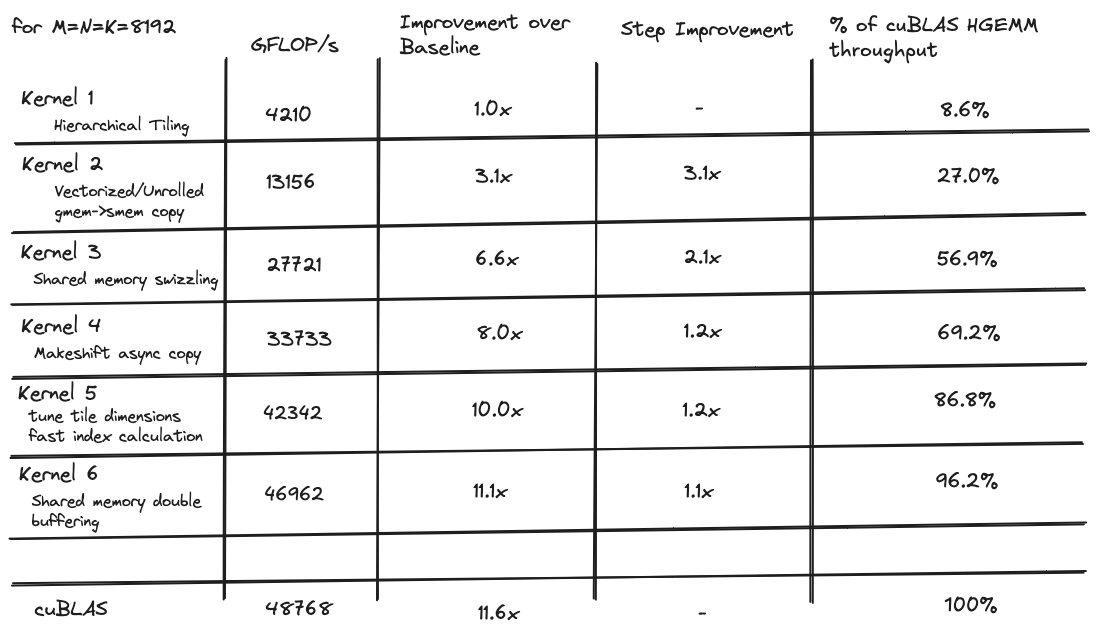
Writing Speed-of-Light Flash Attention for 5090 in CUDA C++ 📅 2025-08-23 ✍️ 8742 字 ⏱️ 20 min read CUDA FlashAttention