在大模型训练中,单纯的张量并行(TP)或序列并行(SP)往往难以覆盖所有层的通信需求。对于稠密的 Attention 层,TP 可以高效地切分权重矩阵;而对于 MoE 层,专家并行(EP)才是降低通信开销的关键。本文梳理一种将 TP、SP、EP 融合的混合并行策略——重点剖析 Attention 层的两种 out_linear 方案,以及 MoE 层的 Dispatch / Combine 机制,帮助理解它们如何协同工作以最大化吞吐。
一、两种混合并行图示¶
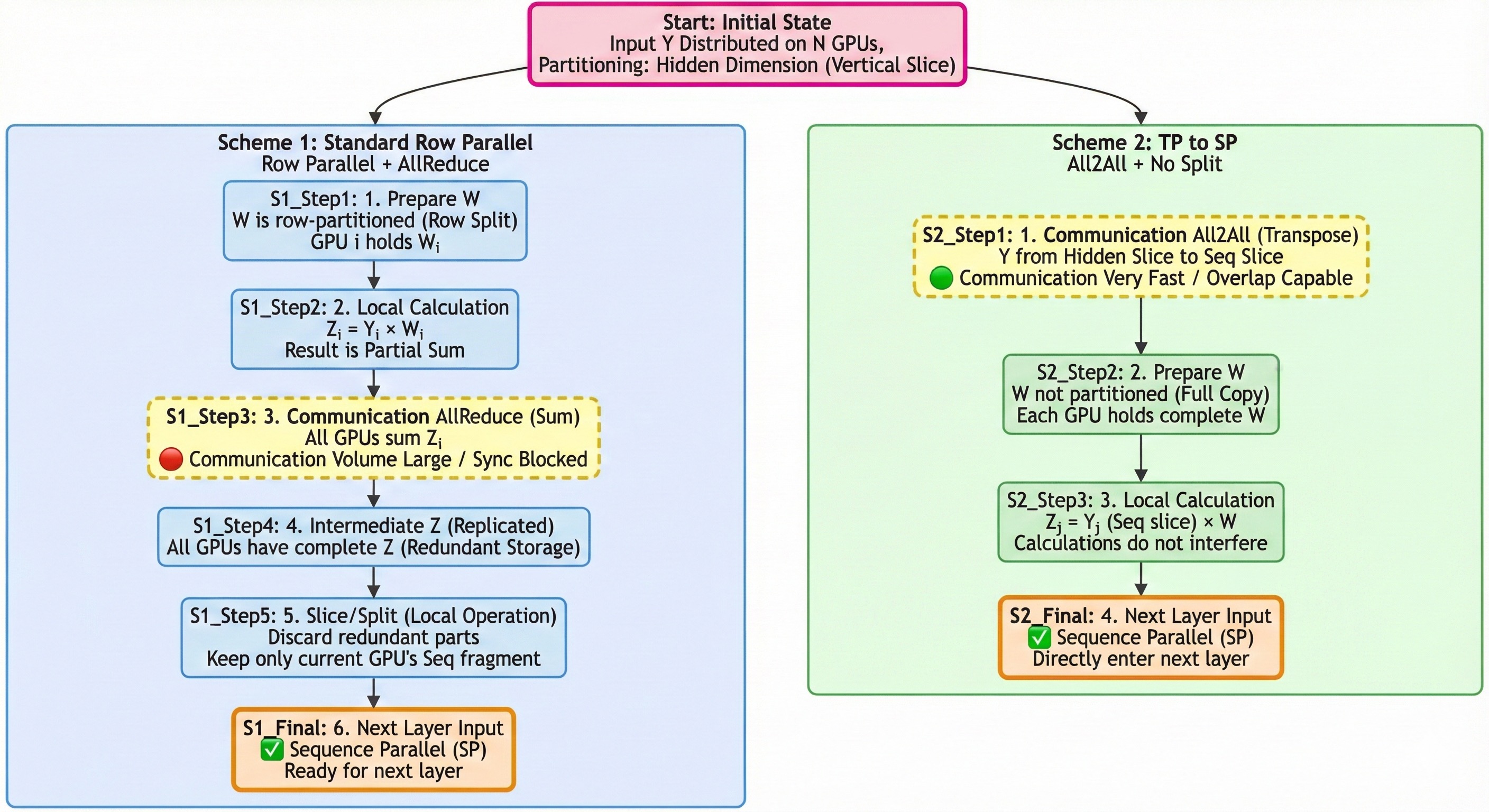
上图展示了 Attention 层的两种 out_linear 实现路径。两条路径都从同一个列并行 qkv_linear 出发,区别在于如何处理输出投影:一种走行并行 + all_reduce,另一种走 all2all + 完整权重。后续的 MoE 层则统一以 SP 排布作为输入,借助两次 all2all 完成专家路由与聚合。
二、并行原理解析¶
两条方案的起点相同:列并行的 qkv_linear 将输出激活按隐藏层维度切分分布在各 GPU 上。从这一状态出发,两条路径以不同方式完成 out_linear 并进入序列并行段。
2.1 前提:qkv_inear (列切)¶
两种方案都始于一个列并行 (Column-Parallel) 的 qkv_inear 层。
- 我们有 个 GPU。
- 输入 是复制的 (replicated)。
- 第一个
qkv inear层的权重 被按列切分:。 - GPU 计算:。
- 关键状态:计算完成后,中间激活 在 个 GPU 上是按隐藏层维度( 维度,也常称为 维度)切分的。
这里涉及到 Attention 的 TP 并行,原理可参考猛猿大佬文章 https://zhuanlan.zhihu.com/p/622212228,不再赘述。现在,我们要计算第二层 ,其中 是 out_linear 的权重。
此时有两条路可走:继续保持 维度的切分(方案一),或提前通信将切分轴转到序列维度(方案二)。
2.2 方案一:out_linear (行切) + all_reduce + Slice¶
这个方案的核心思想是:保持 维度的切分。
- 数据排布:
- 输入 (): (按 切分)。
- 权重 ():
out_linear权重 必须同样按 维度(即行)切分: 。
out_linear(局部计算):- GPU 拥有 和 。
- 它只能计算它所拥有的那部分乘积:。
all_reduce(通信):- 根据矩阵乘法,最终结果是 。
all_reduce操作在所有 GPU 之间对 进行求和。- 。
- 完整的 :
- 在所有 GPU 上都是完整的、复制的 (replicated)。
- 每张 GPU 从 的行维度平均 Slice 出一部分,转为序列并行送到下一层。
- 优点:
- 节省内存:每个 GPU 只需要存储 的 权重。这在权重(如 )非常大时至关重要。
- 缺点:
- 通信瓶颈:必须在计算 之后执行一个
all_reduce。这是一个同步操作,通信量为 的大小,可能会阻塞流水线。
- 通信瓶颈:必须在计算 之后执行一个
2.3 方案二:all2all + out_linear (不切分)¶
这是 “张量并行 (TP) 切换到 序列并行 (SP)” 的策略。这个方案的核心思想是:通过通信改变数据的切分维度。
- 数据排布:
- 输入 (): (按 切分)。
- 权重 ():
out_linear权重 不切分 (replicated)。每个 GPU 都有完整的 。
all2all(通信):- 这一步的目标是将 的数据排布从“按 切分”转置为“按序列 (Sequence) 维度切分”。
- 之前:GPU 拥有 (形状 )。
- 操作:
- GPU 将它的 沿着 维度切成 块:。
- GPU 将 发送给 GPU 。
- GPU 收到来自所有 个 GPU 的 。
- 之后:GPU 将收到的块沿着 维度拼接起来(⚠️:这里会有一个 transpose 操作),得到 (形状 )。
- 结果: 的排布从 个 的块(TP)转换成了 个 的块(SP)。
out_linear(局部计算):- GPU 拥有 (形状 ) 和完整的 (形状 )。
- 它计算 。
- 最终结果:
- 的形状是 。
- 最终输出 在 个 GPU 上是按序列 (Sequence) 维度切分的。
在工程实现上,它们是两种完全不同的并行范式,有着根本的取舍:
| 特性 | 方案一 (out_linear [行切] + all_reduce) | 方案二 (all2all + out_linear [不切分]) |
|---|---|---|
| 策略 | 标准行并行 (Row-Parallelism) | 张量并行 (TP) 序列并行 (SP) 转换 |
out_linear 权重 | 按行切分 (节省 内存) | 不切分/复制 (需要 倍内存) |
| 通信操作 | all_reduce (在计算之后) | all2all (在计算之前) |
| 通信内容 | 输出 (形状 ) | 激活 (形状 ) |
| 输出 的排布 | 复制的 (Replicated) | 按序列切分 (Sequence-Parallel) |
结论:方案二牺牲了 的内存(现在需要 份 ),来换取将并行维度从 (TP) 切换到 (SP),其主要手段是用 all2all 替代 all_reduce,并利用通信-计算重叠来提升流水线效率。
三、通信量对比分析¶
通信量是决定这两种方案性能的关键因素。我们来详细分析一下,假设:
- = GPU 数量 (TP 规模)
- = 隐藏层维度
- = 数据类型大小 (例如
bfloat16为 2 字节)
3.1 方案一:out_linear (行切) + all_reduce¶
- 目标:计算 并将 分发回所有 GPU。
- 通信对象:张量 ,其大小为 。
- 通信量分析:
- 在标准的
ring-allreduce中,每个 GPU 在 步中发送数据,在 步中接收数据。 - 为了完成求和与分发,每个 GPU 最终发送的总数据量约为 ,接收的总数据量也约为 。
- 每 GPU 的总通信量 (发送+接收):
- 在标准的
3.2 方案二:all2all + out_linear (不切分)¶
- 目标:将 的切分方式从 维度 (TP) 转换为 维度 (SP)。
- 通信对象:张量 ,其大小为 。
- 通信量分析:
-
all2all操作中,每个 GPU 将其本地的 (形状 ) 切分为 块,每块 (形状 )。 -
GPU 将 块发送给其他 个 GPU。
-
GPU 发送的总数据量为:。
-
同理,它也接收 块。
-
每 GPU 的总通信量 (发送+接收):
-
对比¶
| 方案 | 通信操作 | 每 GPU 总通信量 ( V ) |
|---|---|---|
| 方案一 | all_reduce | |
| 方案二 | all2all |
得出:。因此,方案二 (**all2all**) 在通信总量上具有明显优势。
除此之外,选择方案二还有其他的原因:
- 通信模式:
all_reduce包含计算(Sum),而all2all只是数据交换(Transpose)。在某些硬件拓扑(如 NVLink Switch)上,all2all几乎可以达到线速,效率极高。 - 通信重叠:方案二的
all2all作用于 ,它可以在 被计算时重叠 (Overlap) 进行。方案一的all_reduce必须等待out_linear计算 完成后才能开始。 - 内存代价:方案二的优势是有代价的。它需要每个 GPU 都存储完整的
out_linear权重 ,而方案一只需要 的权重。 - 序列并行 (SP):如果你的网络架构(例如 MoE EP 并行)被优化为在序列并行的输入上工作,那么方案二的输出( 按序列切分)可以直接喂给下一层,完全消除了后续对 进行
all_reduce或allgather的需求。
四、EP 并行的 MoE 层¶
无论选择方案一还是方案二,进入 MoE 层时激活都已处于序列并行(SP)的排布——每张 GPU 持有全局序列的 片段,形状为 。EP 的核心思想是将专家参数分片到各 GPU,同时通过两次 all2all 完成 token 的路由与聚合,以此避免所有 GPU 都冗余存储全量专家权重。
4.1 假设一些参数:¶
- 输入:
- Router:为每个 token 选 个专家(Top-k),得到
- 专家索引:
- 权重:
- 专家集合:共有 个 experts
- EP 规模:(同一个 EP group 中有 张 GPU)
- 每张 GPU 持有 个 experts(参数分片)
两次 all2all****(Dispatch / Combine):
EP 的本质是:按专家维度切参数,但按 token 路由把激活在卡间重排。因此每个 MoE 层固定两次集合通信。
- Dispatch:把 token 送到“持有目标专家”的 GPU
- Combine:把专家输出送回“token 所在的 GPU”,并按权重聚合
MoE 输入的 SP 排布:
- 全局 个 tokens,被 张 GPU 按序列维度均分
- GPU 拥有:
- 每个 GPU 本地计算 Router:
4.2 Dispatch:permute + all2all(把 token 发到专家所在卡)¶
目标:将 token 从“按序列切分”的排布,变换为“按专家分桶并落在对应 GPU”的排布。
本地分桶(bucketize)/ 打包(pack):
- 对 GPU 上的每个 token ,它会被路由到 个专家:
- 定义专家到 GPU 的映射(静态):
- GPU 将其本地 token 复制出 份“token-expert 关联样本”,并按 分桶:
- 形成 个发送缓冲区:
- 同时,GPU 记录两类索引用于还原:
src_slot:这个样本来自本地第几个 tokenk_slot:这是 top-k 的第几路(用于乘权重)
第一次all2all:
- 所有 GPU 同时执行
all2all,
Dispatch 后的数据排布:
- GPU 得到按其本地 experts 分桶后的激活集合:
- 其中 是路由到 GPU 的(token, expert)样本数(一般不均匀)。
- 同时携带对应的还原元信息(如
src_slot / k_slot、以及回传路由所需的 index)。
关键状态:Dispatch 后,激活不再保持原序列顺序,而是按专家分桶组织,便于专家侧批处理。
4.3 Experts:本地 grouped_gemm(只在持有的专家上算)¶
GPU 持有专家集合,每个专家是一个 FFN:
- Expert 的参数:
- 对属于该专家的子 batch:
- 局部计算:
将所有专家输出拼接为:
- (与 一一对应)
4.4 Combine:all2all + unpermute + weighted_sum(送回并聚合)¶
目标:把专家输出返回到 token 的原属 GPU,并将 top-k 多路输出按权重聚合为一个 token 输出。
按来源 GPU 反向打包(pack-back):
- Dispatch 时每个样本带有其“来源 GPU + 来源 token 位置(src_slot)+ k_slot”
- GPU 将 按来源 GPU 分桶:
- 形成
第二次 all2all:
- 所有 GPU 同时执行
all2all,GPU 收到所有返回样本集合
本地还原与加权聚合:
- GPU 对其本地每个 token ,收集来自 路的返回输出
- 按 router 权重聚合:
Combine 后的输出排布:
- GPU 得到:
- 输出仍是按序列维度切分(SP),可直接送入下一层。
五、全局数据流回顾¶
将各阶段的排布变化串联起来,便能看清整条流水线的”数据拓扑”:
| 阶段 | 数据排布 | 通信 |
|---|---|---|
qkv_linear 输入 | 序列切分 (SP), | — |
qkv_linear 输出(列并行) | 隐藏维切分 (TP), | 无(本地计算) |
方案一 out_linear(行并行)输出 | 全量复制, | all_reduce |
| → Slice 为 SP | 序列切分, | 本地切片 |
方案二 all2all 后 | 序列切分 (SP), | all2all |
→ out_linear(完整权重)输出 | 序列切分, | 无 |
MoE Dispatch all2all | 专家分桶,(不均匀) | all2all |
Expert grouped_gemm | 专家分桶, | 无(本地计算) |
MoE Combine all2all | 序列切分, | all2all |
可以看到:两条路径都将 Attention 层的 TP 激活”归还”为 SP,从而 MoE 层可以无缝地以序列并行为接口完成 EP 路由,整个前向过程不需要任何额外的同步等待(在理想的通信-计算重叠实现下)。
六、总结¶
- 方案一(行并行 +
all_reduce):实现简单,权重内存占用低(),但all_reduce必须在out_linear完成后才能发起,难以与计算重叠。 - 方案二(
all2all+ 完整权重):通信量降为方案一的 ,且all2all可与前一步计算重叠;代价是每张 GPU 需存储完整的out_linear权重。当 GPU 显存充裕、NVLink 带宽高、且下游对 SP 排布有明确需求时(如接 EP-MoE),方案二的优势更为突出。 - EP 的 MoE 层:以 SP 排布为接口,两次
all2all完成 Dispatch 与 Combine,实现专家参数的分片存储与正确的 token 路由,输出依然是 SP,可无缝接入下一 Transformer 层。
三者的联动使得超大规模 MoE 模型(如 DeepSeek、Mixtral 等)在多机多卡场景中既能充分利用 NVLink/IB 带宽,又能将每卡的参数与激活内存控制在可接受范围内。