一、写在前面¶
这篇文章试图回答一个常见但并不简单的问题:做大模型 RL(尤其是 RLHF / RLVR / Reasoning RL)时,RL Infra 工程师到底需要理解哪些核心概念,为什么需要理解它们,它们在工程系统里又分别落在哪些模块中?
如果只从算法论文角度看,常见词汇会很多:trajectory、reward、advantage、importance sampling、KL、entropy、PPO、GRPO、RLOO、reference policy、old policy、rollout、trainer、mask、MoE routing、R3、KSM……
如果只从工程实现角度看,代码里又会出现另一批词:actor、critic、reference model、reward model、rollout buffer、logprob、ratio、valid mask、sampling mask、routing topk_ids、sequence packing、padding、truncate、off-policy、clipfrac、entropy collapse、train-inference mismatch……
这些名词如果孤立看,很容易”每个词都认识,但整体不成系统”。
本文会按 “一条样本从 rollout 产生,到 trainer 重算 logprob,再到构造 loss 反向传播” 的顺序,把这些概念串起来。重点不是堆术语,而是把下面三件事讲清楚:
- 每个概念在解决什么问题
- 它在训练链路中的位置是什么
- RL Infra 工程师在实现和排查时应该关注什么
工程标注约定:本文所有工程解读均基于两个开源 RL 训练框架的真实源码—— slime/main-286750aa3ef4d298995ce76e3b1cf1349efe3788 和 verl/main-866a1eaa55e3f33045ea1ca93fb24c2ee02e38f3。两者在架构设计上有差异,但核心概念的工程映射高度一致,对照阅读可以更深入理解每个概念的通用性和实现差异。
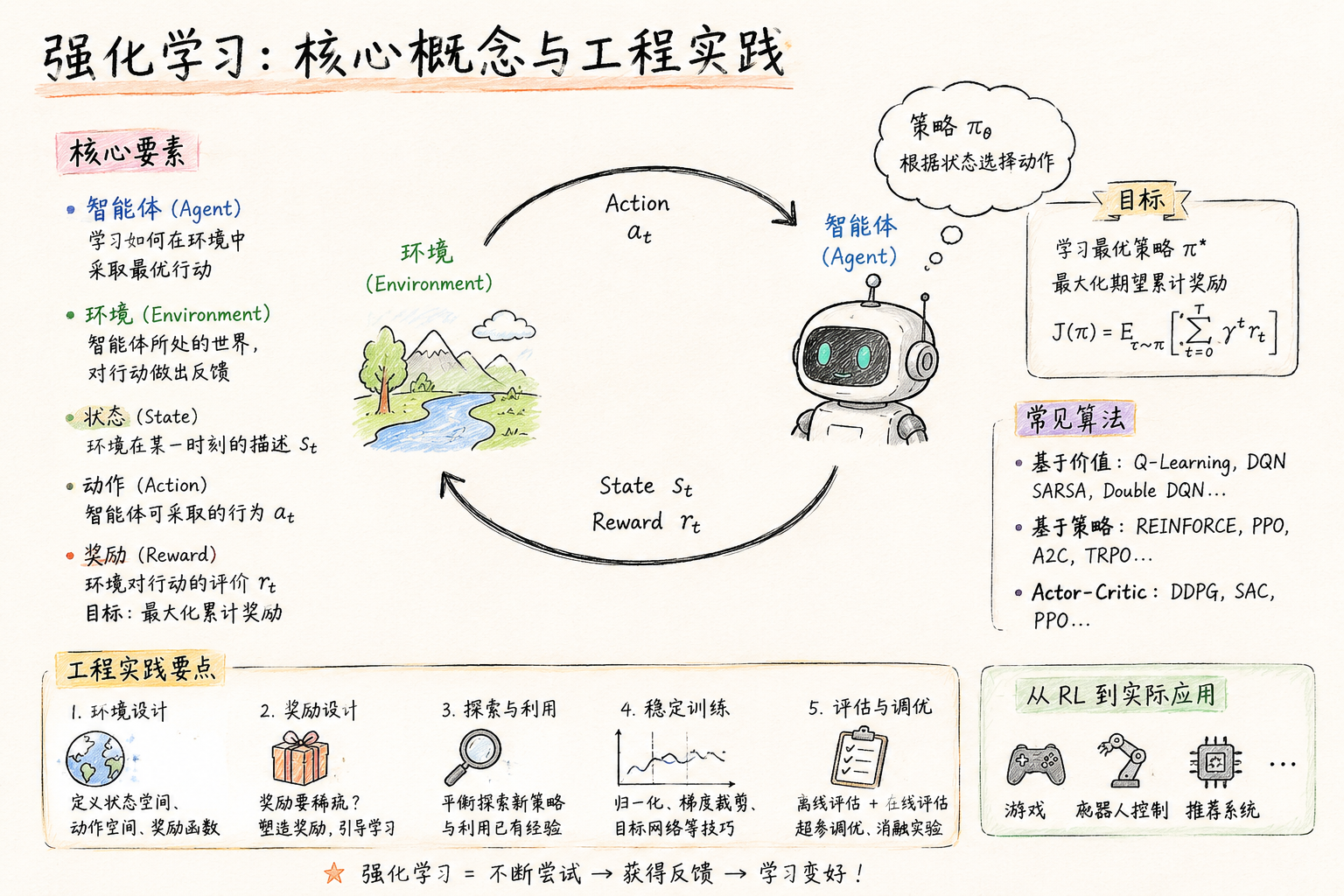
二、先建立全局图景:RL 训练链路到底在做什么¶
在监督微调(SFT)里,训练目标很直接:给定 prompt 和 target token,最大化 target 的 likelihood。
但在 RL 里,训练目标变成了:
让模型更倾向于生成”高回报”的行为轨迹,而不仅仅是拟合某个固定答案。
因此,RL 系统通常会至少拆成两段:
- Rollout / Actor 侧:负责生成样本
- Trainer 侧:负责用这些样本构造 RL loss 并更新模型
对大模型而言,一条完整链路通常是:
- 给定 prompt
- rollout 模型逐 token 或逐 step 生成输出
- 记录采样时的各种信息(token、logprob、mask、必要时还包括 MoE routing 信息)
- 用规则器 / judge / reward model 对输出打分
- trainer 读取样本,重算当前策略下的 logprob / ratio / KL / entropy
- 构造 policy loss(可选 value loss、KL loss、entropy bonus)
- 反向传播并更新参数
你可以把 RL Infra 理解为:
让这条链路既正确、又高效、又稳定地跑起来的系统工程。
2.1 工程实现解读:完整训练链路在代码中长什么样¶
在 verl 中,这条完整链路体现在 RayPPOTrainer 的主训练循环中(verl/trainer/ppo/ray_trainer.py):
for batch in train_dataloader:
# 1. Rollout: 生成序列
rollout_data = actor_rollout_worker.generate_sequences(prompts)
# 2. 计算 reward
reward_data = reward_manager(rollout_data)
# 3. 提取 ref logprobs(若使用 KL)
ref_logprobs = ref_policy_worker.compute_log_prob(rollout_data)
# 4. 计算 advantage
data = compute_advantage(data, adv_estimator=config.adv_estimator, ...)
# 5. 训练 critic(若启用)
critic_metrics = critic_worker.update_critic(data)
# 6. 训练 actor
actor_metrics = actor_worker.update_policy(data)for batch in train_dataloader:
# 1. Rollout: 生成序列
rollout_data = actor_rollout_worker.generate_sequences(prompts)
# 2. 计算 reward
reward_data = reward_manager(rollout_data)
# 3. 提取 ref logprobs(若使用 KL)
ref_logprobs = ref_policy_worker.compute_log_prob(rollout_data)
# 4. 计算 advantage
data = compute_advantage(data, adv_estimator=config.adv_estimator, ...)
# 5. 训练 critic(若启用)
critic_metrics = critic_worker.update_critic(data)
# 6. 训练 actor
actor_metrics = actor_worker.update_policy(data)在 slime 中,同样的链路体现在 MegatronTrainRayActor.train_actor()(slime/backends/megatron_utils/actor.py):
# 1. 获取 rollout 数据(从 RolloutBuffer 中读取)
rollout_data = self._get_rollout_data()
# 2. 计算 ref logprobs(若 KL 开启)
ref_log_probs = forward_ref_model(rollout_data)
# 3. 计算 current policy logprobs
log_probs = forward_actor(rollout_data)
# 4. 计算 advantage 和 returns
compute_advantages_and_returns(args, rollout_data)
# 5. 训练 actor(内部调用 policy_loss_function)
train(rollout_data)# 1. 获取 rollout 数据(从 RolloutBuffer 中读取)
rollout_data = self._get_rollout_data()
# 2. 计算 ref logprobs(若 KL 开启)
ref_log_probs = forward_ref_model(rollout_data)
# 3. 计算 current policy logprobs
log_probs = forward_actor(rollout_data)
# 4. 计算 advantage 和 returns
compute_advantages_and_returns(args, rollout_data)
# 5. 训练 actor(内部调用 policy_loss_function)
train(rollout_data)两条链路的核心步骤完全对齐:rollout → reward → logprob 重算 → advantage → loss → 反向传播。
三、什么是轨迹(Trajectory)¶
3.1 RL 里的轨迹¶
在经典 RL 里,一条轨迹通常写成:
其中:
- (s_t):时刻 (t) 的状态
- (a_t):时刻 (t) 的动作
- (r_t):执行动作后得到的奖励
模型(策略)要做的是最大化高质量轨迹出现的概率。
3.2 LLM 里的轨迹¶
映射到大模型场景:
- state:当前可见上下文(prompt + 已生成 token)
- action:当前时刻生成的 token,或者 agent 场景中的一步工具调用 / 决策
- trajectory:整段回答、整条 reasoning chain、或者一次多轮交互
因此,一次大模型回答,本质上就是一条轨迹。
3.3 为什么 RL Infra 工程师要关心”轨迹”¶
因为你后面所有的训练对象——reward、advantage、logprob、ratio、loss——都是围绕轨迹构造的。
如果你连”系统里一条样本的最小训练单位是什么”都没有定义清楚,那么:
- buffer 怎么存不清楚
- mask 应该对齐到 token、step 还是 sequence 不清楚
- reward 分配给谁不清楚
- loss 统计口径会混乱
所以很多工程问题,表面上是 “loss 不稳定 / KL 爆了 / ratio 很怪”,本质上往往是:轨迹定义和切分方式不清晰。
3.4 工程实现解读:轨迹在代码里长什么样¶
在 slime 中,一条轨迹的最小单位是 Sample 数据类(slime/utils/types.py):
@dataclass
class Sample:
tokens: list[int] = field(default_factory=list) # prompt + response token ids
response: str = "" # 生成的文本
response_length: int = 0 # response 部分的长度
reward: float | dict[str, Any] | None = None # 标量 reward 或多维 reward 字典
loss_mask: list[int] | None = None # 每个 token 的 0/1 mask
rollout_log_probs: list[float] | None = None # rollout 时记录的 log 概率
rollout_routed_experts: list[list[int]] | None = None # MoE 路由信息(R3 用)
teacher_log_probs: list[float] | None = None # 蒸馏场景下教师模型的 log 概率@dataclass
class Sample:
tokens: list[int] = field(default_factory=list) # prompt + response token ids
response: str = "" # 生成的文本
response_length: int = 0 # response 部分的长度
reward: float | dict[str, Any] | None = None # 标量 reward 或多维 reward 字典
loss_mask: list[int] | None = None # 每个 token 的 0/1 mask
rollout_log_probs: list[float] | None = None # rollout 时记录的 log 概率
rollout_routed_experts: list[list[int]] | None = None # MoE 路由信息(R3 用)
teacher_log_probs: list[float] | None = None # 蒸馏场景下教师模型的 log 概率在 verl 中,对应的数据结构是 DataProto.batch(verl/protocol.py),核心字段包括:
batch = {
"input_ids": (bs, seq_len), # prompt + response token ids
"responses": (bs, response_len), # response 部分
"attention_mask": (bs, seq_len), # 注意力 mask
"old_log_probs": (bs, response_len), # rollout 时的 log 概率
"ref_log_prob": (bs, response_len), # 参考模型的 log 概率
"token_level_scores": (bs, response_len), # 逐 token reward
"values": (bs, response_len), # critic 估值
"advantages": (bs, response_len), # 计算后的 advantage
"response_mask": (bs, response_len), # response token 的 mask
}batch = {
"input_ids": (bs, seq_len), # prompt + response token ids
"responses": (bs, response_len), # response 部分
"attention_mask": (bs, seq_len), # 注意力 mask
"old_log_probs": (bs, response_len), # rollout 时的 log 概率
"ref_log_prob": (bs, response_len), # 参考模型的 log 概率
"token_level_scores": (bs, response_len), # 逐 token reward
"values": (bs, response_len), # critic 估值
"advantages": (bs, response_len), # 计算后的 advantage
"response_mask": (bs, response_len), # response token 的 mask
}核心区别在于:slime 使用变长 list 表示每条样本(适配 Megatron 的 sequence packing),verl 使用 padding 后的 2D Tensor(适配 FSDP 的 batch 并行)。但两者承载的信息本质一致:token ids + logprob + reward + mask = 一条完整的 RL 轨迹。
四、什么是轨迹拆分(Trajectory Splitting)¶
4.1 为什么要拆分¶
实际训练中,我们通常拿到的是一条完整输出,但训练并不是只在 sequence 粒度上做一件事就结束。
因为:
- reward 往往是序列级的,例如一整题答对/答错
- 训练更新却往往是 token 级的,因为 logprob 是逐 token 计算的
- 某些 agent / reasoning 场景下,还会有 step / turn 级 评价
于是就需要把”整条轨迹”拆成适合训练的更细粒度单元。
4.2 常见拆法¶
- Sequence-level:一条回答作为一个训练单元
- Token-level:每个 token 都有自己的 logprob、ratio、mask
- Step-level:一个 reasoning step、一个工具调用、一个子任务作为单元
- Turn-level:多轮 agent 交互中,一轮为一个单元
4.3 轨迹拆分的本质:Credit Assignment¶
轨迹拆分真正要解决的问题叫 Credit Assignment(归因)。
也就是:
最终 reward 到底应该归功于哪些局部动作?
例如:
- 一道数学题最后答对了,究竟是哪个中间步骤起了关键作用?
- 一个 agent 最终完成了任务,究竟是哪个工具调用最重要?
- 一条长回答被判为”高质量”,到底应该提升哪些 token 的概率?
如果不做合理的 credit assignment,就会出现两种极端:
- 过粗:整条序列共享同一个 reward,训练信号太糙
- 过细但错误:局部归因不准确,导致奖励噪声更大
4.4 工程上常见的轨迹拆分操作¶
对 RL Infra 工程师来说,轨迹拆分往往对应这些具体动作:
- 只对 response token 而不是 prompt token 计算 loss
- 通过
valid_mask/response_mask过滤 padding 和无效位置 - 对 sequence-level reward 构造 token-level advantage
- 对多轮对话,决定是把整个对话展开成一条长序列,还是按 turn 切分
- 对 reasoning 场景,决定中间”思维过程”是否参与 reward / loss
4.5 工程实现解读:Loss Mask 如何实现多轮对话的轨迹拆分¶
slime 中专门实现了 MultiTurnLossMaskGenerator(slime/utils/mask_utils.py)来处理多轮对话的轨迹拆分。它的核心思想是:只对 assistant 的 response token 计算 loss,user/system 的 token 全部 mask 掉:
class MultiTurnLossMaskGenerator:
def gen_multi_turn_loss_mask_qwen(self, messages, tools=None):
for i, message in enumerate(messages):
# ...tokenize each message...
if message["role"] == "assistant":
# assistant 回复:前面的角色标记 mask=0,内容部分 mask=1
loss_mask = [0] * self.gen_token_length + [1] * (len(message_ids) - self.gen_token_length)
else:
# user/system 消息:全部 mask=0
loss_mask = [0] * len(message_ids)
# 支持通过 step_loss_mask 字段手动禁用某些 step 的训练
if message.get("step_loss_mask", 1) != 1:
loss_mask = [0] * len(message_ids)class MultiTurnLossMaskGenerator:
def gen_multi_turn_loss_mask_qwen(self, messages, tools=None):
for i, message in enumerate(messages):
# ...tokenize each message...
if message["role"] == "assistant":
# assistant 回复:前面的角色标记 mask=0,内容部分 mask=1
loss_mask = [0] * self.gen_token_length + [1] * (len(message_ids) - self.gen_token_length)
else:
# user/system 消息:全部 mask=0
loss_mask = [0] * len(message_ids)
# 支持通过 step_loss_mask 字段手动禁用某些 step 的训练
if message.get("step_loss_mask", 1) != 1:
loss_mask = [0] * len(message_ids)注意这里的 step_loss_mask 字段——它允许在 agent 场景中精确控制哪些 reasoning step 参与训练。例如,在多轮 tool-call 场景中,可以只对最终回答计算 loss,而屏蔽中间的工具调用步骤。
对于 Qwen3.5 等较新的模型,还实现了基于字符偏移的精确 mask 生成(gen_multi_turn_loss_mask_qwen3_5),甚至会自动跳过 <think> 标签内的思考过程:
# Qwen3.5: 跳过 <think>...</think> 区域
if rendered_text[content_start:content_start + len(think_prefix)] == think_prefix:
mask_start = content_start + len(think_prefix) # 从 think 结束后开始 mask=1# Qwen3.5: 跳过 <think>...</think> 区域
if rendered_text[content_start:content_start + len(think_prefix)] == think_prefix:
mask_start = content_start + len(think_prefix) # 从 think 结束后开始 mask=1在 verl 中,response mask 的生成更加简洁,直接基于 EOS token 位置(verl/utils/torch_functional.py):
def get_response_mask(response_id, eos_token=2):
"""1 for tokens up to (and including) EOS, 0 after"""
eos_mask = torch.isin(response_id, torch.tensor(eos_token)).int()
return (eos_mask.cumsum(dim=1) - eos_mask).eq(0).to(dtype)def get_response_mask(response_id, eos_token=2):
"""1 for tokens up to (and including) EOS, 0 after"""
eos_mask = torch.isin(response_id, torch.tensor(eos_token)).int()
return (eos_mask.cumsum(dim=1) - eos_mask).eq(0).to(dtype)五、Reward:强化学习到底在追求什么¶
5.1 Reward 是目标信号¶
Reward 可以简单理解为:系统认为这条行为”值不值钱”的分数。
在 LLM RL 中,reward 的来源很多,例如:
- 规则匹配(答案对/错)
- 单元测试通过率
- judge model 评分
- reward model 偏好分
- 多指标加权(正确性、格式性、安全性、简洁性等)
5.2 常见 reward 形态¶
- Sequence-level reward:整段输出一个分数
- Step-level reward:中间步骤有局部打分
- Turn-level reward:多轮交互中每轮有分数
- Token-level redistributed reward:把高层 reward 再分配回 token
5.3 为什么 reward 常常不能直接拿来训练¶
因为裸 reward 通常有三个问题:
- 稀疏:只有最后一个分数
- 延迟:前面 token 的价值要到最后才显现
- 高方差:不同轨迹的 reward 抖动很大
所以工程上不会简单地”哪个样本 reward 高就直接加大概率”,而是会进一步构造 return / advantage / baseline 等量,让训练更稳定。
5.4 工程实现解读:Reward 在系统中的流转路径¶
在 slime 中,reward 的产生和消费链路如下:
1. 产生:在 rollout 阶段,generate_and_rm() 函数(slime/rollout/sglang_rollout.py)同时完成生成和打分,reward 存储在 sample.reward 字段中。slime 支持将自定义 reward 函数通过 --custom-rm-path 注入。
2. 消费:在训练阶段,reward 被读出并和 KL penalty 结合后送入 advantage 计算。以 PPO 为例(slime/backends/megatron_utils/loss.py 中的 compute_advantages_and_returns):
# PPO: 把 KL 惩罚项注入到 token-level reward 中
elif args.advantage_estimator == "ppo":
kl_coef = -args.kl_coef
for reward, k in zip(old_rewards, kl):
k *= kl_coef # token-level KL 惩罚
if cp_rank == 0:
k[-1] += reward # 序列级 reward 加在最后一个 token 上
rewards.append(k)
# 然后送入 GAE 计算
advantages, returns = get_advantages_and_returns_batch(...)# PPO: 把 KL 惩罚项注入到 token-level reward 中
elif args.advantage_estimator == "ppo":
kl_coef = -args.kl_coef
for reward, k in zip(old_rewards, kl):
k *= kl_coef # token-level KL 惩罚
if cp_rank == 0:
k[-1] += reward # 序列级 reward 加在最后一个 token 上
rewards.append(k)
# 然后送入 GAE 计算
advantages, returns = get_advantages_and_returns_batch(...)可以看到一个非常关键的设计细节:sequence-level reward 被放到了最后一个 response token 的位置上(k[-1] += reward),前面所有 token 只承担 KL 惩罚信号。这正是经典 PPO 中处理稀疏、延迟 reward 的标准做法——通过 GAE 将末尾的 reward 信号沿时间维度反向传播,自然实现 credit assignment。
在 verl 中,reward 的注入方式更灵活,通过 apply_kl_penalty 函数(verl/trainer/ppo/ray_trainer.py)统一处理:
def apply_kl_penalty(data, kl_ctrl, kl_penalty="kl"):
kld = core_algos.kl_penalty(data.batch["old_log_probs"], data.batch["ref_log_prob"], ...)
kld = kld * response_mask
beta = kl_ctrl.value
# 核心:token_level_rewards = 原始 reward - β * KL
token_level_rewards = token_level_scores - beta * klddef apply_kl_penalty(data, kl_ctrl, kl_penalty="kl"):
kld = core_algos.kl_penalty(data.batch["old_log_probs"], data.batch["ref_log_prob"], ...)
kld = kld * response_mask
beta = kl_ctrl.value
# 核心:token_level_rewards = 原始 reward - β * KL
token_level_rewards = token_level_scores - beta * kld这里使用了 Adaptive KL Controller:一个 PID 控制风格的自适应系数调节器,会根据当前 KL 是否偏离目标值来动态调整 β:
class AdaptiveKLController:
def update(self, current_kl, n_steps):
proportional_error = np.clip(current_kl / self.target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.horizon
self.value *= multclass AdaptiveKLController:
def update(self, current_kl, n_steps):
proportional_error = np.clip(current_kl / self.target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.horizon
self.value *= mult这个设计来自 InstructGPT 论文,目标是让 KL 惩罚系数不需要手动调,而是自动适应训练动态。
六、Advantage、Baseline、Return:Reward 进入 Loss 前要经历什么¶
6.1 Return¶
Return 可以理解为”从当前位置开始,未来能拿到的累计回报”。
在最简单的序列级任务里,如果整条回答最后只给一个总分,那么每个 response token 可能都共享同一个 return,或者共享这个总分的某种变体。
6.2 Baseline¶
Baseline 是一个”正常情况下大概能拿多少分”的参考值。
为什么要减 baseline?
因为策略梯度如果直接用裸 reward,方差很大,训练容易抖。减去 baseline 后,模型学的不是”它好不好”,而是”它比预期好多少 / 差多少”。
6.3 Advantage¶
Advantage 是 RL 里极其核心的概念。它表达的是:
这个动作相对于基线,有没有额外价值。
直觉上:
- advantage > 0:这个动作比平均水平更好,应该提高概率
- advantage < 0:这个动作比平均水平更差,应该降低概率
6.4 在 LLM 里,advantage 通常长什么样¶
不同算法会有不同构造方式:
- PPO:通常借助 critic / value function 构造 advantage
- RLOO:通过 leave-one-out baseline 构造 advantage
- GRPO:用 group-relative 的方式做相对比较
但无论形式如何变化,本质都一样:
训练不是直接追 reward,而是在追”相对更优的行为”。
6.5 工程实现解读:不同 Advantage 估计器的代码实现¶
工程上,advantage 估计器是 RL 训练框架中最”算法密集”的模块之一。verl 通过一个注册机制(AdvantageEstimator 枚举 + @register_adv_est 装饰器)管理十几种不同的算法(verl/trainer/ppo/core_algos.py):
class AdvantageEstimator(str, Enum):
GAE = "gae" # 经典 PPO + Critic
GRPO = "grpo" # Group Relative Policy Optimization
REINFORCE_PLUS_PLUS = "reinforce_plus_plus" # REINFORCE++ (带折扣)
REINFORCE_PLUS_PLUS_BASELINE = "reinforce_plus_plus_baseline" # REINFORCE++ 带 baseline
RLOO = "rloo" # Reward Leave-One-Out
OPO = "opo" # Optimal Policy Optimization
GRPO_PASSK = "grpo_passk" # Pass@k 变体
GPG = "gpg" # Graph Policy Gradient
OPTIMAL_TOKEN_BASELINE = "optimal_token_baseline" # 逐 token 最优 baseline
GDPO = "gdpo" # Group reward-Decoupled Normalization
# ...class AdvantageEstimator(str, Enum):
GAE = "gae" # 经典 PPO + Critic
GRPO = "grpo" # Group Relative Policy Optimization
REINFORCE_PLUS_PLUS = "reinforce_plus_plus" # REINFORCE++ (带折扣)
REINFORCE_PLUS_PLUS_BASELINE = "reinforce_plus_plus_baseline" # REINFORCE++ 带 baseline
RLOO = "rloo" # Reward Leave-One-Out
OPO = "opo" # Optimal Policy Optimization
GRPO_PASSK = "grpo_passk" # Pass@k 变体
GPG = "gpg" # Graph Policy Gradient
OPTIMAL_TOKEN_BASELINE = "optimal_token_baseline" # 逐 token 最优 baseline
GDPO = "gdpo" # Group reward-Decoupled Normalization
# ...slime 也支持多种估计器(通过 --advantage-estimator 参数切换),包括 ppo、grpo、gspo、reinforce_plus_plus、reinforce_plus_plus_baseline 等。
下面逐个解读最关键的几种实现:
GAE(Generalized Advantage Estimation)
GAE 是经典 PPO 的标配,需要 critic / value model 作为 baseline。核心递推关系:
verl 的实现(verl/trainer/ppo/core_algos.py):
def compute_gae_advantage_return(token_level_rewards, values, response_mask, gamma, lam):
with torch.no_grad():
lastgaelam = 0
for t in reversed(range(gen_len)):
delta = token_level_rewards[:, t] + gamma * nextvalues - values[:, t]
lastgaelam_ = delta + gamma * lam * lastgaelam
# 关键:用 response_mask 跳过 EOS 之后的 padding 区域
nextvalues = values[:, t] * response_mask[:, t] + (1 - response_mask[:, t]) * nextvalues
lastgaelam = lastgaelam_ * response_mask[:, t] + (1 - response_mask[:, t]) * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values
advantages = verl_F.masked_whiten(advantages, response_mask) # 白化:归零均值 + 单位方差def compute_gae_advantage_return(token_level_rewards, values, response_mask, gamma, lam):
with torch.no_grad():
lastgaelam = 0
for t in reversed(range(gen_len)):
delta = token_level_rewards[:, t] + gamma * nextvalues - values[:, t]
lastgaelam_ = delta + gamma * lam * lastgaelam
# 关键:用 response_mask 跳过 EOS 之后的 padding 区域
nextvalues = values[:, t] * response_mask[:, t] + (1 - response_mask[:, t]) * nextvalues
lastgaelam = lastgaelam_ * response_mask[:, t] + (1 - response_mask[:, t]) * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values
advantages = verl_F.masked_whiten(advantages, response_mask) # 白化:归零均值 + 单位方差slime 提供了两种 GAE 实现,普通版(vanilla_gae)逻辑一致,额外还提供了一个高性能的 Chunked GAE:
# slime/utils/ppo_utils.py - chunked_gae
# 灵感来自 FlashLinearAttention:chunk 内并行前缀扫描,chunk 间递推
# 将 O(T) 的逐步递推降到 O(T/chunk_size) 的顺序依赖
# 构建 chunk 内的并行扫描核 M
# M[i,j] = w^(j-i) if j >= i else 0, where w = γλ
M = torch.zeros(chunk_size, chunk_size)
M[mask] = w ** diff[mask].to(dtype)
# chunk 内:S_local = Δ @ M (矩阵乘法一次完成)
S_local_flat = deltas_flat @ M
# chunk 间:S_global[t] = S_local[t] + w^(t+1) * s_prev
for c in range(n_chunks):
S_global = S_local + s_prev.unsqueeze(1) * pow_vec[:Lc]
s_prev = S_global[:, -1]# slime/utils/ppo_utils.py - chunked_gae
# 灵感来自 FlashLinearAttention:chunk 内并行前缀扫描,chunk 间递推
# 将 O(T) 的逐步递推降到 O(T/chunk_size) 的顺序依赖
# 构建 chunk 内的并行扫描核 M
# M[i,j] = w^(j-i) if j >= i else 0, where w = γλ
M = torch.zeros(chunk_size, chunk_size)
M[mask] = w ** diff[mask].to(dtype)
# chunk 内:S_local = Δ @ M (矩阵乘法一次完成)
S_local_flat = deltas_flat @ M
# chunk 间:S_global[t] = S_local[t] + w^(t+1) * s_prev
for c in range(n_chunks):
S_global = S_local + s_prev.unsqueeze(1) * pow_vec[:Lc]
s_prev = S_global[:, -1]这个 chunked GAE 借鉴了 FlashLinearAttention 的思想:将长序列切成 chunk,chunk 内用矩阵乘法并行完成递推扫描(O(C²) per chunk),chunk 间只传递一个标量状态。这把时间复杂度从 O(T) 降到了 O(T/C + C²),对长序列 RL(如 reasoning 任务动辄几千 token)有显著的加速效果。
GRPO(Group Relative Policy Optimization)
GRPO 不需要 critic,而是通过同一 prompt 的多条回答之间的 reward 对比来构造 advantage。verl 的实现(verl/trainer/ppo/core_algos.py):
def compute_grpo_outcome_advantage(token_level_rewards, response_mask, index, ...):
scores = token_level_rewards.sum(dim=-1) # 序列级总 reward
# 按 prompt 分组
for i in range(bsz):
id2score[index[i]].append(scores[i])
# 组内统计
for idx in id2score:
id2mean[idx] = torch.mean(torch.stack(id2score[idx]))
id2std[idx] = torch.std(torch.stack(id2score[idx]))
# 组内标准化 → advantage
for i in range(bsz):
scores[i] = (scores[i] - id2mean[index[i]]) / (id2std[index[i]] + epsilon)
# 广播到所有 response token
scores = scores.unsqueeze(-1) * response_maskdef compute_grpo_outcome_advantage(token_level_rewards, response_mask, index, ...):
scores = token_level_rewards.sum(dim=-1) # 序列级总 reward
# 按 prompt 分组
for i in range(bsz):
id2score[index[i]].append(scores[i])
# 组内统计
for idx in id2score:
id2mean[idx] = torch.mean(torch.stack(id2score[idx]))
id2std[idx] = torch.std(torch.stack(id2score[idx]))
# 组内标准化 → advantage
for i in range(bsz):
scores[i] = (scores[i] - id2mean[index[i]]) / (id2std[index[i]] + epsilon)
# 广播到所有 response token
scores = scores.unsqueeze(-1) * response_mask直觉上:同一题出了 5 条回答,得分排名高的得正 advantage,排名低的得负 advantage。不需要 critic model,用”组内相对排名”代替了 value baseline。
RLOO(Reward Leave-One-Out)
RLOO 是 GRPO 的一个变体,baseline 使用 leave-one-out 均值,避免了样本自身参与 baseline 计算导致的偏差:
def compute_rloo_outcome_advantage(token_level_rewards, response_mask, index, ...):
for i in range(bsz):
response_num = len(id2score[index[i]])
if response_num > 1:
# leave-one-out: 用 (N*mean - self) / (N-1) 作为 baseline
scores[i] = scores[i] * response_num / (response_num - 1) \
- id2mean[index[i]] * response_num / (response_num - 1)def compute_rloo_outcome_advantage(token_level_rewards, response_mask, index, ...):
for i in range(bsz):
response_num = len(id2score[index[i]])
if response_num > 1:
# leave-one-out: 用 (N*mean - self) / (N-1) 作为 baseline
scores[i] = scores[i] * response_num / (response_num - 1) \
- id2mean[index[i]] * response_num / (response_num - 1)REINFORCE++ 与 REINFORCE++-baseline
slime 实现了 REINFORCE++(slime/utils/ppo_utils.py 中的 get_reinforce_plus_plus_returns),其核心特点是在 token-level 上做折扣 return 计算,而不是简单地把 sequence reward 广播到所有 token:
# REINFORCE++: 逐 token 折扣 return,包含 KL 惩罚
token_level_rewards = -kl_coef * masked_kl
last_idx = full_mask.nonzero(as_tuple=True)[0][-1]
token_level_rewards[last_idx] += rewards[i] # reward 加在最后一个有效 token
# 逆序递推折扣 return
for t in reversed(range(token_level_rewards.size(0))):
running_return = token_level_rewards[t] + gamma * running_return
returns_for_seq[t] = running_return# REINFORCE++: 逐 token 折扣 return,包含 KL 惩罚
token_level_rewards = -kl_coef * masked_kl
last_idx = full_mask.nonzero(as_tuple=True)[0][-1]
token_level_rewards[last_idx] += rewards[i] # reward 加在最后一个有效 token
# 逆序递推折扣 return
for t in reversed(range(token_level_rewards.size(0))):
running_return = token_level_rewards[t] + gamma * running_return
returns_for_seq[t] = running_returnOptimal Token Baseline(OTB)
这是 verl 中一种先进的逐 token baseline 方法(verl/trainer/ppo/core_algos.py),它利用了策略分布的 path-variance proxy 来计算最优 baseline:
# OTB: per-timestep 最优 baseline,最小化方差
pi_t = torch.exp(old_log_probs)
w_per_timestep = 1 - 2 * pi_t + sum_pi_squared # path-variance proxy
w_cumulative = (w_per_timestep * response_mask).cumsum(dim=-1)
# 在组内计算最优 baseline:B_t* = Σ(G_t × W_t) / Σ(W_t)
b_star = (R_group * w_group).sum(dim=0) / (w_group.sum(dim=0) + epsilon)# OTB: per-timestep 最优 baseline,最小化方差
pi_t = torch.exp(old_log_probs)
w_per_timestep = 1 - 2 * pi_t + sum_pi_squared # path-variance proxy
w_cumulative = (w_per_timestep * response_mask).cumsum(dim=-1)
# 在组内计算最优 baseline:B_t* = Σ(G_t × W_t) / Σ(W_t)
b_star = (R_group * w_group).sum(dim=0) / (w_group.sum(dim=0) + epsilon)七、重要性采样(Importance Sampling, IS):为什么要看概率比¶
7.1 旧策略采样,新策略训练¶
RL 里有一个关键现实:
- rollout 样本是由 旧策略 / 行为策略 采出来的
- trainer 更新时用的是 当前策略
问题来了:
你怎么用”旧策略采出来的数据”,去估计”当前策略下的优化目标”?
这就需要重要性采样。
7.2 核心量:Importance Ratio¶
最关键的量是 。
它表示:
- 当前策略相对旧策略,对该动作更偏好多少
- 或者更不偏好多少
7.3 直觉理解¶
如果 rollout 时某个 token 是由旧策略采样出来的,而当前策略对这个 token 的概率更高,那么这个 token 在当前策略视角下”更合理”;反之,如果当前策略对这个 token 概率变低,它就更像一个”旧样本”。
7.4 为什么 IS 会导致不稳定¶
因为 ratio 可能非常大。尤其是:
- reward 稀疏时
- 策略更新太快时
- 训推不一致时
- 采样 support 不一致时
都可能导致 ratio 长尾、方差大、梯度很噪。
7.5 PPO 为什么要 clip¶
PPO 的经典做法,就是不让 ratio 带来的更新无限放大,而是通过 clipping 限制每次策略更新的幅度。
因此,PPO 的稳定性很大程度上来自:
不是不做大步更新,而是拒绝被少量极端 ratio 样本劫持。
7.6 RL Infra 工程师需要看哪些 IS 相关指标¶
常见包括:
- ratio 的均值 / 方差
- clipfrac(有多少样本被 clip)
- 是否存在极端长尾 token
- old logprob 与 current logprob 的差分分布
- 有效样本比例
很多”训练突然发散”的表象,最终都能在 ratio 分布里看到征兆。
7.7 工程实现解读:Ratio 计算与 PPO Clip 的代码实现¶
基础 ratio + clip 实现
slime 的实现(slime/utils/ppo_utils.py 中的 compute_policy_loss)非常精炼:
@torch.compile(dynamic=True)
def compute_policy_loss(ppo_kl, advantages, eps_clip, eps_clip_high, eps_clip_c=None):
ratio = (-ppo_kl).exp() # ppo_kl = old_logprob - new_logprob, 所以 ratio = exp(new - old)
pg_losses1 = -ratio * advantages # 无 clip 项
pg_losses2 = -ratio.clamp(1 - eps_clip, 1 + eps_clip_high) * advantages # clip 项
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2)
clipfrac = torch.gt(pg_losses2, pg_losses1).float()
# Dual-clip PPO: 对负 advantage 做额外的下界 clip
if eps_clip_c is not None:
pg_losses3 = -eps_clip_c * advantages
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1)
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)
else:
pg_losses = clip_pg_losses1@torch.compile(dynamic=True)
def compute_policy_loss(ppo_kl, advantages, eps_clip, eps_clip_high, eps_clip_c=None):
ratio = (-ppo_kl).exp() # ppo_kl = old_logprob - new_logprob, 所以 ratio = exp(new - old)
pg_losses1 = -ratio * advantages # 无 clip 项
pg_losses2 = -ratio.clamp(1 - eps_clip, 1 + eps_clip_high) * advantages # clip 项
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2)
clipfrac = torch.gt(pg_losses2, pg_losses1).float()
# Dual-clip PPO: 对负 advantage 做额外的下界 clip
if eps_clip_c is not None:
pg_losses3 = -eps_clip_c * advantages
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1)
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)
else:
pg_losses = clip_pg_losses1注意三个工程细节:
@torch.compile(dynamic=True)编译加速eps_clip和eps_clip_high可以不对称——上界和下界可以分别设置- 支持 Dual-clip PPO(
eps_clip_c):对负 advantage 样本增加一个额外的下界 clip,防止概率被降得太多
verl 的 vanilla PPO 实现逻辑一致(verl/trainer/ppo/core_algos.py),但增加了一个重要的数值稳定性处理:
negative_approx_kl = log_prob - old_log_prob
negative_approx_kl = torch.clamp(negative_approx_kl, min=-20.0, max=20.0) # 防止 exp 溢出
ratio = torch.exp(negative_approx_kl)negative_approx_kl = log_prob - old_log_prob
negative_approx_kl = torch.clamp(negative_approx_kl, min=-20.0, max=20.0) # 防止 exp 溢出
ratio = torch.exp(negative_approx_kl)这个 clamp(-20, 20) 看似简单,但极其重要——它防止了 logprob 差值过大时 exp() 产生 inf/nan,这是 RL 训练中常见的数值问题。
超越 vanilla PPO:更多 policy loss 变体
verl 提供了丰富的 policy loss 变体注册机制(@register_policy_loss 装饰器),值得了解几个工程上有显著差异的:
- DPPO-TV(Total Variation 约束):不 clip ratio 本身,而是 clip log-ratio,提供不同的分布约束几何
- GSPO(Grouped Sequence PPO):在 sequence-level 上计算 IS ratio 而不是 token-level,适合纯 outcome reward 场景
- CISPO:对 clipped ratio 使用
stop_gradient,防止梯度通过 clip 操作本身传播 - Geometric Mean PPO(GMPO):不在 token-level 上分别计算 ratio 再聚合,而是取 log-ratio 在 token 维度上求和后再 exp,得到 sequence-level 的几何平均 ratio
Off-Policy 矫正:TIS 与 ICEPOP
当 rollout 策略和 train 初始策略存在差距(异步训练场景中常见)时,slime 提供了两种 off-policy 矫正机制(slime/backends/megatron_utils/loss.py):
# TIS: Truncated Importance Sampling
def vanilla_tis_function(args, *, pg_loss, train_log_probs, rollout_log_probs, ...):
# train_log_probs: train 开始时的 logprob(第一次前向)
# rollout_log_probs: rollout 时记录的 logprob
tis = torch.exp(old_log_probs - rollout_log_probs) # IS 比值
tis_weights = torch.clamp(tis, min=args.tis_clip_low, max=args.tis_clip) # 截断
pg_loss = pg_loss * tis_weights # 加权 policy loss
# ICEPOP: 拒绝式矫正,超出范围直接置零(比截断更保守)
def icepop_function(args, *, pg_loss, train_log_probs, rollout_log_probs, ...):
ice_ratio = torch.exp(old_log_probs - rollout_log_probs)
ice_weight = torch.where(
(ice_ratio >= args.tis_clip_low) & (ice_ratio <= args.tis_clip),
ice_ratio, torch.zeros_like(ice_ratio) # 超出范围 → 权重为 0
)
pg_loss = pg_loss * ice_weight# TIS: Truncated Importance Sampling
def vanilla_tis_function(args, *, pg_loss, train_log_probs, rollout_log_probs, ...):
# train_log_probs: train 开始时的 logprob(第一次前向)
# rollout_log_probs: rollout 时记录的 logprob
tis = torch.exp(old_log_probs - rollout_log_probs) # IS 比值
tis_weights = torch.clamp(tis, min=args.tis_clip_low, max=args.tis_clip) # 截断
pg_loss = pg_loss * tis_weights # 加权 policy loss
# ICEPOP: 拒绝式矫正,超出范围直接置零(比截断更保守)
def icepop_function(args, *, pg_loss, train_log_probs, rollout_log_probs, ...):
ice_ratio = torch.exp(old_log_probs - rollout_log_probs)
ice_weight = torch.where(
(ice_ratio >= args.tis_clip_low) & (ice_ratio <= args.tis_clip),
ice_ratio, torch.zeros_like(ice_ratio) # 超出范围 → 权重为 0
)
pg_loss = pg_loss * ice_weightTIS 截断超出范围的权重到边界值,ICEPOP 更激进——直接拒绝(丢弃)off-policy 程度太大的样本。这两个机制尤其在异步训练(rollout 和 train 的策略版本差距大)时至关重要。
八、KL:为什么 RL 训练里总在说”别跑太远”¶
8.1 Reward 最大化不等于训练稳定¶
只看 reward,会出现一个问题:模型可能为了拿分,迅速偏离原本的语言分布、风格分布、能力边界,最终出现:
- 模式崩塌
- 语言质量下降
- 过度自信
- 输出越来越单一
- 训练早期 reward 虽上升,但泛化能力变差
8.2 KL 的作用¶
KL(Kullback–Leibler divergence)可以理解为”两个分布相差多远”。
在 RLHF / RLVR 中,KL 常用于约束:
- 当前策略不要离 reference policy 太远
- 当前策略不要离 old policy 变化太猛
8.3 从工程直觉上理解 KL¶
Reward 告诉你”往哪走”,KL 告诉你”别一下跳太猛”。
所以:
- reward 决定优化方向
- KL 决定更新幅度和分布稳定性
8.4 KL 在训练里怎么出现¶
常见两种方式:
- 写进 reward:高偏离就扣分
- 写进 loss:作为额外正则项
8.5 RL Infra 工程师需要关注什么¶
你要关心的不只是 “KL 大不大”,还要关心:
- 它相对谁算(old policy / ref policy / current policy)
- 是 full-vocab 的 KL 还是 masked support 上的 KL
- 是 sequence 平均、token 平均,还是只统计 response token
- 它是在值上当 metric 看,还是在梯度上当 loss 优化
这几点如果定义不清,团队里同样叫”KL”,实际说的可能根本不是同一个东西。
8.6 工程实现解读:KL 在训练中的两种出场方式¶
方式一:写进 reward(KL Penalty)
verl 的 apply_kl_penalty(verl/trainer/ppo/ray_trainer.py):
# 计算 ref policy 与 current policy 之间的 KL
kld = core_algos.kl_penalty(data.batch["old_log_probs"], data.batch["ref_log_prob"], kl_penalty=kl_penalty)
kld = kld * response_mask
beta = kl_ctrl.value
# token_level_rewards = 原始 reward - β * KL
token_level_rewards = token_level_scores - beta * kld# 计算 ref policy 与 current policy 之间的 KL
kld = core_algos.kl_penalty(data.batch["old_log_probs"], data.batch["ref_log_prob"], kl_penalty=kl_penalty)
kld = kld * response_mask
beta = kl_ctrl.value
# token_level_rewards = 原始 reward - β * KL
token_level_rewards = token_level_scores - beta * kld注意 KL 作用的对象:old_log_probs(当前策略的 logprob)vs ref_log_prob(参考策略,通常是 SFT 模型)。这里 KL 被减到了 reward 里,意味着它影响 advantage 的计算,但不直接产生梯度。
方式二:写进 loss(KL Loss)
slime 的 policy_loss_function(slime/backends/megatron_utils/loss.py):
if args.use_kl_loss:
ref_log_probs = torch.cat(batch["ref_log_probs"], dim=0)
importance_ratio = None
if args.use_unbiased_kl:
importance_ratio = torch.exp(log_probs - old_log_probs) # 无偏 KL 估计
kl = compute_approx_kl(log_probs, ref_log_probs, kl_loss_type=args.kl_loss_type,
importance_ratio=importance_ratio)
kl_loss = sum_of_sample_mean(kl)
loss = loss + args.kl_loss_coef * kl_lossif args.use_kl_loss:
ref_log_probs = torch.cat(batch["ref_log_probs"], dim=0)
importance_ratio = None
if args.use_unbiased_kl:
importance_ratio = torch.exp(log_probs - old_log_probs) # 无偏 KL 估计
kl = compute_approx_kl(log_probs, ref_log_probs, kl_loss_type=args.kl_loss_type,
importance_ratio=importance_ratio)
kl_loss = sum_of_sample_mean(kl)
loss = loss + args.kl_loss_coef * kl_loss这里 KL 被直接加入 loss,会产生梯度,直接影响参数更新方向。
两种方式的选择取决于算法设计:GRPO/REINFORCE++ 通常用方式一(KL 进 reward),PPO 两种都可以用,有的系统(如 slime)同时支持两种并允许通过 --kl-coef 和 --use-kl-loss 分别控制。
九、K3 是什么,和 KL 有什么关系¶
9.1 一个常见误区¶
很多人会把 K3 和 KL 混着说,仿佛 K3 就是 KL。
更准确地说:
K3 通常是 sampled KL estimator / surrogate 的一种形式,不等于”KL 本体”。
9.2 为什么需要 K1/K2/K3 这类 estimator¶
真实 KL 是对整个分布求期望。在大模型训练里,直接精确计算并不总是划算,尤其当你手头最直接拥有的是”采样到的动作”和”这些动作的 logprob”时,就会使用 sampled estimator 去近似 KL 或构造 KL 风格的正则项。
9.3 工程上该怎么理解 K3¶
工程师最重要的不是死记公式,而是记住下面这句话:
“K3 是训练时拿来近似 / 实现 KL 约束的一种方式;它在数值估计和梯度意义上,不一定和你心里想的’真实 KL’完全等价。”
这句话很重要,因为很多看起来”KL 值没问题”的训练,最终梯度行为未必符合预期。
9.4 你在项目里至少要问清楚这三件事¶
- 我们这里说的 K3,具体公式是什么?
- 它被当成 metric、penalty,还是直接当 loss 微分?
- 它对应的是哪个参考分布?
只要这三件事不清楚,排查问题就会非常困难。
9.5 工程实现解读:K1/K2/K3 的公式与代码对照¶
slime 的 compute_approx_kl(slime/utils/ppo_utils.py)实现了完整的 K1/K2/K3 estimator,并且附带了 Schulman blog 的引用:
@torch.compile(dynamic=True)
def compute_approx_kl(log_probs, log_probs_base, kl_loss_type, importance_ratio=None):
"""Schulman blog: http://joschu.net/blog/kl-approx.html"""
log_ratio = log_probs.float() - log_probs_base.float()
if kl_loss_type == "k1":
kl = log_ratio # K1: log(π/π_ref) = log_π - log_π_ref
elif kl_loss_type == "k2":
kl = log_ratio ** 2 / 2.0 # K2: (log(π/π_ref))² / 2
elif kl_loss_type in ["k3", "low_var_kl"]:
log_ratio = -log_ratio # 注意取反:log(π_ref/π)
kl = log_ratio.exp() - 1 - log_ratio # K3: π_ref/π - 1 - log(π_ref/π)
# DeepSeek-V3.2: 乘以 IS ratio 实现无偏估计
if importance_ratio is not None:
kl = importance_ratio * kl
if kl_loss_type == "low_var_kl":
kl = torch.clamp(kl, min=-10, max=10) # 数值截断@torch.compile(dynamic=True)
def compute_approx_kl(log_probs, log_probs_base, kl_loss_type, importance_ratio=None):
"""Schulman blog: http://joschu.net/blog/kl-approx.html"""
log_ratio = log_probs.float() - log_probs_base.float()
if kl_loss_type == "k1":
kl = log_ratio # K1: log(π/π_ref) = log_π - log_π_ref
elif kl_loss_type == "k2":
kl = log_ratio ** 2 / 2.0 # K2: (log(π/π_ref))² / 2
elif kl_loss_type in ["k3", "low_var_kl"]:
log_ratio = -log_ratio # 注意取反:log(π_ref/π)
kl = log_ratio.exp() - 1 - log_ratio # K3: π_ref/π - 1 - log(π_ref/π)
# DeepSeek-V3.2: 乘以 IS ratio 实现无偏估计
if importance_ratio is not None:
kl = importance_ratio * kl
if kl_loss_type == "low_var_kl":
kl = torch.clamp(kl, min=-10, max=10) # 数值截断verl 的 kl_penalty_forward(verl/trainer/ppo/core_algos.py)实现完全对应:
def kl_penalty_forward(logprob, ref_logprob, kl_penalty):
if kl_penalty in ("kl", "k1"): return logprob - ref_logprob
if kl_penalty == "abs": return (logprob - ref_logprob).abs()
if kl_penalty in ("mse", "k2"): return 0.5 * (logprob - ref_logprob).square()
if kl_penalty in ("low_var_kl", "k3"):
kl = ref_logprob - logprob
kl = torch.clamp(kl, min=-20, max=20)
ratio = torch.exp(kl)
kld = (ratio - kl - 1).contiguous()
return torch.clamp(kld, min=-10, max=10)def kl_penalty_forward(logprob, ref_logprob, kl_penalty):
if kl_penalty in ("kl", "k1"): return logprob - ref_logprob
if kl_penalty == "abs": return (logprob - ref_logprob).abs()
if kl_penalty in ("mse", "k2"): return 0.5 * (logprob - ref_logprob).square()
if kl_penalty in ("low_var_kl", "k3"):
kl = ref_logprob - logprob
kl = torch.clamp(kl, min=-20, max=20)
ratio = torch.exp(kl)
kld = (ratio - kl - 1).contiguous()
return torch.clamp(kld, min=-10, max=10)我们把公式、性质、代码对齐到一张表:
| 估计器 | 公式 | 是否无偏 | 梯度是否无偏 | 是否非负 | 用途 |
|---|---|---|---|---|---|
| K1 | ✅ | ❌ | ❌ | metric | |
| K2 | ❌ | ✅ | ✅ | penalty/loss | |
| K3 | ✅ | ❌ | ✅ | penalty |
verl 还额外实现了一个 Straight-Through KL 估计器(kl_penalty 函数),通过后缀 + 标记(如 k3+),让目标函数中的 KL 在前向用 K3 的值(非负、低方差),反向用 K2 的梯度(无偏):
def kl_penalty(logprob, ref_logprob, kl_penalty):
forward_score = kl_penalty_forward(logprob, ref_logprob, kl_penalty)
if not kl_penalty.endswith("+"):
return forward_score
# Straight-Through: 前向用 k3 值,反向用 k2 梯度
backward_score = 0.5 * (logprob - ref_logprob).square()
return backward_score - backward_score.detach() + forward_score.detach()def kl_penalty(logprob, ref_logprob, kl_penalty):
forward_score = kl_penalty_forward(logprob, ref_logprob, kl_penalty)
if not kl_penalty.endswith("+"):
return forward_score
# Straight-Through: 前向用 k3 值,反向用 k2 梯度
backward_score = 0.5 * (logprob - ref_logprob).square()
return backward_score - backward_score.detach() + forward_score.detach()这是一个非常优雅的工程设计——利用 x - x.detach() + y.detach() 的 straight-through trick,让值和梯度分别来自不同的估计器,兼顾了 K3 的非负性和 K2 的梯度无偏性。该方法来自论文 “On Computation and Design of KL Divergence for Reinforcement Learning and RLHF”(https://arxiv.org/abs/2505.17508)。
十、熵(Entropy):为什么策略不能太早变”过于自信”¶
10.1 熵的直觉¶
熵表示一个分布有多”散”、多”不确定”。
放到策略上理解:
- 熵高:策略保留较多可能性,探索更强
- 熵低:策略非常自信,更偏向 exploitation
10.2 为什么 RL 里要关心熵¶
如果训练太快让策略变得过于确定,就可能出现:
- 探索不足
- 早期陷入局部最优
- reasoning 路径变少
- 输出模式越来越单一
在 reasoning LLM RL 中,常有人讨论 entropy collapse:策略熵很快掉下去,训练后期很难再探索新解法。
10.3 Entropy bonus 在干什么¶
训练时常会加一个 entropy regularization / entropy bonus,本质是在鼓励:
别太快把所有概率都压到少数几个动作上。
10.4 工程师怎么判断熵是不是出了问题¶
可以看:
- token-level entropy 的均值变化
- 不同阶段 entropy 曲线是否快速塌缩
- 高 reward 是否伴随着异常低熵
- 模型输出是否越来越模板化
要注意:熵不是越高越好。熵过高会让策略发散、难以收敛;熵过低则探索不足。重点在于平衡。
10.5 工程实现解读:Entropy 的计算与 Entropy Bonus¶
verl 中的朴素实现(verl/utils/torch_functional.py):
def entropy_from_logits(logits):
"""Shannon entropy: H(p) = -Σ p·log(p) = logsumexp(x) - Σ softmax(x)·x"""
pd = torch.nn.functional.softmax(logits, dim=-1)
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1)
return entropydef entropy_from_logits(logits):
"""Shannon entropy: H(p) = -Σ p·log(p) = logsumexp(x) - Σ softmax(x)·x"""
pd = torch.nn.functional.softmax(logits, dim=-1)
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1)
return entropy注意它没有直接用 -Σ p·log(p) 的原始公式,而是用了等价的 logsumexp(x) - E[x] 形式,数值上更稳定。verl 还提供了 chunked 版本应对大 batch 的显存问题。
slime 中的分布式 Vocab-Parallel 实现(slime/utils/ppo_utils.py):
大模型训练中,vocab 维度往往被切分到多个 tensor parallel rank 上(例如 vocab_size=152064 切成 8 份)。此时直接对 logits 做 softmax 是不行的——每个 rank 只有部分 vocab 的 logits。slime 专门实现了一个 _VocabParallelEntropy 自定义 torch.autograd.Function:
class _VocabParallelEntropy(torch.autograd.Function):
@staticmethod
def forward(ctx, vocab_parallel_logits, process_group):
# 1. 全局 max 归一化(all_reduce MAX)
logits_max = vocab_parallel_logits.max(dim=-1, keepdim=True).values
dist.all_reduce(logits_max, op=dist.ReduceOp.MAX, group=process_group)
normalized = vocab_parallel_logits - logits_max
# 2. 计算 local exp 并 all_reduce sum(得到全局 softmax 分母)
exp_logits = normalized.exp_()
sum_exp = exp_logits.sum(dim=-1, keepdim=True)
dist.all_reduce(sum_exp, group=process_group)
# 3. 计算 local softmax 并求 Σ(p * logit)
softmax_logits = exp_logits.div_(sum_exp)
sum_softmax_times_logits = (softmax_logits * vocab_parallel_logits).sum(dim=-1, keepdim=True)
dist.all_reduce(sum_softmax_times_logits, group=process_group)
# 4. entropy = log(Z) + max - E[logit]
entropy = logits_max + sum_exp.log() - sum_softmax_times_logits
return entropy.squeeze(dim=-1)class _VocabParallelEntropy(torch.autograd.Function):
@staticmethod
def forward(ctx, vocab_parallel_logits, process_group):
# 1. 全局 max 归一化(all_reduce MAX)
logits_max = vocab_parallel_logits.max(dim=-1, keepdim=True).values
dist.all_reduce(logits_max, op=dist.ReduceOp.MAX, group=process_group)
normalized = vocab_parallel_logits - logits_max
# 2. 计算 local exp 并 all_reduce sum(得到全局 softmax 分母)
exp_logits = normalized.exp_()
sum_exp = exp_logits.sum(dim=-1, keepdim=True)
dist.all_reduce(sum_exp, group=process_group)
# 3. 计算 local softmax 并求 Σ(p * logit)
softmax_logits = exp_logits.div_(sum_exp)
sum_softmax_times_logits = (softmax_logits * vocab_parallel_logits).sum(dim=-1, keepdim=True)
dist.all_reduce(sum_softmax_times_logits, group=process_group)
# 4. entropy = log(Z) + max - E[logit]
entropy = logits_max + sum_exp.log() - sum_softmax_times_logits
return entropy.squeeze(dim=-1)这段代码最核心的设计是:把一个通常需要 all-gather 全部 logits 才能计算的 entropy,改成了只需要 3 次 all-reduce 标量/小 tensor 的操作。对一个 152K vocab 的模型,这能节省巨大的通信量。
Entropy Bonus 如何接入 Loss
在 slime 的 policy_loss_function 中:
entropy = torch.cat(log_probs_and_entropy["entropy"], dim=0)
entropy_loss = sum_of_sample_mean(entropy)
loss = pg_loss - args.entropy_coef * entropy_loss # 注意是减号:鼓励高 entropyentropy = torch.cat(log_probs_and_entropy["entropy"], dim=0)
entropy_loss = sum_of_sample_mean(entropy)
loss = pg_loss - args.entropy_coef * entropy_loss # 注意是减号:鼓励高 entropy在 verl 中也一样:loss = pg_loss - entropy_coef * entropy_loss。减号意味着 entropy 越高、loss 越低,这就是 entropy bonus 的作用——在优化方向上”奖励”策略保持分散。
十一、Loss:这些概念最后如何拼起来¶
从工程角度,loss 可以理解为:
把 reward 信号、相对优劣、分布约束、探索约束,拼成一个可反向传播的目标。
11.1 Policy Loss¶
这是 RL 优化的核心部分。它决定:
- 哪些动作概率该升高
- 哪些动作概率该降低
Policy loss 通常会和:
- advantage
- importance ratio
- clip 机制
一起出现。
11.2 Value Loss(如果有 critic)¶
如果训练链路中有 critic / value model,那么还会有 value loss,用来学习 baseline / value estimate,使 advantage 估计方差更低。
11.3 KL Loss / KL Penalty¶
负责防止策略走太远。
11.4 Entropy Bonus¶
负责维持一定探索性。
11.5 总损失¶
因此,一个典型 RL 系统中的总损失,往往不是一个”单一损失”,而是多个目标共同作用的结果。
所以当你看到 “loss 下降 / 不下降 / 爆炸” 时,必须问清楚:
- 是哪一项在主导变化?
- policy loss 正常吗?
- KL 是否异常?
- entropy 是否塌了?
- value loss 是否不收敛?
只看一个”total loss”数值,通常不够排查问题。
11.6 工程实现解读:总 Loss 的组装¶
slime 的 policy_loss_function(slime/backends/megatron_utils/loss.py)展示了完整的总 loss 组装过程:
# 1. Policy Loss (PPO clip)
pg_loss, pg_clipfrac = compute_policy_loss(ppo_kl, advantages, args.eps_clip, args.eps_clip_high)
# 2. 可选:OPSM mask(off-policy 序列过滤)
if args.use_opsm:
pg_loss = pg_loss * opsm_mask
# 3. 可选:TIS/ICEPOP(off-policy 重要性权重矫正)
if args.use_tis:
pg_loss, modified_masks, tis_metrics = tis_func(pg_loss=pg_loss, ...)
# 4. 聚合 policy loss
pg_loss = pg_loss_reducer(pg_loss)
# 5. Entropy Bonus
entropy_loss = sum_of_sample_mean(entropy)
loss = pg_loss - args.entropy_coef * entropy_loss
# 6. 可选:KL Loss(对 ref policy)
if args.use_kl_loss:
kl = compute_approx_kl(log_probs, ref_log_probs, kl_loss_type=args.kl_loss_type,
importance_ratio=importance_ratio)
kl_loss = sum_of_sample_mean(kl)
loss = loss + args.kl_loss_coef * kl_loss# 1. Policy Loss (PPO clip)
pg_loss, pg_clipfrac = compute_policy_loss(ppo_kl, advantages, args.eps_clip, args.eps_clip_high)
# 2. 可选:OPSM mask(off-policy 序列过滤)
if args.use_opsm:
pg_loss = pg_loss * opsm_mask
# 3. 可选:TIS/ICEPOP(off-policy 重要性权重矫正)
if args.use_tis:
pg_loss, modified_masks, tis_metrics = tis_func(pg_loss=pg_loss, ...)
# 4. 聚合 policy loss
pg_loss = pg_loss_reducer(pg_loss)
# 5. Entropy Bonus
entropy_loss = sum_of_sample_mean(entropy)
loss = pg_loss - args.entropy_coef * entropy_loss
# 6. 可选:KL Loss(对 ref policy)
if args.use_kl_loss:
kl = compute_approx_kl(log_probs, ref_log_probs, kl_loss_type=args.kl_loss_type,
importance_ratio=importance_ratio)
kl_loss = sum_of_sample_mean(kl)
loss = loss + args.kl_loss_coef * kl_loss最终的 loss 表达式是:
slime 同时上报了所有分项指标:
reported_loss = {
"loss": loss, # 总 loss
"pg_loss": pg_loss, # policy gradient loss
"entropy_loss": entropy_loss, # 熵
"pg_clipfrac": pg_clipfrac, # 被 clip 的比例
"ppo_kl": ppo_kl, # old vs current 的 KL
"train_rollout_logprob_abs_diff": ..., # 训推 logprob 差异
"kl_loss": kl_loss, # ref KL loss(可选)
"ois": ..., # importance sampling ratio(可选)
"tis_clipfrac": ..., # TIS 被 clip 的比例(可选)
"opsm_clipfrac": ..., # OPSM 被 mask 的比例(可选)
}reported_loss = {
"loss": loss, # 总 loss
"pg_loss": pg_loss, # policy gradient loss
"entropy_loss": entropy_loss, # 熵
"pg_clipfrac": pg_clipfrac, # 被 clip 的比例
"ppo_kl": ppo_kl, # old vs current 的 KL
"train_rollout_logprob_abs_diff": ..., # 训推 logprob 差异
"kl_loss": kl_loss, # ref KL loss(可选)
"ois": ..., # importance sampling ratio(可选)
"tis_clipfrac": ..., # TIS 被 clip 的比例(可选)
"opsm_clipfrac": ..., # OPSM 被 mask 的比例(可选)
}Value Loss
verl 中 critic 的 value loss 实现(verl/trainer/ppo/core_algos.py 中的 compute_value_loss):
def compute_value_loss(vpreds, returns, values, response_mask, cliprange_value, ...):
# Clipped value loss: 类似 PPO 对 ratio 的 clip,防止 value 估计跳变太猛
vpredclipped = clip_by_value(vpreds, values - cliprange_value, values + cliprange_value)
vf_losses1 = (vpreds - returns) ** 2
vf_losses2 = (vpredclipped - returns) ** 2
clipped_vf_losses = torch.max(vf_losses1, vf_losses2)
vf_loss = 0.5 * agg_loss(clipped_vf_losses, response_mask, loss_agg_mode)
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), response_mask)
return vf_loss, vf_clipfracdef compute_value_loss(vpreds, returns, values, response_mask, cliprange_value, ...):
# Clipped value loss: 类似 PPO 对 ratio 的 clip,防止 value 估计跳变太猛
vpredclipped = clip_by_value(vpreds, values - cliprange_value, values + cliprange_value)
vf_losses1 = (vpreds - returns) ** 2
vf_losses2 = (vpredclipped - returns) ** 2
clipped_vf_losses = torch.max(vf_losses1, vf_losses2)
vf_loss = 0.5 * agg_loss(clipped_vf_losses, response_mask, loss_agg_mode)
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), response_mask)
return vf_loss, vf_clipfracLoss 聚合模式
verl 的 agg_loss 提供了三种 loss 聚合方式,它们的选择会显著影响训练行为:
def agg_loss(loss_mat, loss_mask, loss_agg_mode, dp_size=1, ...):
if loss_agg_mode == "token-mean":
# 全局 token 平均:每个有效 token 等权
loss = masked_sum(loss_mat, loss_mask) / batch_num_tokens * dp_size
elif loss_agg_mode == "seq-mean-token-sum":
# 先 token-sum 再 sequence-mean:长序列贡献更大
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1)
loss = masked_sum(seq_losses, seq_mask) / global_batch_size * dp_size
elif loss_agg_mode == "seq-mean-token-mean":
# 先 token-mean 再 sequence-mean:每条序列等权
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / (seq_mask + 1e-8)
loss = masked_sum(seq_losses, seq_mask) / global_batch_size * dp_sizedef agg_loss(loss_mat, loss_mask, loss_agg_mode, dp_size=1, ...):
if loss_agg_mode == "token-mean":
# 全局 token 平均:每个有效 token 等权
loss = masked_sum(loss_mat, loss_mask) / batch_num_tokens * dp_size
elif loss_agg_mode == "seq-mean-token-sum":
# 先 token-sum 再 sequence-mean:长序列贡献更大
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1)
loss = masked_sum(seq_losses, seq_mask) / global_batch_size * dp_size
elif loss_agg_mode == "seq-mean-token-mean":
# 先 token-mean 再 sequence-mean:每条序列等权
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / (seq_mask + 1e-8)
loss = masked_sum(seq_losses, seq_mask) / global_batch_size * dp_size这三种模式的选择不是随意的:
token-mean让长序列贡献更多梯度(因为更多 token 参与平均)seq-mean-token-mean让每条序列等权贡献,不因长度而有偏差seq-mean-token-sum介于两者之间
十二、回到 RL Infra:Rollout 侧和 Trainer 侧到底分别在做什么¶
12.1 Rollout 侧¶
Rollout 侧最核心的职责是:真实地产生训练样本。
它通常需要记录:
- prompt / response token ids
- 采样到的 token
- old logprob
- valid mask / response mask
- reward / 评分结果
- 可选:top-k / top-p 的 sampling mask
- 可选:MoE routing topk_ids / routing mask
12.2 Trainer 侧¶
Trainer 侧不负责”重新创造样本”,而是负责:
- 重算当前策略下这些已知动作的 logprob
- 构造 ratio
- 计算 KL / entropy / policy loss
- 做反向传播
这点非常重要:
训练侧通常并不会再次随机采样 token。
它做的是一种 replay / teacher-forcing 式前向:rollout 已经告诉你”当时选了什么动作”,trainer 要做的是”当前策略如何评价这些已发生动作”。
12.3 工程实现解读:Rollout 侧具体记录了什么¶
slime 的 Sample 数据类完整记录了 rollout 侧需要保留的所有信息:
@dataclass
class Sample:
tokens: list[int] # prompt + response token ids
rollout_log_probs: list[float] | None # rollout 引擎输出的 log 概率
rollout_routed_experts: list[list[int]] | None # MoE 路由信息(哪些 expert 被选中)
reward: float | dict[str, Any] | None # reward(标量或多维)
loss_mask: list[int] | None # 每个 token 的 loss mask
response_length: int # response 部分长度
teacher_log_probs: list[float] | None # 蒸馏场景下教师模型的 logprob
weight_versions: list[str] # 策略版本标记(用于判断 off-policy 程度)@dataclass
class Sample:
tokens: list[int] # prompt + response token ids
rollout_log_probs: list[float] | None # rollout 引擎输出的 log 概率
rollout_routed_experts: list[list[int]] | None # MoE 路由信息(哪些 expert 被选中)
reward: float | dict[str, Any] | None # reward(标量或多维)
loss_mask: list[int] | None # 每个 token 的 loss mask
response_length: int # response 部分长度
teacher_log_probs: list[float] | None # 蒸馏场景下教师模型的 logprob
weight_versions: list[str] # 策略版本标记(用于判断 off-policy 程度)整个 rollout 流程在 generate_rollout_async()(slime/rollout/sglang_rollout.py)中编排:
async def generate_rollout_async(self, ...):
while len(all_samples) < target_data_size:
# 1. 从数据源获取 prompt
batch = data_source.get_prompts(batch_size)
# 2. 调用 SGLang 引擎生成 + 打分
samples = await generate_and_rm(batch)
# 3. 过滤无效样本(ABORTED/TRUNCATED 等状态)
samples = filter_samples(samples)
# 4. 可选:动态过滤(filter_hub)
if dynamic_filter:
samples = filter_hub.filter(samples)
all_samples.extend(samples)async def generate_rollout_async(self, ...):
while len(all_samples) < target_data_size:
# 1. 从数据源获取 prompt
batch = data_source.get_prompts(batch_size)
# 2. 调用 SGLang 引擎生成 + 打分
samples = await generate_and_rm(batch)
# 3. 过滤无效样本(ABORTED/TRUNCATED 等状态)
samples = filter_samples(samples)
# 4. 可选:动态过滤(filter_hub)
if dynamic_filter:
samples = filter_hub.filter(samples)
all_samples.extend(samples)注意 weight_versions 字段——它记录了该样本是由哪个版本的策略产生的。在异步训练中,当 rollout 和 training 并行执行时,到达训练侧的样本可能来自不同版本的策略,weight_versions 就是 TIS/ICEPOP 判断 off-policy 程度的依据。
十三、训推一致:为什么这是 RL Infra 的关键问题¶
在理想世界里,我们希望:
- rollout 用的策略分布
- trainer 重算出来的策略分布
应该尽量一致。
但现实里,训推一致会被很多因素破坏:
- rollout 和 trainer 框架不同
- sampling 规则不同
- top-k / top-p support 不同
- MoE expert 选择不同
- repeated forward 本身有非确定性
于是会导致:
- old/current logprob 差异异常
- ratio 长尾
- KL 偏大
- 训练不稳定
- 样本明明来自”旧策略”,trainer 却像在用”另一套策略”解释它
因此,RL Infra 里很重要的一类指标就是:
- logprob gap
- policy KL
- extreme token discrepancy
- ratio 分布
- clipfrac
- routing discrepancy(MoE 场景)
13.1 工程实现解读:训推一致性的度量与监控¶
slime 在 policy_loss_function 中专门计算了训推不一致的度量指标:
# 计算 rollout logprob 与 train 初始 logprob 的绝对差异
if "rollout_log_probs" in batch and batch["rollout_log_probs"]:
rollout_log_probs = torch.cat(batch["rollout_log_probs"], dim=0)
train_rollout_logprob_abs_diff = sum_of_sample_mean((old_log_probs - rollout_log_probs).abs())
reported_loss["train_rollout_logprob_abs_diff"] = train_rollout_logprob_abs_diff# 计算 rollout logprob 与 train 初始 logprob 的绝对差异
if "rollout_log_probs" in batch and batch["rollout_log_probs"]:
rollout_log_probs = torch.cat(batch["rollout_log_probs"], dim=0)
train_rollout_logprob_abs_diff = sum_of_sample_mean((old_log_probs - rollout_log_probs).abs())
reported_loss["train_rollout_logprob_abs_diff"] = train_rollout_logprob_abs_diff这个指标非常实用:如果 train_rollout_logprob_abs_diff 很大,说明 rollout 引擎(如 SGLang/vLLM)和训练框架(如 Megatron)计算出的 logprob 有显著差异。可能的原因包括:
- 数值精度差异(fp16 vs bf16 vs fp32)
- attention 实现差异(Flash Attention v2 vs v3)
- MoE 路由不一致
slime 还通过 --use-rollout-logprobs 参数提供了两种模式的选择:使用 rollout 引擎记录的 logprob 作为 old policy(减少一次训练侧前向),还是在训练侧重新计算一次 logprob 作为 old policy(更精确但更慢)。
十四、KSM:Keep Sampling Mask 的本质是什么¶
14.1 背景¶
如果 rollout 时用了 top-k / top-p,那么”真正允许被采样的 token 集合”其实已经被截断了。
但如果 trainer 重算 logprob 时直接在 full vocab 上算,那么就会出现:
- rollout 的动作空间是一个子集
- trainer 的动作空间却是全空间
这样 old policy 和 current policy 的 support 不一致,ratio / KL 的解释就会变脏。
14.2 KSM 在做什么¶
KSM(Keep Sampling Mask)的做法就是:
把 rollout 时的 sampling mask 保留下来,训练时在当前策略 logits 上施加同一个 mask,然后只在这个相同的动作子空间上重算 logprob / ratio / KL。
14.3 一个最容易误解的点¶
训练侧没有重新采样。
KSM 的作用不是”训练时再用同样的 mask 采一次 token”,而是:
- rollout 已经决定了当时采到哪个 token
- trainer 现在要在相同 support 上,给这个已知 token 重新计分
所以 KSM 解决的是 action-space consistency,不是”再次采样”。
14.4 工程实现解读:OPSM——Off-Policy Sequence Masking¶
KSM 在 DeepSeek-V3.2 的论文中被提出,目前在开源框架中尚未看到完整的 per-token sampling mask 保留实现(需要为每个 token 存储一个 top-k/top-p 的 vocab mask,存储开销很大)。
但 slime 实现了一种更粗粒度但工程上更实用的替代方案——OPSM(Off-Policy Sequence Masking)(slime/utils/ppo_utils.py):
def compute_opsm_mask(args, full_log_probs, full_old_log_probs, advantages, loss_masks):
"""在 sequence 粒度上过滤 off-policy 程度过大的样本"""
for full_log_prob, full_old_log_prob, advantage, loss_mask in zip(...):
# 计算 sequence-level KL
seq_kl = ((full_old_log_prob - full_log_prob) * loss_mask).sum() / loss_mask.sum()
# 条件:advantage < 0 且 KL > 阈值 → mask 掉这条序列
mask = ((advantage < 0) & (seq_kl > args.opsm_delta)).float()
opsm_mask_list.append(1 - mask)def compute_opsm_mask(args, full_log_probs, full_old_log_probs, advantages, loss_masks):
"""在 sequence 粒度上过滤 off-policy 程度过大的样本"""
for full_log_prob, full_old_log_prob, advantage, loss_mask in zip(...):
# 计算 sequence-level KL
seq_kl = ((full_old_log_prob - full_log_prob) * loss_mask).sum() / loss_mask.sum()
# 条件:advantage < 0 且 KL > 阈值 → mask 掉这条序列
mask = ((advantage < 0) & (seq_kl > args.opsm_delta)).float()
opsm_mask_list.append(1 - mask)OPSM 的设计直觉是:如果一条序列的 advantage 本来就是负的(“坏样本”),而且 policy 已经偏离得很远(KL 超过阈值),那么这条序列对训练的贡献更多是噪声而非信号——不如直接 mask 掉。它不需要像 KSM 那样保存 per-token 的 vocab mask,存储开销为零,但从 sequence 层面提供了类似的”抛弃 off-policy 程度过大的数据”的能力。
十五、R3 / Routing Replay:为什么 MoE 的 RL 更难¶
15.1 MoE 带来的额外问题¶
在 dense 模型里,某个 token 前向经过的是同一套参数。
但在 MoE 模型里,中间会有路由器决定:
- 当前 token 进入哪些 experts
- 不同 experts 的 gate 权重是多少
这意味着:
同一个 token,如果 rollout 和 trainer 走了不同 experts,那么它们其实已经不是”同一条前向路径”。
15.2 routing mismatch 会导致什么¶
它不仅仅是数值有一点偏差,而是:
- 激活的参数子空间都变了
- rollout 时负责该样本的 experts,trainer 未必还在更新
- logprob 差异会被放大
- ratio 和 KL 会被污染
15.3 R3 的核心思想¶
R3(常见语境下可理解为 Rollout Routing Replay)关注的是:
在训练侧复用 rollout 时记录下来的 routing 选择,让 trainer 与 rollout 经过同一组 experts。
更细一点说:
- dispatch 到哪些 experts,由 rollout 记录的 routing topk_ids / routing mask 决定
- 但这些 experts 上的 gate 权重,仍然可以由训练侧当前 router logits 在固定 expert 集合上重新归一化得到
15.4 为什么这样设计¶
因为它兼顾了两件事:
- 路径一致性:trainer 和 rollout 走的是同一组 experts
- 梯度可传:训练侧当前 router 仍然参与计算,不是简单把所有路由结果硬编码成常数
15.5 对 RL Infra 工程师的意义¶
如果你做的是 MoE RL,这一类信息很可能需要进 buffer:
- per-layer routing topk_ids
- routing mask
- 可能还有必要的辅助统计
否则 trainer 无法真正复现 rollout 的参数子空间。
15.6 工程实现解读:slime 中 Routing Replay 的完整实现¶
slime 提供了一套完整的 Routing Replay 机制(slime/utils/routing_replay.py),设计非常精巧。
核心数据结构:
class RoutingReplay:
all_routing_replays = [] # 全局注册表,管理所有 MoE 层的 replay 实例
def __init__(self):
self.forward_index = 0 # 前向 replay 的读取指针
self.backward_index = 0 # 反向 replay 的读取指针
self.top_indices_list = [] # 存储 rolled-out 的 routing 选择
def record(self, top_indices):
# 关键:offload 到 CPU pinned memory,节省 GPU 显存
buf = torch.empty_like(top_indices, device="cpu", pin_memory=True)
buf.copy_(top_indices)
self.top_indices_list.append(buf)
def pop_forward(self):
top_indices = self.top_indices_list[self.forward_index]
self.forward_index += 1
return top_indices.to(torch.cuda.current_device()) # 需要时再搬回 GPUclass RoutingReplay:
all_routing_replays = [] # 全局注册表,管理所有 MoE 层的 replay 实例
def __init__(self):
self.forward_index = 0 # 前向 replay 的读取指针
self.backward_index = 0 # 反向 replay 的读取指针
self.top_indices_list = [] # 存储 rolled-out 的 routing 选择
def record(self, top_indices):
# 关键:offload 到 CPU pinned memory,节省 GPU 显存
buf = torch.empty_like(top_indices, device="cpu", pin_memory=True)
buf.copy_(top_indices)
self.top_indices_list.append(buf)
def pop_forward(self):
top_indices = self.top_indices_list[self.forward_index]
self.forward_index += 1
return top_indices.to(torch.cuda.current_device()) # 需要时再搬回 GPU通过环境变量和 hook 切换三种模式:
def get_routing_replay_compute_topk(old_compute_topk):
"""替换 MoE 层的原始 compute_topk 函数"""
def compute_topk(scores, topk, ...):
routing_replay_stage = os.environ["ROUTING_REPLAY_STAGE"]
if routing_replay_stage == "record":
# 记录模式:正常计算 routing,但把结果存下来
probs, top_indices = old_compute_topk(scores, topk, ...)
ROUTING_REPLAY.record(top_indices)
elif routing_replay_stage == "replay_forward":
# 前向 replay:不重新选 expert,用记录的 top_indices
top_indices = ROUTING_REPLAY.pop_forward()
# 关键:用当前 router logits 在固定 expert 集合上重算 gate 权重
probs = scores.gather(1, top_indices)
elif routing_replay_stage == "replay_backward":
# 反向 replay:同样固定 expert,但用于反向传播
top_indices = ROUTING_REPLAY.pop_backward()
probs = scores.gather(1, top_indices)
return probs, top_indices
return compute_topkdef get_routing_replay_compute_topk(old_compute_topk):
"""替换 MoE 层的原始 compute_topk 函数"""
def compute_topk(scores, topk, ...):
routing_replay_stage = os.environ["ROUTING_REPLAY_STAGE"]
if routing_replay_stage == "record":
# 记录模式:正常计算 routing,但把结果存下来
probs, top_indices = old_compute_topk(scores, topk, ...)
ROUTING_REPLAY.record(top_indices)
elif routing_replay_stage == "replay_forward":
# 前向 replay:不重新选 expert,用记录的 top_indices
top_indices = ROUTING_REPLAY.pop_forward()
# 关键:用当前 router logits 在固定 expert 集合上重算 gate 权重
probs = scores.gather(1, top_indices)
elif routing_replay_stage == "replay_backward":
# 反向 replay:同样固定 expert,但用于反向传播
top_indices = ROUTING_REPLAY.pop_backward()
probs = scores.gather(1, top_indices)
return probs, top_indices
return compute_topk注册机制:通过 register_routing_replay 在每个 MoE 层上注册 hook:
def register_routing_replay(module):
if os.environ.get("ENABLE_ROUTING_REPLAY", "0") == "1":
module.routing_replay = RoutingReplay()
def pre_forward_hook(*args, **kwargs):
set_routing_replay(module.routing_replay)
module.register_forward_pre_hook(pre_forward_hook)def register_routing_replay(module):
if os.environ.get("ENABLE_ROUTING_REPLAY", "0") == "1":
module.routing_replay = RoutingReplay()
def pre_forward_hook(*args, **kwargs):
set_routing_replay(module.routing_replay)
module.register_forward_pre_hook(pre_forward_hook)整个设计有几个值得注意的工程细节:
- CPU offload + pinned memory:routing indices 存储在 CPU pinned memory 中,不占用 GPU 显存,又能通过 DMA 快速传输回 GPU
- 三阶段设计:
record(rollout 时记录)→replay_forward(训练前向时复用)→replay_backward(训练反向时复用),通过环境变量ROUTING_REPLAY_STAGE切换 probs = scores.gather(1, top_indices):这行代码是 R3 的精髓——用当前 router 的 scores 在固定的 expert 集合上做 gather,既保证了路径一致性,又保证了 router 的梯度可以传播
对应到 Sample 数据结构中,rollout 时记录的路由信息存储在 rollout_routed_experts: list[list[int]] 字段中,随样本一起流入 trainer。
十六、训练侧拿到 routing topk_ids 和 sampling mask 后到底在干什么¶
这一段把前面两个概念合起来讲。
16.1 sampling mask 的使用¶
训练侧不会重新采样 token,而是:
- 用当前策略前向得到 vocab logits
- 对 logits 施加 rollout 保留下来的 sampling mask
- 在 masked 后的分布上,重算已知 sampled token 的 logprob
- 进一步计算 ratio / KL / policy loss
也就是说:
sampling mask 决定的是”在哪个动作空间上重算概率”。
16.2 routing topk_ids 的使用¶
对每一层 MoE:
- 训练侧仍然会算当前 router logits
- 但不再自由地重新选择 experts
- 而是使用 rollout 记录下来的 topk_ids / routing mask 固定 dispatch 集合
- 在该固定 expert 集合上,用训练侧 logits 重新计算 gate 权重
- 只执行这些 experts
也就是说:
routing topk_ids 决定的是”中间前向走哪条 expert 路径”。
16.3 二者的区别¶
sampling mask:作用于输出 token 概率空间routing topk_ids:作用于中间 MoE 参数路径
一个修 action space,一个修 parameter subspace。
16.4 工程实现解读:代码层面的对比¶
将 Routing Replay 和 OPSM 的实现放在一起看,它们的相似性和差异性更加清晰:
| 维度 | OPSM(Action Space) | Routing Replay(Parameter Subspace) |
|---|---|---|
| 作用层 | 输出层 logits → logprob | 中间 MoE 层 routing |
| 粒度 | 序列级 mask | 逐 layer、逐 token 的 expert 选择 |
| 存储开销 | 零(运行时计算) | 较大(per-layer 的 top_indices,CPU offload) |
| 机制 | 直接过滤 loss(mask=0 的序列不参与梯度) | 替换 routing 函数(固定 expert,重算 gate) |
| 梯度 | 被 mask 的序列无梯度 | router 梯度仍然可传播 |
十七、RL Infra 工程师必须理解的几个额外概念¶
下面这些概念在很多项目里不会作为论文主角出现,但在系统实现和排查中非常关键。
17.1 Rollout Buffer / Replay Buffer¶
这是样本暂存层。大模型 RL 中,buffer 里不只是 token ids,还常包括:
- old logprob
- reward / score
- advantage / return
- mask
- sequence length
- 参考模型分数
- 可选的 MoE routing 信息
buffer 设计不好,后面所有对齐都会出问题。
17.1.1 工程实现解读:slime 的 RolloutBuffer 设计¶
slime 的 RolloutBuffer(slime_plugins/rollout_buffer/buffer.py)使用 BufferQueue + 线程安全设计实现了 rollout 和 training 的并发解耦:
- rollout 侧异步填充 buffer
- training 侧同步消费 buffer
- 通过 pinned memory 加速 CPU → GPU 传输
进入 training 后,buffer 中的 Sample 列表会被转换为 RolloutBatch(slime/utils/types.py)——一个字典结构,包含:
RolloutBatch = dict[str, list[torch.Tensor] | list[int] | list[float] | list[str]]
# 主要 key 包括:
# "tokens": list[torch.Tensor] - 每条样本的 token ids
# "rollout_log_probs": list[torch.Tensor] - rollout logprob
# "log_probs": list[torch.Tensor] - train 侧重算的 logprob
# "ref_log_probs": list[torch.Tensor] - ref model logprob
# "rewards": list[float] - reward
# "values": list[torch.Tensor] - critic value(PPO 场景)
# "advantages": list[torch.Tensor] - 计算后的 advantage
# "returns": list[torch.Tensor] - target return
# "loss_masks": list[torch.Tensor] - per-token loss mask
# "response_lengths": list[int] - response 长度
# "total_lengths": list[int] - 总长度RolloutBatch = dict[str, list[torch.Tensor] | list[int] | list[float] | list[str]]
# 主要 key 包括:
# "tokens": list[torch.Tensor] - 每条样本的 token ids
# "rollout_log_probs": list[torch.Tensor] - rollout logprob
# "log_probs": list[torch.Tensor] - train 侧重算的 logprob
# "ref_log_probs": list[torch.Tensor] - ref model logprob
# "rewards": list[float] - reward
# "values": list[torch.Tensor] - critic value(PPO 场景)
# "advantages": list[torch.Tensor] - 计算后的 advantage
# "returns": list[torch.Tensor] - target return
# "loss_masks": list[torch.Tensor] - per-token loss mask
# "response_lengths": list[int] - response 长度
# "total_lengths": list[int] - 总长度注意 slime 使用 list 而非 padding 后的 2D tensor 存储——这与 Megatron 的 sequence packing 机制配合,避免了 padding 带来的算力浪费。而 verl 的 DataProto.batch 则使用 2D padded tensor,与 FSDP 的 batch 并行更匹配。
17.2 Old Policy / Current Policy / Reference Policy¶
这三个词很容易混:
- old policy:rollout 采样时的策略
- current policy:trainer 当前正在更新的策略
- reference policy:用于 KL 约束的参考策略(常是 SFT policy)
工程里一定要区分清楚,不然”KL 到底相对谁算”会彻底混乱。
17.2.1 工程实现解读:三种策略在代码中的体现¶
在 slime 的 policy_loss_function 中,三种策略的 logprob 分别用不同变量承载:
# old policy: rollout 时记录的,或 train 开始时重算的
old_log_probs = batch["rollout_log_probs"] if args.use_rollout_logprobs else batch["log_probs"]
# current policy: 当前 forward 算出来的(有梯度)
log_probs = log_probs_and_entropy["log_probs"]
# reference policy: 独立的 ref model 前向算出来的
ref_log_probs = batch["ref_log_probs"]
# PPO ratio: current / old
ppo_kl = old_log_probs - log_probs # ratio = exp(log_probs - old_log_probs)
# KL penalty: current vs ref
kl = compute_approx_kl(log_probs, ref_log_probs, ...)# old policy: rollout 时记录的,或 train 开始时重算的
old_log_probs = batch["rollout_log_probs"] if args.use_rollout_logprobs else batch["log_probs"]
# current policy: 当前 forward 算出来的(有梯度)
log_probs = log_probs_and_entropy["log_probs"]
# reference policy: 独立的 ref model 前向算出来的
ref_log_probs = batch["ref_log_probs"]
# PPO ratio: current / old
ppo_kl = old_log_probs - log_probs # ratio = exp(log_probs - old_log_probs)
# KL penalty: current vs ref
kl = compute_approx_kl(log_probs, ref_log_probs, ...)在 verl 中也是完全一致的三方 logprob 结构:old_log_probs / log_probs / ref_log_prob。
17.3 On-policy / Off-policy¶
- on-policy:样本基本来自当前策略
- off-policy:样本来自较旧或不同的策略
LLM RL 实际上很多时候是”轻度 off-policy”:
- rollout 和 train 有异步
- rollout / train 框架不同
- 采样 support 或 MoE 路由不一致
因此很多问题虽然表面不是”经验回放”,但本质已经带有 off-policy 味道。
17.3.1 工程实现解读:Off-Policy 的三道防线¶
slime 针对 off-policy 问题实现了三种不同粒度的矫正机制,可以组合使用:
- PPO Clip(token 级):限制每个 token 的 ratio 更新幅度——
ratio.clamp(1 - eps, 1 + eps) - TIS / ICEPOP(token 级):基于 rollout-train logprob 差异的 IS 权重矫正
- OPSM(sequence 级):直接丢弃 off-policy 程度过大的序列
这三道防线从细到粗,从”限制幅度”到”矫正权重”到”直接丢弃”,构成了一个分层的 off-policy 防护体系。
17.4 Valid Mask / Response Mask / Padding Mask¶
RL loss 不会对所有 token 一视同仁。常见至少要区分:
- prompt token
- response token
- padding token
- 被截断位置
- 无效位置
mask 的定义不对,loss、KL、entropy、统计指标都会失真。
更具体地说,这几个名字虽然在不同项目里命名略有差异,但通常是在解决三个不同层面的问题:
- Padding Mask:哪些位置只是为了把 batch 对齐而补出来的,不是真实 token
- Response Mask:哪些位置属于模型生成的 response,而不是 prompt
- Valid Mask:哪些位置在当前这一步计算里应该真正参与统计或优化
可以把它们理解成一层层收缩的筛子:
其中:
- padding mask 解决的是”张量形状问题”。为了做 batch 并行,短样本后面常要补 pad token;这些位置必须从 loss、KL、entropy、advantage whitening 的统计里排除掉,否则就会把纯粹的占位符当成训练信号。
- response mask 解决的是”训练语义问题”。在标准 SFT 或 RLHF/RLVR 里,我们通常只希望优化 assistant 生成的部分,而不去优化 prompt 本身,所以 prompt token 往往需要被屏蔽。
- valid mask 解决的是”当前算子口径问题”。它通常是最终真正传进
masked_mean、policy loss、clipfrac、advantage 标准化等算子的 mask,比 response mask 更严格,因为它还可能继续排除 EOS 之后、truncate 之后、step_loss_mask=0、off-policy 被丢弃的位置。
一个很容易混淆的点是:attention mask 不等于 loss mask。
attention mask 决定一个 token 在 forward 时能不能被模型”看见”;loss / valid mask 决定这个 token 在 backward 和统计时会不会”被计分”。前者服务于计算图的可见性,后者服务于训练目标的口径。
从工程角度看,这几个 mask 至少会影响四件事:
- policy loss 的分母:到底平均到哪些 token 上
- KL / entropy 的统计口径:是否只统计有效 response 区域
- advantage 的白化范围:是按全部 response token,还是只按有效 token
- 监控指标是否失真:clipfrac、mean_kl、entropy、reward 均值是否被 padding 或无效位置污染
所以排查问题时,经常要先问清楚一句话:
你现在看到的这个数,到底是在哪个 mask 上算出来的?
如果这个问题答不清楚,那么很多”训练不稳定”其实都还没有进入算法层,而只是停留在统计口径不一致这一层。
17.4.1 工程实现解读:Masked 操作的基础设施¶
verl 提供了一套完整的 masked 统计工具(verl/utils/torch_functional.py):
def masked_sum(values, mask, axis=None):
"""NaN-safe masked sum"""
valid_values = torch.where(mask.bool(), values, 0.0) # NaN 外的值置零
return (valid_values * mask).sum(axis=axis)
def masked_mean(values, mask, axis=None):
return masked_sum(values, mask, axis) / (mask.sum(axis=axis) + 1e-8)
def masked_var(values, mask, unbiased=True):
mean = masked_mean(values, mask)
variance = masked_mean((values - mean) ** 2, mask)
if unbiased:
bessel_correction = mask.sum() / (mask.sum() - 1) # Bessel 修正
variance = variance * bessel_correction
return variance
def masked_whiten(values, mask, shift_mean=True):
"""白化:(x - mean) / sqrt(var + eps)"""
mean, var = masked_mean(values, mask), masked_var(values, mask)
whitened = (values - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whiteneddef masked_sum(values, mask, axis=None):
"""NaN-safe masked sum"""
valid_values = torch.where(mask.bool(), values, 0.0) # NaN 外的值置零
return (valid_values * mask).sum(axis=axis)
def masked_mean(values, mask, axis=None):
return masked_sum(values, mask, axis) / (mask.sum(axis=axis) + 1e-8)
def masked_var(values, mask, unbiased=True):
mean = masked_mean(values, mask)
variance = masked_mean((values - mean) ** 2, mask)
if unbiased:
bessel_correction = mask.sum() / (mask.sum() - 1) # Bessel 修正
variance = variance * bessel_correction
return variance
def masked_whiten(values, mask, shift_mean=True):
"""白化:(x - mean) / sqrt(var + eps)"""
mean, var = masked_mean(values, mask), masked_var(values, mask)
whitened = (values - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitenedmasked_whiten 在 advantage 计算中被广泛使用(在 GAE、GRPO 等估计器中,advantage 通常会做 masked whiten),目的是让优化信号在零点附近、且方差为 1,避免因 advantage 的绝对值过大/过小导致梯度不稳定。
注意 masked_sum 中 torch.where(mask.bool(), values, 0.0) 的 NaN-safe 处理——这是一个关键的 defensive 设计:padding 区域可能出现 NaN(例如 logprob 对 padding token 取 log(0)),这行代码确保 NaN 不会污染正常区域的统计。
17.5 Sequence Packing / Padding / Truncation¶
为了提升吞吐,工程上会做 packing、padding、截断。但这些优化会直接影响:
- mask 是否对齐
- reward / advantage 是否串样本
- KL / entropy 是否统计到无效位置
所以很多性能优化都必须和训练语义严格对齐。
17.6 Determinism / Reproducibility¶
RL 系统本来噪声就大,如果再叠加:
- 不同框架 forward 差异
- 采样器实现差异
- MoE 路由非确定性
- kernel 数值不一致
排查会非常困难。因此 RL Infra 里很重要的一类能力是:
- 可复现
- 可重放
- 可对齐
- 可比较
十八、看懂指标:RL Infra 工程师平时到底该盯什么¶
一个比较实用的指标视角是分四层看。
18.1 分布层¶
关注:
- old/current logprob gap
- policy KL
- ref/current KL
- extreme token discrepancy
含义:trainer 是否真的在复现 rollout 的概率分布。
18.2 动作空间层¶
关注:
- sampling mask 是否保留
- top-k/top-p support 是否一致
- ratio 分布是否异常
含义:两边是否在同一个动作空间上比较概率。
18.3 参数子空间层(MoE 特有)¶
关注:
- routing diff
- 每层 expert 选择偏差
- token-level routing mismatch
含义:trainer 与 rollout 是否在更新同一批 experts。
18.4 训练动态层¶
关注:
- reward 曲线
- entropy 曲线
- clipfrac
- loss 分项
- collapse step
- benchmark / pass@k
含义:前面这些底层一致性问题,是否已经实质影响训练稳定性和最终效果。
18.5 工程实现解读:完整的指标体系¶
slime 的 policy_loss_function 一次性上报了覆盖上述四层的完整指标:
reported_loss = {
# 训练动态层
"loss": loss, # 总 loss
"pg_loss": pg_loss, # policy gradient loss
"entropy_loss": entropy_loss, # 策略熵
# 分布层
"ppo_kl": ppo_kl, # old vs current KL
"train_rollout_logprob_abs_diff": ..., # rollout vs train logprob 差异
# 动作空间层
"pg_clipfrac": pg_clipfrac, # PPO clip 比例
"ois": ..., # on-policy IS ratio
"tis": ..., # off-policy TIS ratio
"tis_clipfrac": ..., # TIS clip 比例
"tis_abs": ..., # TIS 绝对偏差
# KL 约束相关
"kl_loss": kl_loss, # ref KL loss
"opd_reverse_kl": ..., # 蒸馏 KL(可选)
# Off-policy 防护
"opsm_clipfrac": opsm_clipfrac, # OPSM mask 比例
}reported_loss = {
# 训练动态层
"loss": loss, # 总 loss
"pg_loss": pg_loss, # policy gradient loss
"entropy_loss": entropy_loss, # 策略熵
# 分布层
"ppo_kl": ppo_kl, # old vs current KL
"train_rollout_logprob_abs_diff": ..., # rollout vs train logprob 差异
# 动作空间层
"pg_clipfrac": pg_clipfrac, # PPO clip 比例
"ois": ..., # on-policy IS ratio
"tis": ..., # off-policy TIS ratio
"tis_clipfrac": ..., # TIS clip 比例
"tis_abs": ..., # TIS 绝对偏差
# KL 约束相关
"kl_loss": kl_loss, # ref KL loss
"opd_reverse_kl": ..., # 蒸馏 KL(可选)
# Off-policy 防护
"opsm_clipfrac": opsm_clipfrac, # OPSM mask 比例
}在实际运维中,一个常见的排查路径是:
- 先看
reward和pg_loss曲线是否正常 - 如果异常,看
pg_clipfrac——如果过高(>0.3),说明 ratio 偏移严重 - 再看
ppo_kl和train_rollout_logprob_abs_diff——定位是策略更新太快还是训推不一致 - 如果用了 TIS,看
tis_clipfrac——判断 off-policy 程度 - 最后看
entropy_loss——如果持续下降到接近零,可能是 entropy collapse
十九、一个最重要的工程心法:不要只盯算法名词,要盯”问题-位置-代价”¶
很多工程团队讨论 RL 时容易陷入一种模式:
- 这是不是 PPO 问题?
- 这是不是 KL 设计问题?
- 这是不是 reward model 问题?
这些问题当然重要,但更实用的问法通常是:
-
这个问题具体出现在链路的哪个位置?
- rollout 端?
- reward 端?
- trainer 重算端?
- loss 聚合端?
-
它破坏的是什么一致性?
- 分布一致性?
- 动作空间一致性?
- 参数子空间一致性?
-
它最终影响的是哪个训练量?
- reward?
- ratio?
- KL?
- entropy?
- 最终 benchmark?
当你能把一个问题按这三层讲清楚,很多”玄学调参”就会变成可分析、可验证的工程问题。
19.1 工程心法落地:一个典型的排查案例¶
假设你看到 pg_clipfrac 突然飙升到 0.5 以上:
- 定位位置:出在 trainer 重算端——ratio 偏大
- 检查一致性:
- 看
train_rollout_logprob_abs_diff:如果很大 → 训推不一致(框架差异 / MoE routing mismatch) - 看
ppo_kl:如果很大 → 策略更新太快(学习率/epoch 数问题) - 看
tis_clipfrac:如果很大 → off-policy 程度过高(异步训练延迟问题)
- 看
- 对应措施:
- 训推不一致 → 启用 R3(MoE)/ 减小 temperature 差异 / 对齐精度
- 策略更新太快 → 降低学习率 / 减少 epoch 数 / 增大 clip range
- off-policy 过高 → 启用 OPSM / 增大 TIS clip 范围 / 减少 rollout-train 异步延迟
二十、总结¶
如果把全文压缩成几句话,可以记住下面这套主线:
- 轨迹 是 RL 的基本样本单位;一条回答、一条 reasoning chain、一次 agent 多轮交互,本质上都是轨迹。
- 轨迹拆分 是为了做 credit assignment;你需要决定 reward 如何分配到 token、step、turn。
- Reward 告诉系统”什么是好”;但进入优化时,通常会先变成 return / advantage,而不是直接拿裸 reward 做梯度。
- IS / ratio 解决”旧样本如何服务当前策略”;概率比是 RL loss 的核心稳定性变量之一。
- KL 解决”别跑太远”;K3 通常只是 sampled KL 的一种 estimator / surrogate,不应和 KL 本体混为一谈。
- Entropy 解决”别太早失去探索”;过早熵塌缩会让策略陷入局部模式,尤其影响 reasoning RL。
- Loss 是多个目标的组合;Policy、Value、KL、Entropy 常常共同构成最终训练目标。
- 训推一致 是 RL Infra 的关键工程课题;很多脏信号来自 rollout 和 trainer 的不一致,而不只是公式本身。
- KSM 修的是 action space;training 侧不重新采样,但要在 rollout 的同一 sampling support 上重算 logprob。
- R3 / routing replay 修的是 parameter subspace;在 MoE 中,trainer 还要尽量复现 rollout 的 expert 路径。
对 RL Infra 工程师来说,真正重要的不是背下多少术语,而是建立这样一种能力:
看到任何一个训练现象,都能把它定位到”轨迹、reward、logprob、ratio、KL、entropy、mask、routing、loss”这条链上的具体位置。
这就是从”知道一些 RL 术语”走向”能够做 RL 系统工程”的分水岭。
附录:代码索引速查表¶
为方便读者快速定位源码,这里汇总本文涉及的所有关键代码位置:
A.1 slime 框架¶
| 概念 | 文件路径 | 关键函数/类 |
|---|---|---|
| 样本数据结构 | slime/utils/types.py | Sample dataclass |
| KL 估计器 (K1/K2/K3) | slime/utils/ppo_utils.py | compute_approx_kl() |
| OPSM (Off-Policy Masking) | slime/utils/ppo_utils.py | compute_opsm_mask() |
| GSPO 序列级 KL | slime/utils/ppo_utils.py | compute_gspo_kl() |
| PPO Clip Loss | slime/utils/ppo_utils.py | compute_policy_loss() |
| GRPO Returns | slime/utils/ppo_utils.py | get_grpo_returns() |
| REINFORCE++ Returns | slime/utils/ppo_utils.py | get_reinforce_plus_plus_returns() |
| GAE (vanilla + chunked) | slime/utils/ppo_utils.py | vanilla_gae(), chunked_gae() |
| Vocab-Parallel Entropy | slime/utils/ppo_utils.py | _VocabParallelEntropy |
| 总 Loss 组装 | slime/backends/megatron_utils/loss.py | policy_loss_function() |
| TIS / ICEPOP | slime/backends/megatron_utils/loss.py | vanilla_tis_function(), icepop_function() |
| Advantage + Returns | slime/backends/megatron_utils/loss.py | compute_advantages_and_returns() |
| Routing Replay (R3) | slime/utils/routing_replay.py | RoutingReplay, get_routing_replay_compute_topk() |
| Multi-Turn Loss Mask | slime/utils/mask_utils.py | MultiTurnLossMaskGenerator |
| Rollout Buffer | slime_plugins/rollout_buffer/buffer.py | RolloutBuffer |
| Rollout 生成 | slime/rollout/sglang_rollout.py | generate_rollout_async() |
| 训练主流程 | slime/backends/megatron_utils/actor.py | train_actor() |
A.2 verl 框架¶
| 概念 | 文件路径 | 关键函数/类 |
|---|---|---|
| Advantage 估计器枚举 | verl/trainer/ppo/core_algos.py | AdvantageEstimator enum |
| GAE Advantage | verl/trainer/ppo/core_algos.py | compute_gae_advantage_return() |
| GRPO Advantage | verl/trainer/ppo/core_algos.py | compute_grpo_outcome_advantage() |
| RLOO Advantage | verl/trainer/ppo/core_algos.py | compute_rloo_outcome_advantage() |
| Optimal Token Baseline | verl/trainer/ppo/core_algos.py | compute_optimal_token_baseline_advantage() |
| Vanilla PPO Loss | verl/trainer/ppo/core_algos.py | compute_policy_loss_vanilla() |
| DPPO-TV / DPPO-KL | verl/trainer/ppo/core_algos.py | compute_policy_loss_dppo_tv(), compute_policy_loss_dppo_kl() |
| GSPO Loss | verl/trainer/ppo/core_algos.py | compute_policy_loss_gspo() |
| CISPO Loss | verl/trainer/ppo/core_algos.py | compute_policy_loss_cispo() |
| Geometric Mean PPO | verl/trainer/ppo/core_algos.py | compute_policy_loss_geo_mean() |
| Value Loss (Critic) | verl/trainer/ppo/core_algos.py | compute_value_loss() |
| Loss 聚合 | verl/trainer/ppo/core_algos.py | agg_loss() |
| KL Penalty (K1/K2/K3/K3+) | verl/trainer/ppo/core_algos.py | kl_penalty(), kl_penalty_forward() |
| Adaptive KL Controller | verl/trainer/ppo/core_algos.py | AdaptiveKLController |
| Apply KL Penalty | verl/trainer/ppo/ray_trainer.py | apply_kl_penalty() |
| Compute Advantage 分发 | verl/trainer/ppo/ray_trainer.py | compute_advantage() |
| Entropy 计算 | verl/utils/torch_functional.py | entropy_from_logits() |
| Masked 统计 | verl/utils/torch_functional.py | masked_mean(), masked_whiten() |
| Response Mask | verl/utils/torch_functional.py | get_response_mask() |
| 训练主循环 | verl/trainer/ppo/ray_trainer.py | RayPPOTrainer |
参考资料¶
-
PPO: Proximal Policy Optimization Algorithms
https://arxiv.org/abs/1707.06347 -
On Computation and Design of KL Divergence for Reinforcement Learning and RLHF
https://arxiv.org/abs/2505.17508 -
Approximating KL Divergence(Schulman)
https://joschu.net/blog/kl-approx.html -
Understanding R1-Zero-Like Training: A Critical Perspective
https://arxiv.org/abs/2602.04417 -
Entropy Collapse in RL for Reasoning Language Models
https://arxiv.org/abs/2505.22617 -
Token-Level Reward Redistribution in RLHF
https://openreview.net/forum?id=w3d44iguZK -
Multi-turn Reinforcement Learning for Language Agents
https://openreview.net/forum?id=yPWJG9wgll -
R3 / Rollout Routing Replay 相关论文页面
https://arxiv.org/abs/2510.11370 -
DeepSeek-V3.2(含 Keep Sampling Mask 相关描述)
https://arxiv.org/abs/2512.02556 -
GRPO: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
https://arxiv.org/abs/2402.03300 -
RLOO: Back to Basics: Revisiting REINFORCE-Style Optimization for Learning from Human Feedback
https://arxiv.org/abs/2402.14740 -
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
https://arxiv.org/abs/2501.03262 -
DPPO: Dual-Clip PPO for Offline Reinforcement Learning
https://arxiv.org/abs/2602.04879 -
CISPO: Clipped Importance Sampling Policy Optimization
https://arxiv.org/abs/2506.13585 -
GDPO: Group Reward-Decoupled Normalization Policy Optimization
https://arxiv.org/abs/2504.02495 -
Optimal Token-Level Baseline (Pass@k)
https://arxiv.org/abs/2503.19595