1. 要解决的问题¶
在 LLM 推理的热路径(每次 forward 都会执行的代码)中,注意力计算、MoE 专家路由等模块需要大量临时张量(tensor)存放中间结果。如果每次都调用 torch.empty() 分配,会产生两个严重问题:
- CUDA malloc 延迟:即使 PyTorch 有缓存分配器(caching allocator),首次分配和碎片化场景下仍有不可忽视的开销
- 显存碎片化:反复分配/释放不同大小的 tensor,导致大块连续显存逐渐碎片化,最终可能 OOM
WorkspaceManager 的解决方案是:预分配一整块 GPU 显存,所有模块通过 view 复用这块内存,让热路径保持零分配。
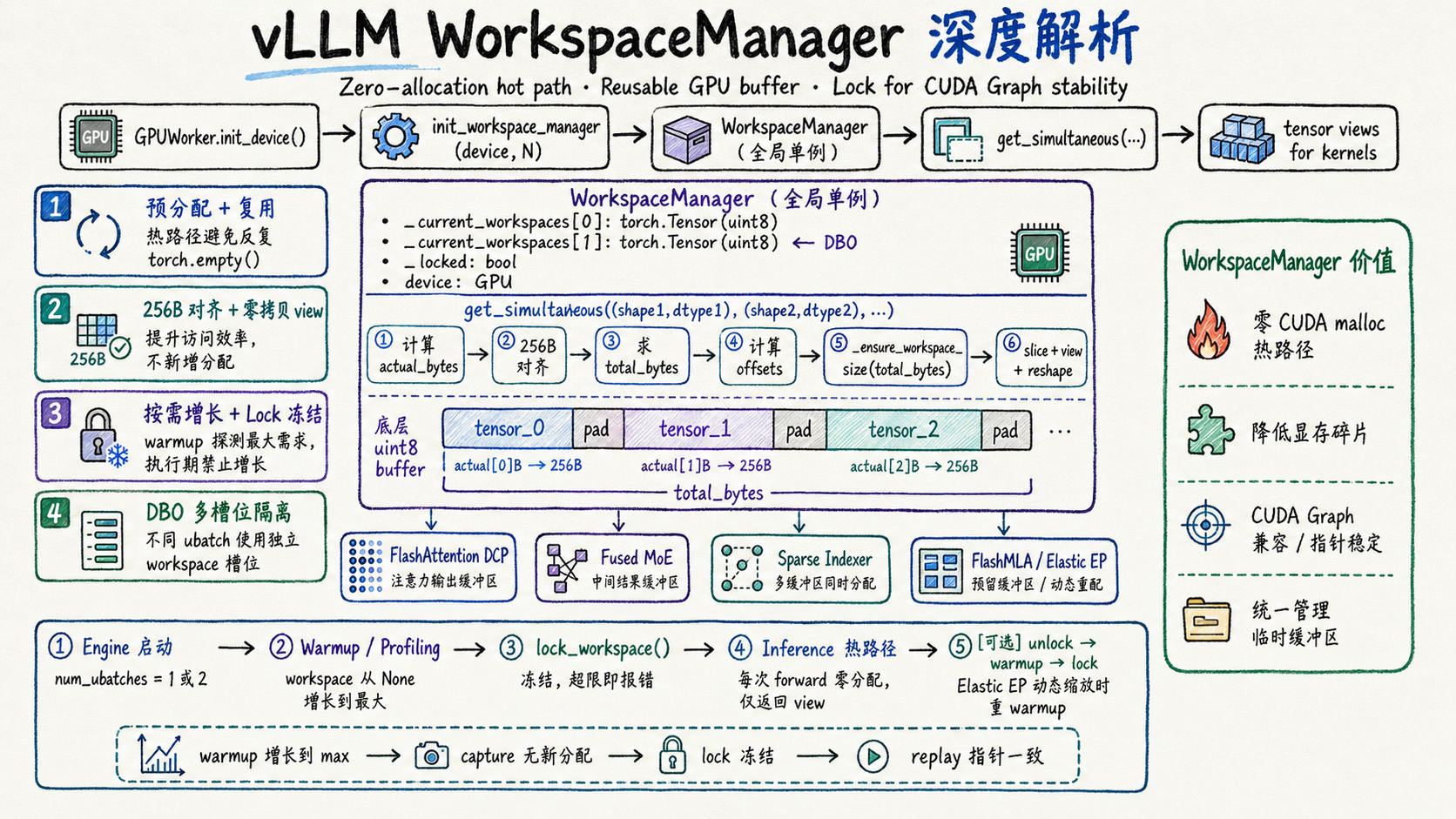
2. 整体架构¶
┌─────────────────────────────────────────────────────────────┐
│ GPUWorker.init_device() │
│ │ │
│ init_workspace_manager(device, N) │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ WorkspaceManager(全局单例) │ │
│ │ │ │
│ │ _current_workspaces[0]: torch.Tensor (uint8) │ │
│ │ _current_workspaces[1]: torch.Tensor (uint8) ← DBO │ │
│ │ _locked: bool │ │
│ │ │ │
│ │ get_simultaneous((shape1, dtype1), (shape2, dtype2)) │ │
│ │ → [tensor_view_1, tensor_view_2] │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ FlashAttn DCP Fused MoE Sparse Indexer ... │
│ (注意力输出缓冲区) (中间结果缓冲区) (FP8 key 缓冲区) │
└─────────────────────────────────────────────────────────────┘┌─────────────────────────────────────────────────────────────┐
│ GPUWorker.init_device() │
│ │ │
│ init_workspace_manager(device, N) │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ WorkspaceManager(全局单例) │ │
│ │ │ │
│ │ _current_workspaces[0]: torch.Tensor (uint8) │ │
│ │ _current_workspaces[1]: torch.Tensor (uint8) ← DBO │ │
│ │ _locked: bool │ │
│ │ │ │
│ │ get_simultaneous((shape1, dtype1), (shape2, dtype2)) │ │
│ │ → [tensor_view_1, tensor_view_2] │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ FlashAttn DCP Fused MoE Sparse Indexer ... │
│ (注意力输出缓冲区) (中间结果缓冲区) (FP8 key 缓冲区) │
└─────────────────────────────────────────────────────────────┘所有消费者都通过 current_workspace_manager().get_simultaneous(...) 获取临时缓冲区,彼此不需要知道对方的存在。每次 get_simultaneous 调用返回的 tensor 只在当前计算步骤内有效,下一次调用会覆盖同一块内存。
3. 实现原理¶
3.1 数据结构¶
# vllm/v1/worker/workspace.py
class WorkspaceManager:
def __init__(self, device: torch.device, num_ubatches: int | None = None):
self._device = device
self._num_ubatches = num_ubatches if num_ubatches is not None else 1
self._current_workspaces: list[torch.Tensor | None] = [
None
] * self._num_ubatches
self._locked: bool = False# vllm/v1/worker/workspace.py
class WorkspaceManager:
def __init__(self, device: torch.device, num_ubatches: int | None = None):
self._device = device
self._num_ubatches = num_ubatches if num_ubatches is not None else 1
self._current_workspaces: list[torch.Tensor | None] = [
None
] * self._num_ubatches
self._locked: bool = False| 字段 | 类型 | 说明 |
|---|---|---|
_device | torch.device | 缓冲区所在 GPU 设备 |
_num_ubatches | int | 微批次槽位数。非 DBO 模式 = 1,DBO 模式 = 2 |
_current_workspaces | list[Tensor | None] | 每个槽位一块 uint8 一维 tensor,按需延迟分配 |
_locked | bool | 锁定后禁止增长,违反则抛异常 |
底层缓冲区始终是一维 torch.uint8 tensor。它是一块“无类型”的原始字节流,通过 .view(dtype).reshape(shape) 变换成消费者需要的任意 dtype/shape。
3.2 核心分配算法:get_simultaneous¶
# vllm/v1/worker/workspace.py
def get_simultaneous(
self, *shapes_and_dtypes: tuple[tuple[int, ...], torch.dtype]
) -> list[torch.Tensor]:
# 1) 计算每个 tensor 的实际字节数
actual_bytes = [_compute_bytes(s, d) for s, d in shapes_and_dtypes]
# 2) 按 256 字节对齐(GPU 内存访问效率)
aligned_bytes = [round_up(actual, 256) for actual in actual_bytes]
# 3) 求总字节数
total_bytes = sum(aligned_bytes)
# 4) 计算每个 tensor 在缓冲区中的起始偏移
offsets = list(accumulate([0] + aligned_bytes[:-1]))
# 5) 确保底层缓冲区 >= total_bytes
current_workspace = self._ensure_workspace_size(total_bytes)
# 6) 切片 + view + reshape 返回多个 tensor view
return [
current_workspace[offsets[i] : offsets[i] + actual_bytes[i]]
.view(shapes_and_dtypes[i][1])
.reshape(shapes_and_dtypes[i][0])
for i in range(len(shapes_and_dtypes))
]# vllm/v1/worker/workspace.py
def get_simultaneous(
self, *shapes_and_dtypes: tuple[tuple[int, ...], torch.dtype]
) -> list[torch.Tensor]:
# 1) 计算每个 tensor 的实际字节数
actual_bytes = [_compute_bytes(s, d) for s, d in shapes_and_dtypes]
# 2) 按 256 字节对齐(GPU 内存访问效率)
aligned_bytes = [round_up(actual, 256) for actual in actual_bytes]
# 3) 求总字节数
total_bytes = sum(aligned_bytes)
# 4) 计算每个 tensor 在缓冲区中的起始偏移
offsets = list(accumulate([0] + aligned_bytes[:-1]))
# 5) 确保底层缓冲区 >= total_bytes
current_workspace = self._ensure_workspace_size(total_bytes)
# 6) 切片 + view + reshape 返回多个 tensor view
return [
current_workspace[offsets[i] : offsets[i] + actual_bytes[i]]
.view(shapes_and_dtypes[i][1])
.reshape(shapes_and_dtypes[i][0])
for i in range(len(shapes_and_dtypes))
]内存布局示意(假设请求 3 个 tensor):
底层 uint8 缓冲区:
┌──────────────┬─pad─┬──────────────┬─pad─┬──────────────┬─pad─┐
│ tensor_0 │align│ tensor_1 │align│ tensor_2 │align│
│ actual[0]B │→256B│ actual[1]B │→256B│ actual[2]B │→256B│
└──────────────┴─────┴──────────────┴─────┴──────────────┴─────┘
│← aligned[0] →│ │← aligned[1] →│ │← aligned[2] →│
│←────────────────── total_bytes ──────────────────────────────→│底层 uint8 缓冲区:
┌──────────────┬─pad─┬──────────────┬─pad─┬──────────────┬─pad─┐
│ tensor_0 │align│ tensor_1 │align│ tensor_2 │align│
│ actual[0]B │→256B│ actual[1]B │→256B│ actual[2]B │→256B│
└──────────────┴─────┴──────────────┴─────┴──────────────┴─────┘
│← aligned[0] →│ │← aligned[1] →│ │← aligned[2] →│
│←────────────────── total_bytes ──────────────────────────────→│关键点:
- 每个子 tensor 按 256 字节对齐,确保 GPU 内存访问不会因为未对齐地址产生额外开销
- 返回的是 view(零拷贝),不产生新的内存分配
- 多个 tensor 同时从一块连续内存中切出,无需多次调用分配器(allocator)
3.3 按需增长机制:_ensure_workspace_size¶
# vllm/v1/worker/workspace.py
def _ensure_workspace_size(self, required_bytes: int) -> torch.Tensor:
# ① 通过当前线程 ID 找到对应的 ubatch 槽位
ubatch_id = dbo_current_ubatch_id()
current_workspace = self._current_workspaces[ubatch_id]
current_size = self._workspace_size_bytes(current_workspace)
if current_size < required_bytes:
# ② 如果已锁定,拒绝增长并报错(含调用者溯源)
if self._locked:
raise AssertionError(
f"Workspace is locked but allocation from "
f"'{get_caller_info()}' requires ..."
)
# ③ 同步扩容所有 ubatch 槽位
for ubatch_id in range(self._num_ubatches):
current_workspace = self._current_workspaces[ubatch_id]
if ... < required_bytes:
# 关键:先删旧 tensor,再建新 tensor
self._current_workspaces[ubatch_id] = None
del current_workspace
self._current_workspaces[ubatch_id] = torch.empty(
(required_bytes,), dtype=torch.uint8, device=self._device
)
return current_workspace# vllm/v1/worker/workspace.py
def _ensure_workspace_size(self, required_bytes: int) -> torch.Tensor:
# ① 通过当前线程 ID 找到对应的 ubatch 槽位
ubatch_id = dbo_current_ubatch_id()
current_workspace = self._current_workspaces[ubatch_id]
current_size = self._workspace_size_bytes(current_workspace)
if current_size < required_bytes:
# ② 如果已锁定,拒绝增长并报错(含调用者溯源)
if self._locked:
raise AssertionError(
f"Workspace is locked but allocation from "
f"'{get_caller_info()}' requires ..."
)
# ③ 同步扩容所有 ubatch 槽位
for ubatch_id in range(self._num_ubatches):
current_workspace = self._current_workspaces[ubatch_id]
if ... < required_bytes:
# 关键:先删旧 tensor,再建新 tensor
self._current_workspaces[ubatch_id] = None
del current_workspace
self._current_workspaces[ubatch_id] = torch.empty(
(required_bytes,), dtype=torch.uint8, device=self._device
)
return current_workspace扩容策略有三个关键设计。
3.3.1 先删后建(避免显存尖峰)¶
# 不能用 resize_(),因为它会先分配新内存再释放旧内存
# 峰值显存 = old_size + new_size(可能导致 OOM)
#
# 而是:先释放旧的,再分配新的
# 峰值显存 = max(old_size, new_size) = new_size
self._current_workspaces[ubatch_id] = None # 断开 list 中的引用
del current_workspace # 释放局部变量引用 → tensor 被回收
self._current_workspaces[ubatch_id] = torch.empty(...) # 分配新 tensor# 不能用 resize_(),因为它会先分配新内存再释放旧内存
# 峰值显存 = old_size + new_size(可能导致 OOM)
#
# 而是:先释放旧的,再分配新的
# 峰值显存 = max(old_size, new_size) = new_size
self._current_workspaces[ubatch_id] = None # 断开 list 中的引用
del current_workspace # 释放局部变量引用 → tensor 被回收
self._current_workspaces[ubatch_id] = torch.empty(...) # 分配新 tensor3.3.2 所有 ubatch 槽位同步扩容¶
当某个槽位需要更大的空间时,遍历所有槽位,将不够大的全部扩容到同一大小。这保证了不同微批次线程看到的缓冲区容量一致。
3.3.3 调用者溯源(get_caller_info)¶
当锁定后仍有扩容请求时,通过 inspect.currentframe() 逐帧回溯栈,跳过 WorkspaceManager 自身的帧,找到外部调用者的文件名、行号和函数名,并写入异常信息。这样可以直接定位:哪个模块在执行阶段试图分配超限的 workspace。
3.4 Lock 冻结机制¶
# vllm/v1/worker/workspace.py
def lock(self) -> None:
self._locked = True
def unlock(self) -> None:
self._locked = False# vllm/v1/worker/workspace.py
def lock(self) -> None:
self._locked = True
def unlock(self) -> None:
self._locked = FalseLock 机制的核心思想是两阶段执行:
Warmup / Profiling 阶段 Execution 阶段
┌──────────────────────────────┐ ┌──────────────────────────┐
│ │ │ │
│ workspace 允许增长 │ │ workspace 禁止增长 │
│ │ │ │
│ 各模块首次调用 │ │ 所有调用必须 ≤ 已有大小 │
│ get_simultaneous() │ │ 否则抛 AssertionError │
│ → 缓冲区按需扩容到最大需求 │ │ │
│ │ │ → 零分配开销 │
│ │ │ → 确定性显存占用 │
└──────────────┬───────────────┘ └──────────────────────────┘
│
lock_workspace() Warmup / Profiling 阶段 Execution 阶段
┌──────────────────────────────┐ ┌──────────────────────────┐
│ │ │ │
│ workspace 允许增长 │ │ workspace 禁止增长 │
│ │ │ │
│ 各模块首次调用 │ │ 所有调用必须 ≤ 已有大小 │
│ get_simultaneous() │ │ 否则抛 AssertionError │
│ → 缓冲区按需扩容到最大需求 │ │ │
│ │ │ → 零分配开销 │
│ │ │ → 确定性显存占用 │
└──────────────┬───────────────┘ └──────────────────────────┘
│
lock_workspace()Warmup 阶段会用最大 batch size“试运行”模型,触发所有模块的 get_simultaneous 调用,使缓冲区增长到足够大。之后 lock_workspace() 冻结,保证执行阶段零分配、零碎片、确定性显存。
3.5 DBO 多槽位隔离¶
DBO(Dual Batch Overlap)是 vLLM 的计算-通信交叠优化:将一个 batch 拆成两个微批次,在两个线程中交替执行计算和通信,实现流水线并行。
WorkspaceManager 对此的支持:
# vllm/v1/worker/ubatching.py
_THREAD_ID_TO_CONTEXT: dict = {} # thread_id → ubatch_id
def dbo_current_ubatch_id() -> int:
if len(_THREAD_ID_TO_CONTEXT) == 0:
return 0 # 非 DBO 模式,始终返回 0
return _THREAD_ID_TO_CONTEXT[threading.get_ident()]# vllm/v1/worker/ubatching.py
_THREAD_ID_TO_CONTEXT: dict = {} # thread_id → ubatch_id
def dbo_current_ubatch_id() -> int:
if len(_THREAD_ID_TO_CONTEXT) == 0:
return 0 # 非 DBO 模式,始终返回 0
return _THREAD_ID_TO_CONTEXT[threading.get_ident()]Thread A (ubatch 0) Thread B (ubatch 1)
│ │
│ dbo_current_ubatch_id() → 0 │ dbo_current_ubatch_id() → 1
│ │ │ │
│ ▼ │ ▼
│ _current_workspaces[0] │ _current_workspaces[1]
│ (独立的 uint8 缓冲区) │ (独立的 uint8 缓冲区)
│ │
│ stream_0 上执行计算 │ stream_1 上执行通信
└──────────────────────────────────┘Thread A (ubatch 0) Thread B (ubatch 1)
│ │
│ dbo_current_ubatch_id() → 0 │ dbo_current_ubatch_id() → 1
│ │ │ │
│ ▼ │ ▼
│ _current_workspaces[0] │ _current_workspaces[1]
│ (独立的 uint8 缓冲区) │ (独立的 uint8 缓冲区)
│ │
│ stream_0 上执行计算 │ stream_1 上执行通信
└──────────────────────────────────┘两个线程各用各的缓冲区,互不干扰,无需加锁(每个线程只读写自己的槽位)。
3.6 全局单例管理¶
# vllm/v1/worker/workspace.py
_manager: "WorkspaceManager | None" = None
def init_workspace_manager(device, num_ubatches=None):
"""初始化。由 GPUWorker.init_device() 调用"""
global _manager
_manager = WorkspaceManager(device, num_ubatches)
def current_workspace_manager() -> WorkspaceManager:
"""获取。所有消费者通过此函数拿到单例"""
assert _manager is not None
return _manager
def lock_workspace():
"""锁定。由 GPUModelRunner warmup 完成后调用"""
current_workspace_manager().lock()
def unlock_workspace():
"""解锁。仅在 Elastic EP 动态缩放场景下使用"""
current_workspace_manager().unlock()
def reset_workspace_manager():
"""重置。仅用于测试"""
global _manager
_manager = None
def is_workspace_manager_initialized() -> bool:
"""检查是否已初始化"""
return _manager is not None# vllm/v1/worker/workspace.py
_manager: "WorkspaceManager | None" = None
def init_workspace_manager(device, num_ubatches=None):
"""初始化。由 GPUWorker.init_device() 调用"""
global _manager
_manager = WorkspaceManager(device, num_ubatches)
def current_workspace_manager() -> WorkspaceManager:
"""获取。所有消费者通过此函数拿到单例"""
assert _manager is not None
return _manager
def lock_workspace():
"""锁定。由 GPUModelRunner warmup 完成后调用"""
current_workspace_manager().lock()
def unlock_workspace():
"""解锁。仅在 Elastic EP 动态缩放场景下使用"""
current_workspace_manager().unlock()
def reset_workspace_manager():
"""重置。仅用于测试"""
global _manager
_manager = None
def is_workspace_manager_initialized() -> bool:
"""检查是否已初始化"""
return _manager is not None4. 生命周期¶
Engine 启动
│
├─① GPUWorker.init_device()
│ │
│ │ num_ubatches = 2 if enable_dbo else 1
│ └─ init_workspace_manager(device, num_ubatches)
│ # 源码: vllm/v1/worker/gpu_worker.py
│ # 此时 _current_workspaces = [None] 或 [None, None]
│
├─② Warmup / Profiling / CUDA Graph Capture
│ │
│ ├─ FlashAttn DCP 首次 forward → get_simultaneous(...)
│ │ → workspace 从 None 增长到 X MB
│ │
│ ├─ Fused MoE 首次 forward → get_simultaneous(...)
│ │ → workspace 从 X MB 增长到 Y MB(若 Y > X)
│ │
│ ├─ Sparse Indexer 首次 forward → get_simultaneous(...)
│ │ → workspace 保持 Y MB(若需求 ≤ Y)
│ │
│ └─ ... 所有模块都“试运行”过一遍
│
├─③ lock_workspace()
│ # 源码: vllm/v1/worker/gpu_model_runner.py
│ # 冻结!此后任何超限分配都会抛异常
│
├─④ 推理执行(热路径)
│ │
│ │ 每次 forward:
│ │ get_simultaneous(...) → 直接返回 view(零分配)
│ │ 计算完成 → tensor view 自然失效(下次会被覆盖)
│ │
│ └─ 循环执行,workspace 大小不再变化
│
└─⑤ [可选] Elastic EP 动态缩放
│ # 源码: vllm/distributed/elastic_ep/elastic_execute.py
├─ unlock_workspace() ← 解锁允许增长
├─ worker.compile_or_warm_up_model() ← 重新 warmup
└─ lock_workspace() ← 再次锁定Engine 启动
│
├─① GPUWorker.init_device()
│ │
│ │ num_ubatches = 2 if enable_dbo else 1
│ └─ init_workspace_manager(device, num_ubatches)
│ # 源码: vllm/v1/worker/gpu_worker.py
│ # 此时 _current_workspaces = [None] 或 [None, None]
│
├─② Warmup / Profiling / CUDA Graph Capture
│ │
│ ├─ FlashAttn DCP 首次 forward → get_simultaneous(...)
│ │ → workspace 从 None 增长到 X MB
│ │
│ ├─ Fused MoE 首次 forward → get_simultaneous(...)
│ │ → workspace 从 X MB 增长到 Y MB(若 Y > X)
│ │
│ ├─ Sparse Indexer 首次 forward → get_simultaneous(...)
│ │ → workspace 保持 Y MB(若需求 ≤ Y)
│ │
│ └─ ... 所有模块都“试运行”过一遍
│
├─③ lock_workspace()
│ # 源码: vllm/v1/worker/gpu_model_runner.py
│ # 冻结!此后任何超限分配都会抛异常
│
├─④ 推理执行(热路径)
│ │
│ │ 每次 forward:
│ │ get_simultaneous(...) → 直接返回 view(零分配)
│ │ 计算完成 → tensor view 自然失效(下次会被覆盖)
│ │
│ └─ 循环执行,workspace 大小不再变化
│
└─⑤ [可选] Elastic EP 动态缩放
│ # 源码: vllm/distributed/elastic_ep/elastic_execute.py
├─ unlock_workspace() ← 解锁允许增长
├─ worker.compile_or_warm_up_model() ← 重新 warmup
└─ lock_workspace() ← 再次锁定5. 使用场景¶
WorkspaceManager 被以下场景使用:
| 场景 | 消费模块 | 源码位置 | 分配的缓冲区 |
|---|---|---|---|
| DCP 注意力计算 | FlashAttnImpl | vllm/v1/attention/backends/flash_attn.py | context 输出、query 输出 |
| MLA 稀疏注意力 | FlashMLASparseImpl | vllm/v1/attention/backends/mla/flashmla_sparse.py | Q 拼接缓冲区、prefill workspace |
| MoE 专家路由 | FusedMoEModularKernel | vllm/model_executor/layers/fused_moe/modular_kernel.py | GEMM 中间结果(workspace13、workspace2、fused_out) |
| 稀疏注意力索引 | sparse_attn_indexer | vllm/model_executor/layers/sparse_attn_indexer.py | FP8 key 缓冲区、scale 缓冲区、topk workspace |
| Elastic EP 缩放 | elastic_execute | vllm/distributed/elastic_ep/elastic_execute.py | 无直接分配,仅 unlock/lock |
| 测试 fixture | conftest.py | tests/conftest.py | 测试环境初始化/重置 |
| Benchmark 脚本 | benchmark_*.py | benchmarks/ | 基准测试初始化 |
6. 使用案例分析¶
6.1 案例一:FlashAttention DCP 注意力输出缓冲区¶
场景:DCP(Disaggregated Context Parallelism)模式下,FlashAttention 需要两个临时缓冲区分别存储 context 注意力输出和 query 注意力输出。
源码:vllm/v1/attention/backends/flash_attn.py
# 第一次调用:分配 context 注意力输出缓冲区
n = query_across_dcp.shape[0]
(dcp_context_out,) = current_workspace_manager().get_simultaneous(
(
(n, self.num_heads * self.dcp_world_size, self.head_size),
self._dcp_dtype,
),
)
# dcp_context_out 作为 out= 参数传给 flash_attn_varlen_func
context_attn_out, context_lse = flash_attn_varlen_func(
q=query_across_dcp, ..., out=dcp_context_out, ...
)
# 第二次调用:分配 query 注意力输出缓冲区
# 注意:这会覆盖上面的 dcp_context_out 的底层内存!
# 因为 context_attn_out 已经消费完毕,内存可以复用
(dcp_query_out,) = current_workspace_manager().get_simultaneous(
((query.shape[0], self.num_heads, self.head_size), self._dcp_dtype),
)
query_attn_out, query_lse = flash_attn_varlen_func(
q=query, ..., out=dcp_query_out, ...
)# 第一次调用:分配 context 注意力输出缓冲区
n = query_across_dcp.shape[0]
(dcp_context_out,) = current_workspace_manager().get_simultaneous(
(
(n, self.num_heads * self.dcp_world_size, self.head_size),
self._dcp_dtype,
),
)
# dcp_context_out 作为 out= 参数传给 flash_attn_varlen_func
context_attn_out, context_lse = flash_attn_varlen_func(
q=query_across_dcp, ..., out=dcp_context_out, ...
)
# 第二次调用:分配 query 注意力输出缓冲区
# 注意:这会覆盖上面的 dcp_context_out 的底层内存!
# 因为 context_attn_out 已经消费完毕,内存可以复用
(dcp_query_out,) = current_workspace_manager().get_simultaneous(
((query.shape[0], self.num_heads, self.head_size), self._dcp_dtype),
)
query_attn_out, query_lse = flash_attn_varlen_func(
q=query, ..., out=dcp_query_out, ...
)分析:
- 两次
get_simultaneous调用各分配 1 个 tensor - 第二次调用会覆盖第一次的底层内存,因为它们共享同一个 workspace 缓冲区
- 这是安全的,因为
context_attn_out在第二次调用前已经被dcp_combine消费完毕 - 避免了两块大型注意力输出 tensor 同时驻留显存
6.2 案例二:Fused MoE 层中间缓冲区复用¶
场景:MoE(Mixture of Experts)层的 fused GEMM 计算需要多个中间缓冲区。get_simultaneous 一次性切出这些缓冲区,再利用生命周期不重叠的特性复用内存。
源码:vllm/model_executor/layers/fused_moe/modular_kernel.py
# 计算三种 workspace 的 shape
workspace13_shape, workspace2_shape, _ = self.fused_experts.workspace_shapes(
M_chunk, N, K, top_k, ...)
_, _, fused_out_shape = self.fused_experts.workspace_shapes(
M_full, N, K, top_k, ...)
# 关键复用:workspace13 和 fused_out 共享底层内存
# 因为 cache1(前半段计算)用完后才需要 cache3(后半段)和 fused_out
max_shape_size = max(prod(workspace13_shape), prod(fused_out_shape))
common_workspace, workspace2 = current_workspace_manager().get_simultaneous(
((max_shape_size,), workspace_dtype), # 共享区域
(workspace2_shape, workspace_dtype), # 独立区域
)
# 通过 view 获得两个不同形状的“虚拟” tensor
workspace13 = _resize_cache(common_workspace, workspace13_shape)
fused_out = _resize_cache(common_workspace, fused_out_shape)# 计算三种 workspace 的 shape
workspace13_shape, workspace2_shape, _ = self.fused_experts.workspace_shapes(
M_chunk, N, K, top_k, ...)
_, _, fused_out_shape = self.fused_experts.workspace_shapes(
M_full, N, K, top_k, ...)
# 关键复用:workspace13 和 fused_out 共享底层内存
# 因为 cache1(前半段计算)用完后才需要 cache3(后半段)和 fused_out
max_shape_size = max(prod(workspace13_shape), prod(fused_out_shape))
common_workspace, workspace2 = current_workspace_manager().get_simultaneous(
((max_shape_size,), workspace_dtype), # 共享区域
(workspace2_shape, workspace_dtype), # 独立区域
)
# 通过 view 获得两个不同形状的“虚拟” tensor
workspace13 = _resize_cache(common_workspace, workspace13_shape)
fused_out = _resize_cache(common_workspace, fused_out_shape)分析:
- 一次
get_simultaneous调用分配 2 个 tensor:common_workspace和workspace2 common_workspace被进一步 view 成workspace13和fused_out,二者共享同一块内存- 这是安全的,因为
workspace13(cache1 + cache3)和fused_out的生命周期不重叠 - 内存布局:
[common_workspace (max_size) | pad | workspace2] - 三个逻辑缓冲区只占用两块物理内存,节省显存
6.3 案例三:Sparse Attention Indexer 多缓冲区同时分配¶
场景:稀疏注意力索引器在 profiling 阶段和推理阶段会以不同方式调用 workspace。
源码:vllm/model_executor/layers/sparse_attn_indexer.py
# ① Profiling 阶段:预留最大所需大小
if not isinstance(attn_metadata, dict):
# 一次性预留 3 个缓冲区,确保 workspace 增长到足够大
current_workspace_manager().get_simultaneous(
((total_seq_lens, head_dim), torch.float8_e4m3fn), # FP8 key
((total_seq_lens, 4), torch.uint8), # scale
((RADIX_TOPK_WORKSPACE_SIZE,), torch.uint8), # topk
)
return ...
# ② 推理阶段 - prefill 路径:只需要 FP8 key 和 scale
workspace_manager = current_workspace_manager()
k_fp8_full, k_scale_full = workspace_manager.get_simultaneous(
((total_seq_lens, head_dim), fp8_dtype),
((total_seq_lens, 4), torch.uint8),
)
for chunk in prefill_metadata.chunks:
k_fp8 = k_fp8_full[: chunk.total_seq_lens] # 切片使用子集
k_scale = k_scale_full[: chunk.total_seq_lens]
...
# ③ 推理阶段 - decode 路径:只需要 topk workspace
(topk_workspace,) = workspace_manager.get_simultaneous(
((RADIX_TOPK_WORKSPACE_SIZE,), torch.uint8),
)
torch.ops._C.persistent_topk(logits, seq_lens, ..., topk_workspace, ...)# ① Profiling 阶段:预留最大所需大小
if not isinstance(attn_metadata, dict):
# 一次性预留 3 个缓冲区,确保 workspace 增长到足够大
current_workspace_manager().get_simultaneous(
((total_seq_lens, head_dim), torch.float8_e4m3fn), # FP8 key
((total_seq_lens, 4), torch.uint8), # scale
((RADIX_TOPK_WORKSPACE_SIZE,), torch.uint8), # topk
)
return ...
# ② 推理阶段 - prefill 路径:只需要 FP8 key 和 scale
workspace_manager = current_workspace_manager()
k_fp8_full, k_scale_full = workspace_manager.get_simultaneous(
((total_seq_lens, head_dim), fp8_dtype),
((total_seq_lens, 4), torch.uint8),
)
for chunk in prefill_metadata.chunks:
k_fp8 = k_fp8_full[: chunk.total_seq_lens] # 切片使用子集
k_scale = k_scale_full[: chunk.total_seq_lens]
...
# ③ 推理阶段 - decode 路径:只需要 topk workspace
(topk_workspace,) = workspace_manager.get_simultaneous(
((RADIX_TOPK_WORKSPACE_SIZE,), torch.uint8),
)
torch.ops._C.persistent_topk(logits, seq_lens, ..., topk_workspace, ...)分析:
- Profiling 阶段(①)请求 3 个缓冲区同时分配,目的是让 workspace 增长到能同时容纳三者的大小
- 推理阶段的 prefill(②)和 decode(③)路径各自只需要部分缓冲区
- 因为在 profiling 阶段已经分配了足够大的空间,推理阶段的调用不会触发任何新的内存分配
k_fp8_full[: chunk.total_seq_lens]展示了一种常见模式:从 workspace 获取最大尺寸的缓冲区,每次使用时切片取实际需要的部分
6.4 案例四:FlashMLA Sparse 初始化时预留缓冲区¶
场景:FlashMLA Sparse 在 __init__ 阶段就通过 workspace 预留缓冲区,并将其保存为实例属性长期持有。
源码:vllm/v1/attention/backends/mla/flashmla_sparse.py
class FlashMLASparseImpl:
def __init__(self, ...):
q_concat_shape = (max_tokens, num_heads, head_size)
if kv_cache_dtype == "fp8_ds_mla":
# FP8 模式:需要 Q 拼接缓冲区 + prefill 工作缓冲区
self.q_concat_buffer, self.prefill_bf16_workspace = (
current_workspace_manager().get_simultaneous(
(q_concat_shape, torch.bfloat16),
(self.prefill_workspace_shape, torch.bfloat16),
)
)
else:
# BF16 模式:只需要 Q 拼接缓冲区
(self.q_concat_buffer,) = current_workspace_manager().get_simultaneous(
(q_concat_shape, torch.bfloat16),
)class FlashMLASparseImpl:
def __init__(self, ...):
q_concat_shape = (max_tokens, num_heads, head_size)
if kv_cache_dtype == "fp8_ds_mla":
# FP8 模式:需要 Q 拼接缓冲区 + prefill 工作缓冲区
self.q_concat_buffer, self.prefill_bf16_workspace = (
current_workspace_manager().get_simultaneous(
(q_concat_shape, torch.bfloat16),
(self.prefill_workspace_shape, torch.bfloat16),
)
)
else:
# BF16 模式:只需要 Q 拼接缓冲区
(self.q_concat_buffer,) = current_workspace_manager().get_simultaneous(
(q_concat_shape, torch.bfloat16),
)分析:
- 在
__init__中调用get_simultaneous,返回的 view 被保存为self.q_concat_buffer - 这些 view 指向 workspace 缓冲区内部,后续其他模块的
get_simultaneous调用会覆盖同一块内存 - 这是安全的:因为
q_concat_buffer只在 forward 的计算窗口内使用,而该窗口内不会有其他模块竞争 workspace - 在
__init__阶段调用还有一个好处:触发 workspace 增长,确保 warmup 阶段能探测到正确的最大需求
6.5 案例五:Elastic EP 动态缩放时解锁/重锁¶
场景:Elastic Expert Parallelism 在运行时动态调整 Expert 数量,需要重新 warmup。此时必须临时解锁 workspace。
源码:vllm/distributed/elastic_ep/elastic_execute.py
# Elastic EP 动态缩放
# 保存 block table 状态
saved_block_tables = [...]
multi_block_table.clear()
# 解锁 → 重新 warmup → 重新锁定
unlock_workspace() # workspace 允许增长
self.worker.compile_or_warm_up_model() # 重新 warmup(可能触发扩容)
lock_workspace() # 再次冻结
# 恢复 block table 状态
for bt, (saved_gpu, saved_cpu) in zip(...):
bt.block_table.gpu.copy_(saved_gpu)
bt.block_table.cpu.copy_(saved_cpu)# Elastic EP 动态缩放
# 保存 block table 状态
saved_block_tables = [...]
multi_block_table.clear()
# 解锁 → 重新 warmup → 重新锁定
unlock_workspace() # workspace 允许增长
self.worker.compile_or_warm_up_model() # 重新 warmup(可能触发扩容)
lock_workspace() # 再次冻结
# 恢复 block table 状态
for bt, (saved_gpu, saved_cpu) in zip(...):
bt.block_table.gpu.copy_(saved_gpu)
bt.block_table.cpu.copy_(saved_cpu)分析:
- 正常运行时 workspace 是锁定的
- Expert 数量变化后,MoE 层可能需要更大的中间缓冲区
unlock → warmup → lock三步操作允许 workspace 安全增长- warmup 完成后立即重新锁定,恢复确定性显存保证
7. 环境变量与调试¶
| 环境变量 | 默认值 | 说明 |
|---|---|---|
VLLM_DEBUG_WORKSPACE | 0 | 设为 1 开启 workspace 分配的详细日志 |
开启后会在三个位置输出日志:
1) 扩容时(_ensure_workspace_size 中):
[WORKSPACE DEBUG] Resized workspace from 'modular_kernel.py:forward':
0.00 MB -> 12.50 MB (2 ubatches, total memory 25.00 MB)[WORKSPACE DEBUG] Resized workspace from 'modular_kernel.py:forward':
0.00 MB -> 12.50 MB (2 ubatches, total memory 25.00 MB)2) 锁定时(lock() 中):
[WORKSPACE DEBUG] Workspace locked. Current sizes: [12.50, 12.50][WORKSPACE DEBUG] Workspace locked. Current sizes: [12.50, 12.50]3) 解锁时(unlock() 中):
[WORKSPACE DEBUG] Workspace unlocked. Current sizes: [12.50, 12.50][WORKSPACE DEBUG] Workspace unlocked. Current sizes: [12.50, 12.50]Lock 违规时的错误信息(含调用者溯源):
AssertionError: Workspace is locked but allocation from
'sparse_attn_indexer.py:build_sparse_attn_index' requires 25.00 MB,
current size is 12.50 MB. Workspace growth is not allowed after locking.AssertionError: Workspace is locked but allocation from
'sparse_attn_indexer.py:build_sparse_attn_index' requires 25.00 MB,
current size is 12.50 MB. Workspace growth is not allowed after locking.8. 与 CUDA Graph 的兼容性¶
CUDA Graph 在捕获(capture)阶段录制 GPU kernel 序列及其参数,包括 tensor 的 data_ptr();回放(replay)阶段则直接复用这些记录。这要求所有被录入 graph 的 tensor 指针在 capture 和 replay 之间保持不变。WorkspaceManager 的“warmup 探测 + lock 冻结”两阶段设计,本质上就是为满足这一需求服务的。
8.1 时序保证:Warmup 先于 Capture¶
_warmup_and_capture 方法(vllm/v1/worker/gpu_model_runner.py)展示了关键时序:
def _warmup_and_capture(self, desc, cudagraph_runtime_mode, ...):
# ① 先 warmup N 次(CUDAGraphMode.NONE,不录图)
for _ in range(num_warmups):
self._dummy_run(desc.num_tokens,
cudagraph_runtime_mode=CUDAGraphMode.NONE, ...)
# ② 最后一次才真正录图
self._dummy_run(desc.num_tokens,
cudagraph_runtime_mode=cudagraph_runtime_mode,
is_graph_capturing=True, ...)def _warmup_and_capture(self, desc, cudagraph_runtime_mode, ...):
# ① 先 warmup N 次(CUDAGraphMode.NONE,不录图)
for _ in range(num_warmups):
self._dummy_run(desc.num_tokens,
cudagraph_runtime_mode=CUDAGraphMode.NONE, ...)
# ② 最后一次才真正录图
self._dummy_run(desc.num_tokens,
cudagraph_runtime_mode=cudagraph_runtime_mode,
is_graph_capturing=True, ...)Warmup 阶段(①)以 CUDAGraphMode.NONE 执行 eager 路径,触发各模块的 get_simultaneous() 调用,使 workspace 增长到最大所需大小。当进入真正的 graph capture(②)时,workspace 底层 tensor 已经足够大,_ensure_workspace_size 走 current_size >= required_bytes 的快路径,直接返回已有 tensor,不分配新内存。
因此 capture 时录入的 data_ptr(),就是后续 replay 时使用的同一块内存的地址。
8.2 Lock 保证 Replay 时指针永不变¶
capture_model() 方法内部:
set_cudagraph_capturing_enabled(True)
with graph_capture(device=self.device):
for batch_descs in capture_descs:
_capture_cudagraphs(batch_descs, ...) ← warmup + capture
...
set_cudagraph_capturing_enabled(False)
torch.accelerator.synchronize()
torch.accelerator.empty_cache()
lock_workspace() ← 所有 capture 完成后立即冻结capture_model() 方法内部:
set_cudagraph_capturing_enabled(True)
with graph_capture(device=self.device):
for batch_descs in capture_descs:
_capture_cudagraphs(batch_descs, ...) ← warmup + capture
...
set_cudagraph_capturing_enabled(False)
torch.accelerator.synchronize()
torch.accelerator.empty_cache()
lock_workspace() ← 所有 capture 完成后立即冻结源码 vllm/v1/worker/gpu_model_runner.py 在所有 graph capture 完成后立即 lock_workspace()。Lock 之后,任何扩容请求都会抛 AssertionError。这从根本上杜绝了 replay 期间 workspace 缓冲区被重新分配,也就避免了 data_ptr() 改变。
8.3 Prefill 与 Decode 不冲突¶
Prefill(不录图)和 decode(录图)虽然可能请求不同大小的 workspace,但不存在指针冲突:
一个 forward step(不在 graph 内的 prefill 部分):
get_simultaneous((shape_P, dtype))
→ view 到 buffer[0 : X]
→ 计算完毕,view 失效
同一 forward step(在 graph 内的 decode 部分):
get_simultaneous((shape_D, dtype))
→ view 到 buffer[0 : Y](覆盖前一个 view 的内存区域)
→ 计算完毕,view 失效一个 forward step(不在 graph 内的 prefill 部分):
get_simultaneous((shape_P, dtype))
→ view 到 buffer[0 : X]
→ 计算完毕,view 失效
同一 forward step(在 graph 内的 decode 部分):
get_simultaneous((shape_D, dtype))
→ view 到 buffer[0 : Y](覆盖前一个 view 的内存区域)
→ 计算完毕,view 失效关键点:
- 同一个 buffer:
get_simultaneous每次都从 offset 0 开始切分(offsets = list(accumulate([0] + ...))),不论是 prefill 还是 decode,都 view 到同一块底层 buffer - 串行执行:prefill 和 decode 在同一 forward step 内串行执行,不会同时使用 workspace
- Buffer 不变:Lock 后底层
_current_workspaces[ubatch_id]的 tensor 对象不会被替换,data_ptr()恒定
8.4 Piecewise CUDA Graph(torch.compile)¶
Piecewise 模式下每一层是一个独立的小 graph,CUDAGraphWrapper 在每层 capture 时执行 self.runnable(*args, **kwargs),内部各层各自调用 get_simultaneous:
# CUDAGraphWrapper.__call__ 中的 capture 路径
with torch.cuda.graph(cudagraph, pool=self.graph_pool, ...):
output = self.runnable(*args, **kwargs)
# ↑ 内部会调 get_simultaneous → 返回的 view 的 data_ptr() 被录入 graph# CUDAGraphWrapper.__call__ 中的 capture 路径
with torch.cuda.graph(cudagraph, pool=self.graph_pool, ...):
output = self.runnable(*args, **kwargs)
# ↑ 内部会调 get_simultaneous → 返回的 view 的 data_ptr() 被录入 graph不同层的 capture 是串行的:同一个 forward pass 内依次 capture,workspace 的 data_ptr() 始终指向同一块 buffer。Replay 时也是逐层串行 replay,每层拿到的 workspace view 地址与 capture 时一致。
8.5 指针稳定性保证链总结¶
warmup 增长到 max capture 时无新分配 lock 冻结 replay 指针一致
───────────────── → ─────────────────── → ─────────── → ──────────────
buffer 从 None _ensure 走快路径 禁止扩容 data_ptr() 不变
增长到 N bytes 直接返回已有 tensor 违规即抛异常 graph replay 安全 warmup 增长到 max capture 时无新分配 lock 冻结 replay 指针一致
───────────────── → ─────────────────── → ─────────── → ──────────────
buffer 从 None _ensure 走快路径 禁止扩容 data_ptr() 不变
增长到 N bytes 直接返回已有 tensor 违规即抛异常 graph replay 安全| 阶段 | workspace 状态 | 是否可能分配新内存 | 指针是否稳定 |
|---|---|---|---|
| warmup(eager) | 未锁定,按需增长 | 是(可能多次扩容) | 不保证(可能变化) |
| capture | 未锁定,但 buffer 已足够大 | 否(走快路径) | 稳定 |
| lock | 锁定 | 否(违规抛异常) | 稳定 |
| replay(热路径) | 锁定 | 否(违规抛异常) | 稳定 |
9. 设计总结¶
| 设计原则 | 实现方式 | 解决的问题 |
|---|---|---|
| 预分配 + 复用 | 一块 uint8 buffer,所有模块通过 view 共享 | 热路径零 CUDA malloc,零碎片 |
| 按需增长 + Lock 冻结 | warmup 探测最大需求,lock 后禁止增长 | 确定性显存占用 + CUDA Graph 指针稳定性 |
| 先删后建 | 扩容时先 = None; del 再 torch.empty | 避免 resize_() 的峰值显存翻倍 |
| 256B 对齐 | round_up(actual, 256) | GPU 内存访问效率 |
| DBO 感知 | dbo_current_ubatch_id() + per-ubatch 槽位 | 双微批次临时数据互不干扰 |
| 调用者溯源 | inspect.currentframe() 回溯栈帧 | Lock 违规时精确定位问题模块 |
| 同步扩容 | 扩容时遍历所有 ubatch 槽位 | 保证各微批次缓冲区容量一致 |
| CUDA Graph 兼容 | warmup 先于 capture + lock 冻结指针 | capture 与 replay 的 data_ptr() 一致 |